 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluGuard: Demystifying Data-Driven and Reasoning-Driven Hallucinations in LLMs
Jan 26, 2026The reliability of Large Language Models (LLMs) in high-stakes domains such as healthcare, law, and scientific discovery is often compromised by hallucinations. These failures typically stem from two sources: data-driven hallucinations and reasoning-driven hallucinations. However, existing detection methods usually address only one source and rely on task-specific heuristics, limiting their generalization to complex scenarios. To overcome these limitations, we introduce the Hallucination Risk Bound, a unified theoretical framework that formally decomposes hallucination risk into data-driven and reasoning-driven components, linked respectively to training-time mismatches and inference-time instabilities. This provides a principled foundation for analyzing how hallucinations emerge and evolve. Building on this foundation, we introduce HalluGuard, an NTK-based score that leverages the induced geometry and captured representations of the NTK to jointly identify data-driven and reasoning-driven hallucinations. We evaluate HalluGuard on 10 diverse benchmarks, 11 competitive baselines, and 9 popular LLM backbones, consistently achieving state-of-the-art performance in detecting diverse forms of LLM hallucinations.
Navigating Ideation Space: Decomposed Conceptual Representations for Positioning Scientific Ideas
Jan 13, 2026Scientific discovery is a cumulative process and requires new ideas to be situated within an ever-expanding landscape of existing knowledge. An emerging and critical challenge is how to identify conceptually relevant prior work from rapidly growing literature, and assess how a new idea differentiates from existing research. Current embedding approaches typically conflate distinct conceptual aspects into single representations and cannot support fine-grained literature retrieval; meanwhile, LLM-based evaluators are subject to sycophancy biases, failing to provide discriminative novelty assessment. To tackle these challenges, we introduce the Ideation Space, a structured representation that decomposes scientific knowledge into three distinct dimensions, i.e., research problem, methodology, and core findings, each learned through contrastive training. This framework enables principled measurement of conceptual distance between ideas, and modeling of ideation transitions that capture the logical connections within a proposed idea. Building upon this representation, we propose a Hierarchical Sub-Space Retrieval framework for efficient, targeted literature retrieval, and a Decomposed Novelty Assessment algorithm that identifies which aspects of an idea are novel. Extensive experiments demonstrate substantial improvements, where our approach achieves Recall@30 of 0.329 (16.7% over baselines), our ideation transition retrieval reaches Hit Rate@30 of 0.643, and novelty assessment attains 0.37 correlation with expert judgments. In summary, our work provides a promising paradigm for future research on accelerating and evaluating scientific discovery.
Data Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025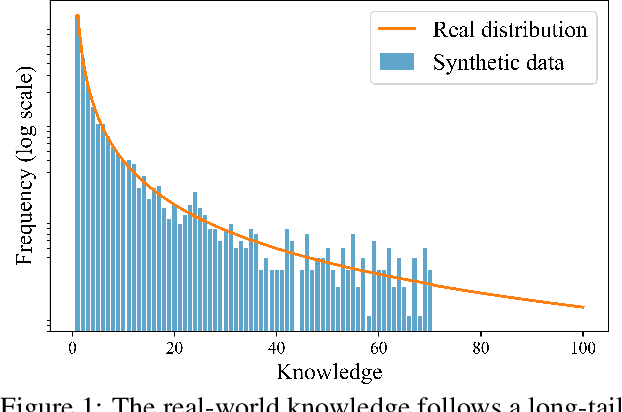
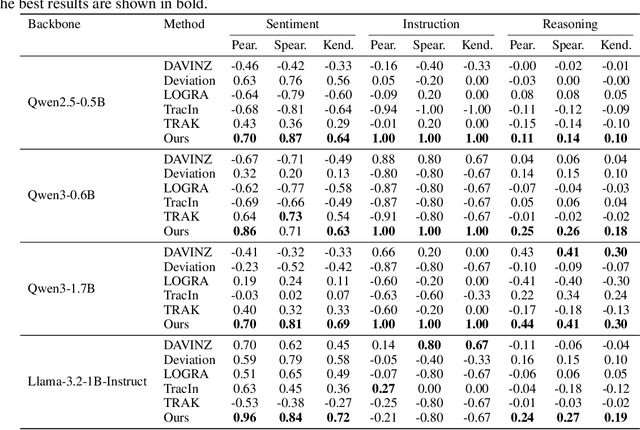
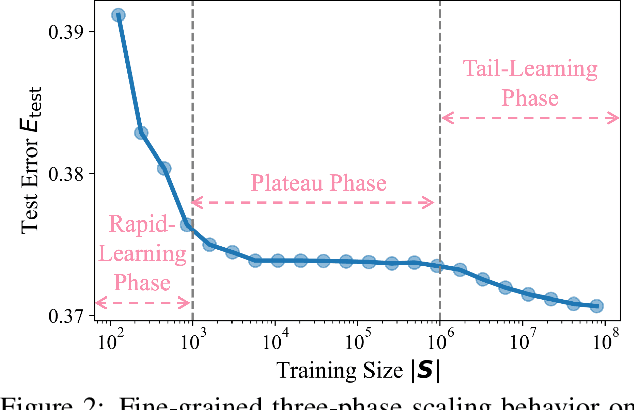
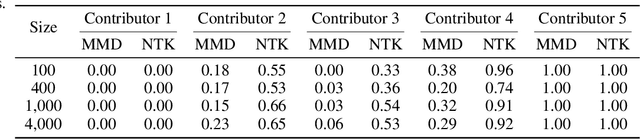
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
GENUINE: Graph Enhanced Multi-level Uncertainty Estimation for Large Language Models
