 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Hypothesis Generation and Validation: Methods, Datasets, and Future Directions
May 06, 2025Large Language Models (LLMs) are transforming scientific hypothesis generation and validation by enabling information synthesis, latent relationship discovery, and reasoning augmentation. This survey provides a structured overview of LLM-driven approaches, including symbolic frameworks, generative models, hybrid systems, and multi-agent architectures. We examine techniques such as retrieval-augmented generation, knowledge-graph completion, simulation, causal inference, and tool-assisted reasoning, highlighting trade-offs in interpretability, novelty, and domain alignment. We contrast early symbolic discovery systems (e.g., BACON, KEKADA) with modern LLM pipelines that leverage in-context learning and domain adaptation via fine-tuning, retrieval, and symbolic grounding. For validation, we review simulation, human-AI collaboration, causal modeling, and uncertainty quantification, emphasizing iterative assessment in open-world contexts. The survey maps datasets across biomedicine, materials science, environmental science, and social science, introducing new resources like AHTech and CSKG-600. Finally, we outline a roadmap emphasizing novelty-aware generation, multimodal-symbolic integration, human-in-the-loop systems, and ethical safeguards, positioning LLMs as agents for principled, scalable scientific discovery.
When Heterophily Meets Heterogeneity: New Graph Benchmarks and Effective Methods
Jul 15, 2024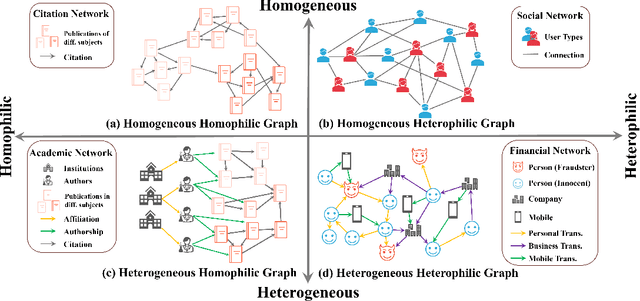
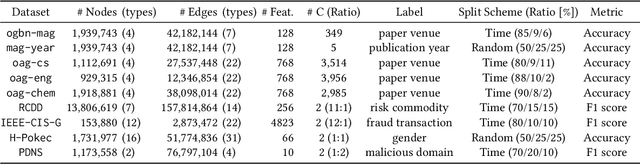
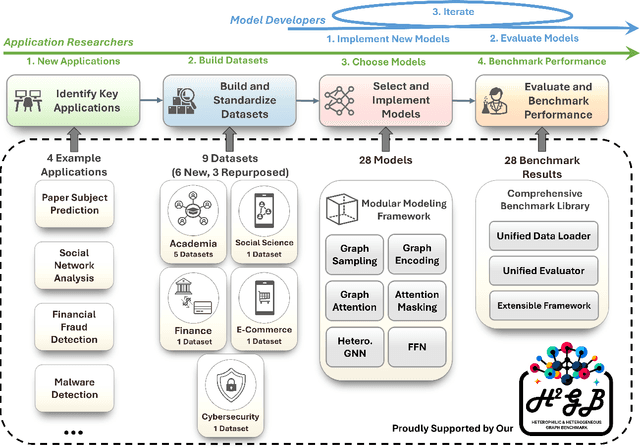
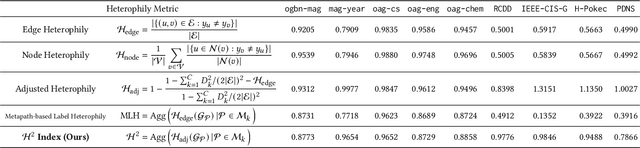
Many real-world graphs frequently present challenges for graph learning due to the presence of both heterophily and heterogeneity. However, existing benchmarks for graph learning often focus on heterogeneous graphs with homophily or homogeneous graphs with heterophily, leaving a gap in understanding how methods perform on graphs that are both heterogeneous and heterophilic. To bridge this gap, we introduce H2GB, a novel graph benchmark that brings together the complexities of both the heterophily and heterogeneity properties of graphs. Our benchmark encompasses 9 diverse real-world datasets across 5 domains, 28 baseline model implementations, and 26 benchmark results. In addition, we present a modular graph transformer framework UnifiedGT and a new model variant, H2G-former, that excels at this challenging benchmark. By integrating masked label embeddings, cross-type heterogeneous attention, and type-specific FFNs, H2G-former effectively tackles graph heterophily and heterogeneity. Extensive experiments across 26 baselines on H2GB reveal inadequacies of current models on heterogeneous heterophilic graph learning, and demonstrate the superiority of our H2G-former over existing solutions. Both the benchmark and the framework are available on GitHub (https://github.com/junhongmit/H2GB) and PyPI (https://pypi.org/project/H2GB), and documentation can be found at https://junhongmit.github.io/H2GB/.
