 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Data Science Agents
Paper and Code
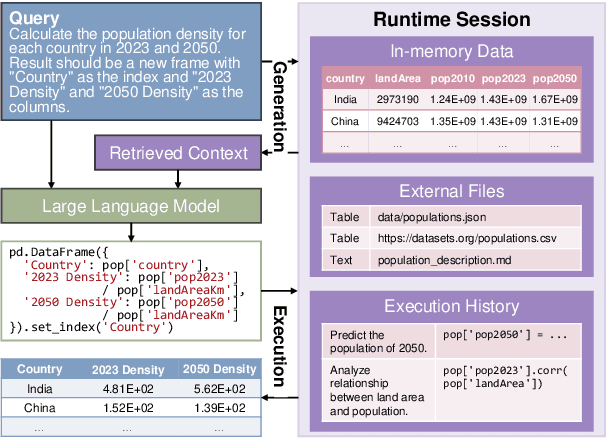
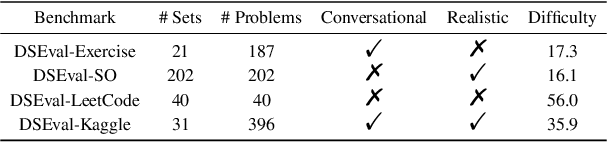


In the era of data-driven decision-making, the complexity of data analysis necessitates advanced expertise and tools of data science, presenting significant challenges even for specialists. Large Language Models (LLMs) have emerged as promising aids as data science agents, assisting humans in data analysis and processing. Yet their practical efficacy remains constrained by the varied demands of real-world applications and complicated analytical process. In this paper, we introduce DSEval -- a novel evaluation paradigm, as well as a series of innovative benchmarks tailored for assessing the performance of these agents throughout the entire data science lifecycle. Incorporating a novel bootstrapped annotation method, we streamline dataset preparation, improve the evaluation coverage, and expand benchmarking comprehensiveness. Our findings uncover prevalent obstacles and provide critical insights to inform future advancements in the field.