 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Large Language Models Learn Concepts During Continual Pre-Training?
Jan 07, 2026Human beings primarily understand the world through concepts (e.g., dog), abstract mental representations that structure perception, reasoning, and learning. However, how large language models (LLMs) acquire, retain, and forget such concepts during continual pretraining remains poorly understood. In this work, we study how individual concepts are acquired and forgotten, as well as how multiple concepts interact through interference and synergy. We link these behavioral dynamics to LLMs' internal Concept Circuits, computational subgraphs associated with specific concepts, and incorporate Graph Metrics to characterize circuit structure. Our analysis reveals: (1) LLMs concept circuits provide a non-trivial, statistically significant signal of concept learning and forgetting; (2) Concept circuits exhibit a stage-wise temporal pattern during continual pretraining, with an early increase followed by gradual decrease and stabilization; (3) concepts with larger learning gains tend to exhibit greater forgetting under subsequent training; (4) semantically similar concepts induce stronger interference than weakly related ones; (5) conceptual knowledge differs in their transferability, with some significantly facilitating the learning of others. Together, our findings offer a circuit-level view of concept learning dynamics and inform the design of more interpretable and robust concept-aware training strategies for LLMs.
Scientific Hypothesis Generation and Validation: Methods, Datasets, and Future Directions
May 06, 2025Large Language Models (LLMs) are transforming scientific hypothesis generation and validation by enabling information synthesis, latent relationship discovery, and reasoning augmentation. This survey provides a structured overview of LLM-driven approaches, including symbolic frameworks, generative models, hybrid systems, and multi-agent architectures. We examine techniques such as retrieval-augmented generation, knowledge-graph completion, simulation, causal inference, and tool-assisted reasoning, highlighting trade-offs in interpretability, novelty, and domain alignment. We contrast early symbolic discovery systems (e.g., BACON, KEKADA) with modern LLM pipelines that leverage in-context learning and domain adaptation via fine-tuning, retrieval, and symbolic grounding. For validation, we review simulation, human-AI collaboration, causal modeling, and uncertainty quantification, emphasizing iterative assessment in open-world contexts. The survey maps datasets across biomedicine, materials science, environmental science, and social science, introducing new resources like AHTech and CSKG-600. Finally, we outline a roadmap emphasizing novelty-aware generation, multimodal-symbolic integration, human-in-the-loop systems, and ethical safeguards, positioning LLMs as agents for principled, scalable scientific discovery.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
Error-driven Data-efficient Large Multimodal Model Tuning
Dec 20, 2024



Large Multimodal Models (LMMs) have demonstrated impressive performance across numerous academic benchmarks. However, fine-tuning still remains essential to achieve satisfactory performance on downstream tasks, while the task-specific tuning samples are usually not readily available or expensive and time-consuming to obtain. To address this, we propose an error-driven data-efficient tuning framework that aims to efficiently adapt generic LMMs to newly emerging tasks without requiring any task-specific training samples. In our approach, a generic LMM, acting as a student model, is first evaluated on a small validation set of the target task, and then a more powerful model, acting as a teacher model, identifies the erroneous steps within the student model's reasoning steps and analyzes its capability gaps from fully addressing the target task. Based on these gaps, targeted training samples are further retrieved from existing task-agnostic datasets to tune the student model and tailor it to the target task. We perform extensive experiments across three different training data scales and seven tasks, demonstrating that our training paradigm significantly and efficiently improves LMM's performance on downstream tasks, achieving an average performance boost of 7.01%.
AMELI: Enhancing Multimodal Entity Linking with Fine-Grained Attributes
May 24, 2023



We propose attribute-aware multimodal entity linking, where the input is a mention described with a text and image, and the goal is to predict the corresponding target entity from a multimodal knowledge base (KB) where each entity is also described with a text description, a visual image and a set of attributes and values. To support this research, we construct AMELI, a large-scale dataset consisting of 18,472 reviews and 35,598 products. To establish baseline performance on AMELI, we experiment with the current state-of-the-art multimodal entity linking approaches and our enhanced attribute-aware model and demonstrate the importance of incorporating the attribute information into the entity linking process. To be best of our knowledge, we are the first to build benchmark dataset and solutions for the attribute-aware multimodal entity linking task. Datasets and codes will be made publicly available.