GPatcher: A Simple and Adaptive MLP Model for Alleviating Graph Heterophily
Jun 25, 2023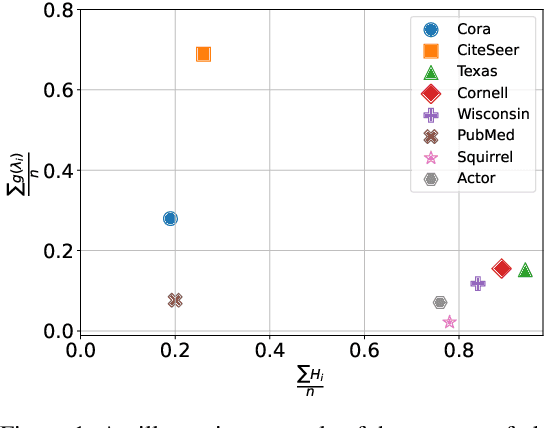
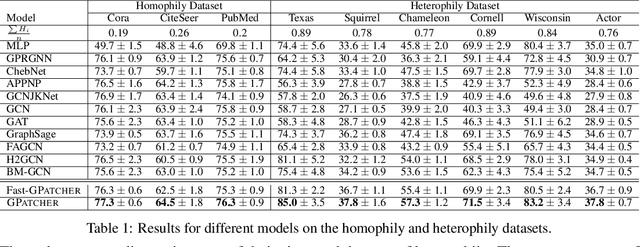
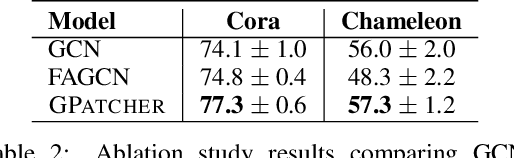
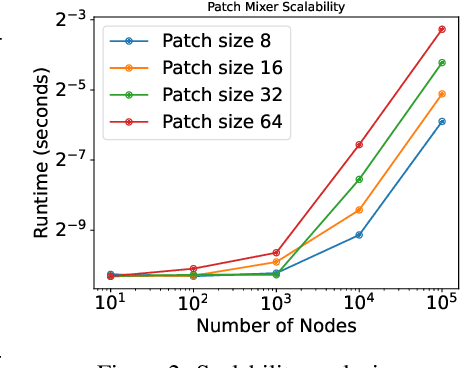
While graph heterophily has been extensively studied in recent years, a fundamental research question largely remains nascent: How and to what extent will graph heterophily affect the prediction performance of graph neural networks (GNNs)? In this paper, we aim to demystify the impact of graph heterophily on GNN spectral filters. Our theoretical results show that it is essential to design adaptive polynomial filters that adapts different degrees of graph heterophily to guarantee the generalization performance of GNNs. Inspired by our theoretical findings, we propose a simple yet powerful GNN named GPatcher by leveraging the MLP-Mixer architectures. Our approach comprises two main components: (1) an adaptive patch extractor function that automatically transforms each node's non-Euclidean graph representations to Euclidean patch representations given different degrees of heterophily, and (2) an efficient patch mixer function that learns salient node representation from both the local context information and the global positional information. Through extensive experiments, the GPatcher model demonstrates outstanding performance on node classification compared with popular homophily GNNs and state-of-the-art heterophily GNNs.
Personalized Federated Learning under Mixture of Distributions
May 01, 2023



The recent trend towards Personalized Federated Learning (PFL) has garnered significant attention as it allows for the training of models that are tailored to each client while maintaining data privacy. However, current PFL techniques primarily focus on modeling the conditional distribution heterogeneity (i.e. concept shift), which can result in suboptimal performance when the distribution of input data across clients diverges (i.e. covariate shift). Additionally, these techniques often lack the ability to adapt to unseen data, further limiting their effectiveness in real-world scenarios. To address these limitations, we propose a novel approach, FedGMM, which utilizes Gaussian mixture models (GMM) to effectively fit the input data distributions across diverse clients. The model parameters are estimated by maximum likelihood estimation utilizing a federated Expectation-Maximization algorithm, which is solved in closed form and does not assume gradient similarity. Furthermore, FedGMM possesses an additional advantage of adapting to new clients with minimal overhead, and it also enables uncertainty quantification. Empirical evaluations on synthetic and benchmark datasets demonstrate the superior performance of our method in both PFL classification and novel sample detection.
