 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSteer: Text-Guided Flow Matching in Activation Space for Versatile LLM Steering
May 28, 2026Activation-based control steers large language models (LLMs) by intervening on their internal representations during inference, and has emerged as an effective paradigm for controlling behaviors such as persona and style. However, existing methods often rely on fixed steering directions or task-specific intervention modules, making them difficult to adapt to fine-grained concepts and compositional constraints. We propose UniSteer, a text-guided activation flow matching model that learns a conditional distribution over residual-stream activations from natural-language conditions. Instead of fitting a separate intervention for each target behavior, UniSteer learns a universal conditional velocity field in activation space. At inference time, UniSteer performs flow inversion by partially transporting a source activation toward a latent state and regenerating it under a target textual condition before injecting it back into the frozen LLM. The same conditional model supports activation-space classification by selecting the textual label with the lowest reconstruction energy. Experiments on three target LLMs show that UniSteer provides a unified interface across behavioral control, truthfulness steering, fine-grained concept steering, multi-constraint instruction following, and activation-space classification.
KairosAgent: Agentic Time Series Forecasting with Fused Semantic Reasoning
May 28, 2026Cross-domain multimodal time series forecasting is a challenging task, requiring models to integrate precise numerical comprehension, cross-domain semantic understanding, and effective multimodal fusion. Existing approaches either build Time Series Foundation Models (TSFMs) from scratch or leverage pretrained Large Language Models (LLMs). However, TSFMs often overlook semantic understanding and lack the ability to perform future-oriented semantic reasoning, and LLMs struggle with numerical comprehension and accurate quantitative forecasting. To overcome these limitations, we propose KairosAgent, a novel agentic framework for multimodal time series forecasting, including an LLM-based reasoner and a TSFM-based forecaster. KairosAgent unifies textual reasoning and numerical forecasting by dynamically invoking analytical tools to enhance the numerical understanding and semantic reasoning capabilities of LLMs. The reasoning results are subsequently fused into the TSFM pipeline, enabling more accurate and reliable future predictions. To further improve the reasoning, we curate a large-scale corpus of high-quality trajectories, alongside a reinforcement learning from forecasting paradigm with multi-turn refinement and turn-level credit assignment. Experiments demonstrate that KairosAgent achieves superior zero-shot forecasting performance while maximizing the utility of pretrained LLMs and TSFMs, presenting a promising direction for efficient and interpretable time series agents. The project page is at https://foundation-model-research.github.io/KairosAgent .
What if Tomorrow is the World Cup Final? Counterfactual Time Series Forecasting with Textual Conditions
May 14, 2026Time series forecasting has become increasingly critical in real-world scenarios, where future sequences are influenced not only by historical patterns but also by forthcoming events. In this context, forecasting must dynamically adapt to complex and stochastic future conditions, which introduces fundamental challenges in both forecasting and evaluation. Traditional methods typically rely on historical data or factual future conditions, while overlooking counterfactual scenarios. Furthermore, many existing approaches are restricted to simple structured conditions, limiting their ability to generalize to the real-world complexities. To address these gaps, we introduce the task of counterfactual time series forecasting with textual conditions, enabling more flexible and condition-aware forecasting. We propose a comprehensive evaluation framework that encompasses both factual and counterfactual settings, even in the absence of ground truth time series. Additionally, we present a novel text-attribution mechanism that distinguishes mutable from immutable factors, thereby improving forecast accuracy under sophisticated and stochastic textual conditions. The project page is at https://seqml.github.io/TADiff/
Large Language Models Explore by Latent Distilling
Apr 27, 2026Generating diverse responses is crucial for test-time scaling of large language models (LLMs), yet standard stochastic sampling mostly yields surface-level lexical variation, limiting semantic exploration. In this paper, we propose Exploratory Sampling (ESamp), a decoding approach that explicitly encourages semantic diversity during generation. ESamp is motivated by the well-known observation that neural networks tend to make lower-error predictions on inputs similar to those encountered before, and incur higher prediction error on novel ones. Building on this property, we train a lightweight Distiller at test time to predict deep-layer hidden representations of the LLM from its shallow-layer representations to model the LLM's depth-wise representation transitions. During decoding, the Distiller continuously adapts to the mappings induced by the current generation context. ESamp uses the prediction error as a novelty signal to reweight candidate token extensions conditioned on the current prefix, thereby biasing decoding toward less-explored semantic patterns. ESamp is implemented with an asynchronous training--inference pipeline, with less than 5% worst case overhead (1.2% in the optimized release). Empirical results show that ESamp significantly boosts the Pass@k efficiency of reasoning models, showing superior or comparable performance to strong stochastic and heuristic baselines. Notably, ESamp achieves robust generalization across mathematics, science, and code generation benchmarks and breaks the trade-off between diversity and coherence in creative writing. Our code has released at: https://github.com/LinesHogan/tLLM.