Sep 09, 2025Uncertainty estimation is essential for enhancing the reliability of Large Language Models (LLMs), particularly in high-stakes applications. Existing methods often overlook semantic dependencies, relying on token-level probability measures that fail to capture structural relationships within the generated text. We propose GENUINE: Graph ENhanced mUlti-level uncertaINty Estimation for Large Language Models, a structure-aware framework that leverages dependency parse trees and hierarchical graph pooling to refine uncertainty quantification. By incorporating supervised learning, GENUINE effectively models semantic and structural relationships, improving confidence assessments. Extensive experiments across NLP tasks show that GENUINE achieves up to 29% higher AUROC than semantic entropy-based approaches and reduces calibration errors by over 15%, demonstrating the effectiveness of graph-based uncertainty modeling. The code is available at https://github.com/ODYSSEYWT/GUQ.
Non-exchangeable Conformal Prediction for Temporal Graph Neural Networks
Jul 02, 2025Conformal prediction for graph neural networks (GNNs) offers a promising framework for quantifying uncertainty, enhancing GNN reliability in high-stakes applications. However, existing methods predominantly focus on static graphs, neglecting the evolving nature of real-world graphs. Temporal dependencies in graph structure, node attributes, and ground truth labels violate the fundamental exchangeability assumption of standard conformal prediction methods, limiting their applicability. To address these challenges, in this paper, we introduce NCPNET, a novel end-to-end conformal prediction framework tailored for temporal graphs. Our approach extends conformal prediction to dynamic settings, mitigating statistical coverage violations induced by temporal dependencies. To achieve this, we propose a diffusion-based non-conformity score that captures both topological and temporal uncertainties within evolving networks. Additionally, we develop an efficiency-aware optimization algorithm that improves the conformal prediction process, enhancing computational efficiency and reducing coverage violations. Extensive experiments on diverse real-world temporal graphs, including WIKI, REDDIT, DBLP, and IBM Anti-Money Laundering dataset, demonstrate NCPNET's capability to ensure guaranteed coverage in temporal graphs, achieving up to a 31% reduction in prediction set size on the WIKI dataset, significantly improving efficiency compared to state-of-the-art methods. Our data and code are available at https://github.com/ODYSSEYWT/NCPNET.
Cross-Domain Conditional Diffusion Models for Time Series Imputation
Jun 14, 2025Cross-domain time series imputation is an underexplored data-centric research task that presents significant challenges, particularly when the target domain suffers from high missing rates and domain shifts in temporal dynamics. Existing time series imputation approaches primarily focus on the single-domain setting, which cannot effectively adapt to a new domain with domain shifts. Meanwhile, conventional domain adaptation techniques struggle with data incompleteness, as they typically assume the data from both source and target domains are fully observed to enable adaptation. For the problem of cross-domain time series imputation, missing values introduce high uncertainty that hinders distribution alignment, making existing adaptation strategies ineffective. Specifically, our proposed solution tackles this problem from three perspectives: (i) Data: We introduce a frequency-based time series interpolation strategy that integrates shared spectral components from both domains while retaining domain-specific temporal structures, constructing informative priors for imputation. (ii) Model: We design a diffusion-based imputation model that effectively learns domain-shared representations and captures domain-specific temporal dependencies with dedicated denoising networks. (iii) Algorithm: We further propose a cross-domain consistency alignment strategy that selectively regularizes output-level domain discrepancies, enabling effective knowledge transfer while preserving domain-specific characteristics. Extensive experiments on three real-world datasets demonstrate the superiority of our proposed approach. Our code implementation is available here.