Extracting Temporal Event Relation with Syntactic-Guided Temporal Graph Transformer
Apr 19, 2021

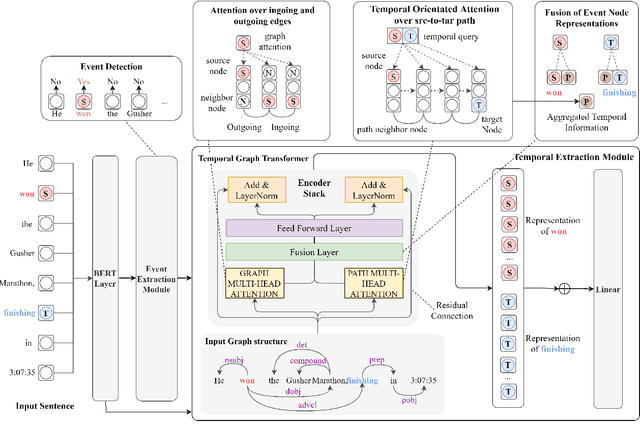
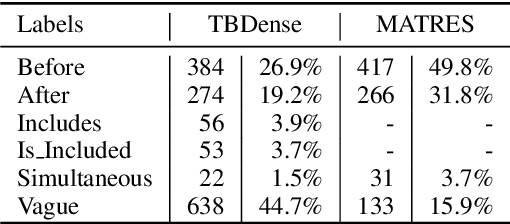
Extracting temporal relations (e.g., before, after, concurrent) among events is crucial to natural language understanding. Previous studies mainly rely on neural networks to learn effective features or manual-crafted linguistic features for temporal relation extraction, which usually fail when the context between two events is complex or wide. Inspired by the examination of available temporal relation annotations and human-like cognitive procedures, we propose a new Temporal Graph Transformer network to (1) explicitly find the connection between two events from a syntactic graph constructed from one or two continuous sentences, and (2) automatically locate the most indicative temporal cues from the path of the two event mentions as well as their surrounding concepts in the syntactic graph with a new temporal-oriented attention mechanism. Experiments on MATRES and TB-Dense datasets show that our approach significantly outperforms previous state-of-the-art methods on both end-to-end temporal relation extraction and temporal relation classification.
Bilingual Dictionary-based Language Model Pretraining for Neural Machine Translation
Mar 12, 2021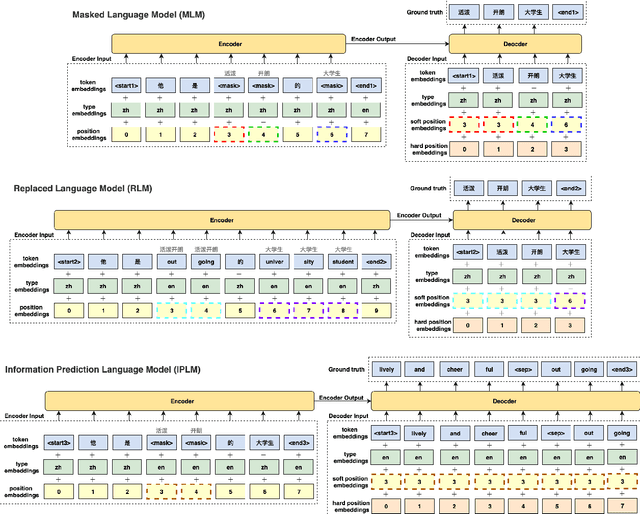
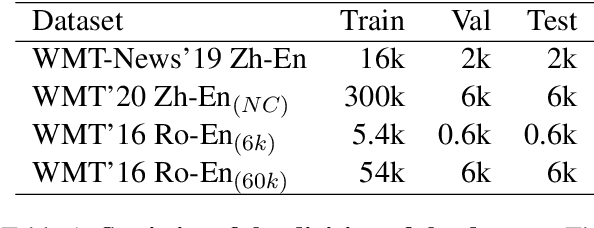

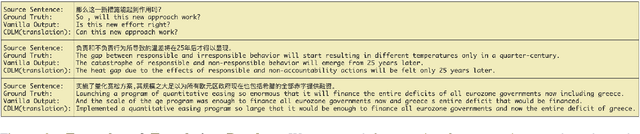
Recent studies have demonstrated a perceivable improvement on the performance of neural machine translation by applying cross-lingual language model pretraining (Lample and Conneau, 2019), especially the Translation Language Modeling (TLM). To alleviate the need for expensive parallel corpora by TLM, in this work, we incorporate the translation information from dictionaries into the pretraining process and propose a novel Bilingual Dictionary-based Language Model (BDLM). We evaluate our BDLM in Chinese, English, and Romanian. For Chinese-English, we obtained a 55.0 BLEU on WMT-News19 (Tiedemann, 2012) and a 24.3 BLEU on WMT20 news-commentary, outperforming the Vanilla Transformer (Vaswani et al., 2017) by more than 8.4 BLEU and 2.3 BLEU, respectively. According to our results, the BDLM also has advantages on convergence speed and predicting rare words. The increase in BLEU for WMT16 Romanian-English also shows its effectiveness in low-resources language translation.