End-to-End Multimodal Fact-Checking and Explanation Generation: A Challenging Dataset and Models
May 25, 2022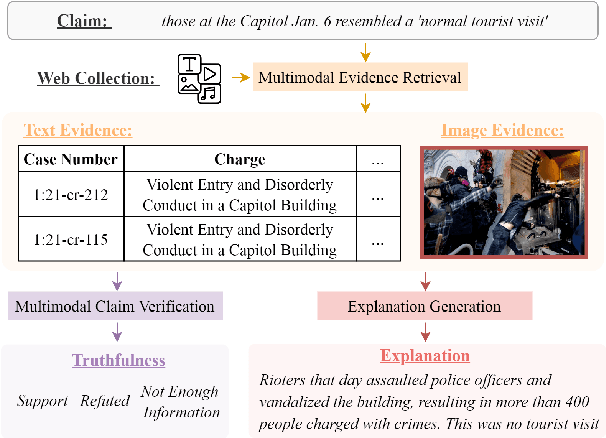
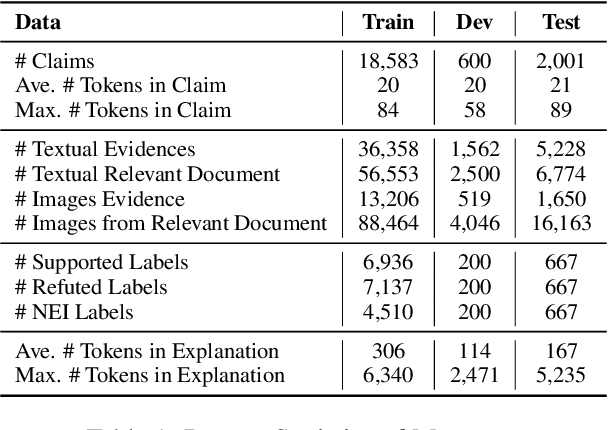
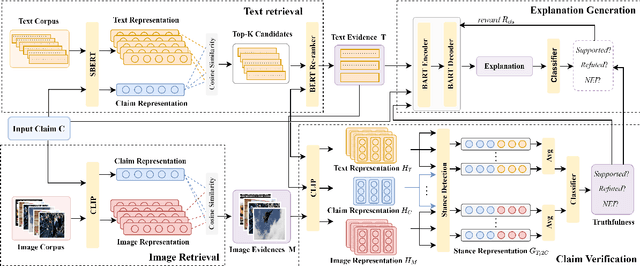
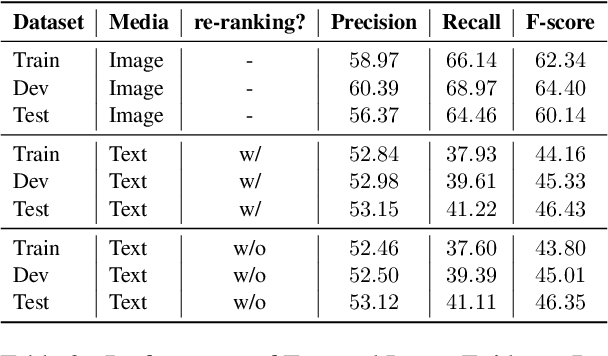
We propose the end-to-end multimodal fact-checking and explanation generation, where the input is a claim and a large collection of web sources, including articles, images, videos, and tweets, and the goal is to assess the truthfulness of the claim by retrieving relevant evidence and predicting a truthfulness label (i.e., support, refute and not enough information), and generate a rationalization statement to explain the reasoning and ruling process. To support this research, we construct Mocheg, a large-scale dataset that consists of 21,184 claims where each claim is assigned with a truthfulness label and ruling statement, with 58,523 evidence in the form of text and images. To establish baseline performances on Mocheg, we experiment with several state-of-the-art neural architectures on the three pipelined subtasks: multimodal evidence retrieval, claim verification, and explanation generation, and demonstrate the current state-of-the-art performance of end-to-end multimodal fact-checking is still far from satisfying. To the best of our knowledge, we are the first to build the benchmark dataset and solutions for end-to-end multimodal fact-checking and justification.