Satellite-Free Training for Drone-View Geo-Localization
Apr 02, 2026Drone-view geo-localization (DVGL) aims to determine the location of drones in GPS-denied environments by retrieving the corresponding geotagged satellite tile from a reference gallery given UAV observations of a location. In many existing formulations, these observations are represented by a single oblique UAV image. In contrast, our satellite-free setting is designed for multi-view UAV sequences, which are used to construct a geometry-normalized UAV-side location representation before cross-view retrieval. Existing approaches rely on satellite imagery during training, either through paired supervision or unsupervised alignment, which limits practical deployment when satellite data are unavailable or restricted. In this paper, we propose a satellite-free training (SFT) framework that converts drone imagery into cross-view compatible representations through three main stages: drone-side 3D scene reconstruction, geometry-based pseudo-orthophoto generation, and satellite-free feature aggregation for retrieval. Specifically, we first reconstruct dense 3D scenes from multi-view drone images using 3D Gaussian splatting and project the reconstructed geometry into pseudo-orthophotos via PCA-guided orthographic projection. This rendering stage operates directly on reconstructed scene geometry without requiring camera parameters at rendering time. Next, we refine these orthophotos with lightweight geometry-guided inpainting to obtain texture-complete drone-side views. Finally, we extract DINOv3 patch features from the generated orthophotos, learn a Fisher vector aggregation model solely from drone data, and reuse it at test time to encode satellite tiles for cross-view retrieval. Experimental results on University-1652 and SUES-200 show that our SFT framework substantially outperforms satellite-free generalization baselines and narrows the gap to methods trained with satellite imagery.
ConTSG-Bench: A Unified Benchmark for Conditional Time Series Generation
Mar 05, 2026Conditional time series generation plays a critical role in addressing data scarcity and enabling causal analysis in real-world applications. Despite its increasing importance, the field lacks a standardized and systematic benchmarking framework for evaluating generative models across diverse conditions. To address this gap, we introduce the Conditional Time Series Generation Benchmark (ConTSG-Bench). ConTSG-Bench comprises a large-scale, well-aligned dataset spanning diverse conditioning modalities and levels of semantic abstraction, first enabling systematic evaluation of representative generation methods across these dimensions with a comprehensive suite of metrics for generation fidelity and condition adherence. Both the quantitative benchmarking and in-depth analyses of conditional generation behaviors have revealed the traits and limitations of the current approaches, highlighting critical challenges and promising research directions, particularly with respect to precise structural controllability and downstream task utility under complex conditions.
No Labels, No Look-Ahead: Unsupervised Online Video Stabilization with Classical Priors
Feb 26, 2026We propose a new unsupervised framework for online video stabilization. Unlike methods based on deep learning that require paired stable and unstable datasets, our approach instantiates the classical stabilization pipeline with three stages and incorporates a multithreaded buffering mechanism. This design addresses three longstanding challenges in end-to-end learning: limited data, poor controllability, and inefficiency on hardware with constrained resources. Existing benchmarks focus mainly on handheld videos with a forward view in visible light, which restricts the applicability of stabilization to domains such as UAV nighttime remote sensing. To fill this gap, we introduce a new multimodal UAV aerial video dataset (UAV-Test). Experiments show that our method consistently outperforms state-of-the-art online stabilizers in both quantitative metrics and visual quality, while achieving performance comparable to offline methods.