EVINET: Towards Open-World Graph Learning via Evidential Reasoning Network
Jun 11, 2025Graph learning has been crucial to many real-world tasks, but they are often studied with a closed-world assumption, with all possible labels of data known a priori. To enable effective graph learning in an open and noisy environment, it is critical to inform the model users when the model makes a wrong prediction to in-distribution data of a known class, i.e., misclassification detection or when the model encounters out-of-distribution from novel classes, i.e., out-of-distribution detection. This paper introduces Evidential Reasoning Network (EVINET), a framework that addresses these two challenges by integrating Beta embedding within a subjective logic framework. EVINET includes two key modules: Dissonance Reasoning for misclassification detection and Vacuity Reasoning for out-of-distribution detection. Extensive experiments demonstrate that EVINET outperforms state-of-the-art methods across multiple metrics in the tasks of in-distribution classification, misclassification detection, and out-of-distribution detection. EVINET demonstrates the necessity of uncertainty estimation and logical reasoning for misclassification detection and out-of-distribution detection and paves the way for open-world graph learning. Our code and data are available at https://github.com/SSSKJ/EviNET.
EviNet: Evidential Reasoning Network for Resilient Graph Learning in the Open and Noisy Environments
Jun 08, 2025Graph learning has been crucial to many real-world tasks, but they are often studied with a closed-world assumption, with all possible labels of data known a priori. To enable effective graph learning in an open and noisy environment, it is critical to inform the model users when the model makes a wrong prediction to in-distribution data of a known class, i.e., misclassification detection or when the model encounters out-of-distribution from novel classes, i.e., out-of-distribution detection. This paper introduces Evidential Reasoning Network (EVINET), a framework that addresses these two challenges by integrating Beta embedding within a subjective logic framework. EVINET includes two key modules: Dissonance Reasoning for misclassification detection and Vacuity Reasoning for out-of-distribution detection. Extensive experiments demonstrate that EVINET outperforms state-of-the-art methods across multiple metrics in the tasks of in-distribution classification, misclassification detection, and out-of-distribution detection. EVINET demonstrates the necessity of uncertainty estimation and logical reasoning for misclassification detection and out-of-distribution detection and paves the way for open-world graph learning. Our code and data are available at https://github.com/SSSKJ/EviNET.
Towards Generalized Proactive Defense against Face Swappingwith Contour-Hybrid Watermark
May 25, 2025Face swapping, recognized as a privacy and security concern, has prompted considerable defensive research. With the advancements in AI-generated content, the discrepancies between the real and swapped faces have become nuanced. Considering the difficulty of forged traces detection, we shift the focus to the face swapping purpose and proactively embed elaborate watermarks against unknown face swapping techniques. Given that the constant purpose is to swap the original face identity while preserving the background, we concentrate on the regions surrounding the face to ensure robust watermark generation, while embedding the contour texture and face identity information to achieve progressive image determination. The watermark is located in the facial contour and contains hybrid messages, dubbed the contour-hybrid watermark (CMark). Our approach generalizes face swapping detection without requiring any swapping techniques during training and the storage of large-scale messages in advance. Experiments conducted across 8 face swapping techniques demonstrate the superiority of our approach compared with state-of-the-art passive and proactive detectors while achieving a favorable balance between the image quality and watermark robustness.
Plan and Budget: Effective and Efficient Test-Time Scaling on Large Language Model Reasoning
May 22, 2025



Large Language Models (LLMs) have achieved remarkable success in complex reasoning tasks, but their inference remains computationally inefficient. We observe a common failure mode in many prevalent LLMs, overthinking, where models generate verbose and tangential reasoning traces even for simple queries. Recent works have tried to mitigate this by enforcing fixed token budgets, however, this can lead to underthinking, especially on harder problems. Through empirical analysis, we identify that this inefficiency often stems from unclear problem-solving strategies. To formalize this, we develop a theoretical model, BBAM (Bayesian Budget Allocation Model), which models reasoning as a sequence of sub-questions with varying uncertainty, and introduce the $E^3$ metric to capture the trade-off between correctness and computation efficiency. Building on theoretical results from BBAM, we propose Plan-and-Budget, a model-agnostic, test-time framework that decomposes complex queries into sub-questions and allocates token budgets based on estimated complexity using adaptive scheduling. Plan-and-Budget improves reasoning efficiency across a range of tasks and models, achieving up to +70% accuracy gains, -39% token reduction, and +187.5% improvement in $E^3$. Notably, it elevates a smaller model (DS-Qwen-32B) to match the efficiency of a larger model (DS-LLaMA-70B)-demonstrating Plan-and-Budget's ability to close performance gaps without retraining. Our code is available at anonymous.4open.science/r/P-and-B-6513/.