Interpreting and Controlling LLM Reasoning through Integrated Policy Gradient
Feb 03, 2026Large language models (LLMs) demonstrate strong reasoning abilities in solving complex real-world problems. Yet, the internal mechanisms driving these complex reasoning behaviors remain opaque. Existing interpretability approaches targeting reasoning either identify components (e.g., neurons) correlated with special textual patterns, or rely on human-annotated contrastive pairs to derive control vectors. Consequently, current methods struggle to precisely localize complex reasoning mechanisms or capture sequential influence from model internal workings to the reasoning outputs. In this paper, built on outcome-oriented and sequential-influence-aware principles, we focus on identifying components that have sequential contribution to reasoning behavior where outcomes are cumulated by long-range effects. We propose Integrated Policy Gradient (IPG), a novel framework that attributes reasoning behaviors to model's inner components by propagating compound outcome-based signals such as post reasoning accuracy backward through model inference trajectories. Empirical evaluations demonstrate that our approach achieves more precise localization and enables reliable modulation of reasoning behaviors (e.g., reasoning capability, reasoning strength) across diverse reasoning models.
Grad2Reward: From Sparse Judgment to Dense Rewards for Improving Open-Ended LLM Reasoning
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has catalyzed significant breakthroughs in complex LLM reasoning within verifiable domains, such as mathematics and programming. Recent efforts have sought to extend this paradigm to open-ended tasks by employing LLMs-as-a-Judge to provide sequence-level rewards for policy optimization. However, these rewards are inherently sparse, failing to provide the fine-grained supervision necessary for generating complex, long-form trajectories. Furthermore, current work treats the Judge as a black-box oracle, discarding the rich intermediate feedback signals encoded in it. To address these limitations, we introduce Grad2Reward, a novel framework that extracts dense process rewards directly from the Judge's model inference process via a single backward pass. By leveraging gradient-based attribution, Grad2Reward enables precise token-level credit assignment, substantially enhancing training efficiency and reasoning quality. Additionally, Grad2Reward introduces a self-judging mechanism, allowing the policy to improve through its own evaluative signals without training specialized reward models or reliance on superior external Judges. The experiments demonstrate that policies optimized with Grad2Reward achieve outstanding performance across diverse open-ended tasks, affirming its effectiveness and broad generalizability.
DiffusionUavLoc: Visually Prompted Diffusion for Cross-View UAV Localization
Nov 09, 2025


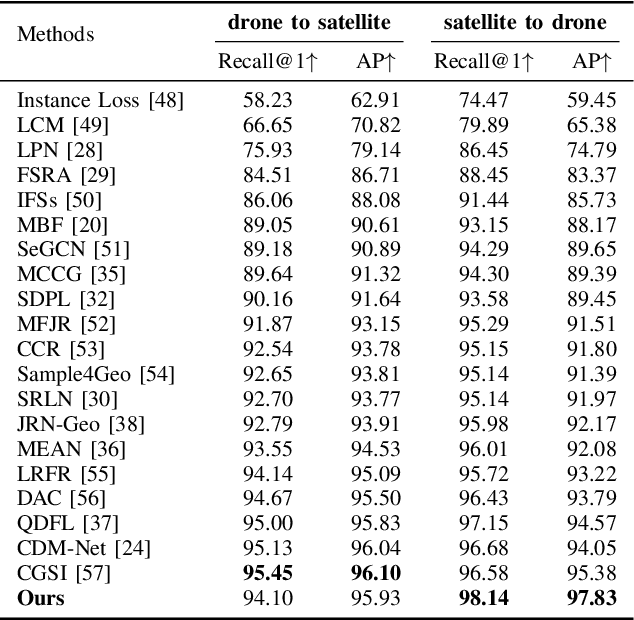
With the rapid growth of the low-altitude economy, unmanned aerial vehicles (UAVs) have become key platforms for measurement and tracking in intelligent patrol systems. However, in GNSS-denied environments, localization schemes that rely solely on satellite signals are prone to failure. Cross-view image retrieval-based localization is a promising alternative, yet substantial geometric and appearance domain gaps exist between oblique UAV views and nadir satellite orthophotos. Moreover, conventional approaches often depend on complex network architectures, text prompts, or large amounts of annotation, which hinders generalization. To address these issues, we propose DiffusionUavLoc, a cross-view localization framework that is image-prompted, text-free, diffusion-centric, and employs a VAE for unified representation. We first use training-free geometric rendering to synthesize pseudo-satellite images from UAV imagery as structural prompts. We then design a text-free conditional diffusion model that fuses multimodal structural cues to learn features robust to viewpoint changes. At inference, descriptors are computed at a fixed time step t and compared using cosine similarity. On University-1652 and SUES-200, the method performs competitively for cross-view localization, especially for satellite-to-drone in University-1652.Our data and code will be published at the following URL: https://github.com/liutao23/DiffusionUavLoc.git.