 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Decomposition of Weights and Singular Value Low Rank Adaptation
May 21, 2025Parameter-Efficient Fine-Tuning (PEFT) has emerged as a critical paradigm for adapting Large Language Models (LLMs) to downstream tasks, among which Low-rank Adaptation (LoRA) represents one of the most widely adopted methodologies. However, existing LoRA-based approaches exhibit two fundamental limitations: unstable training dynamics and inefficient knowledge transfer from pre-trained models, both stemming from random initialization of adapter parameters. To overcome these challenges, we propose DuDe, a novel approach that decomposes weight matrices into magnitude and direction components, employing Singular Value Decomposition (SVD) for principled initialization. Our comprehensive evaluation demonstrates DuDe's superior performance and robustness, achieving up to 48.35\% accuracy on MMLU and 62.53\% ($\pm$ 1.59) accuracy on GSM8K. Our theoretical analysis and empirical validation collectively demonstrate that DuDe's decomposition strategy enhances optimization stability and better preserves pre-trained representations, particularly for domain-specific tasks requiring specialized knowledge. The combination of robust empirical performance and rigorous theoretical foundations establishes DuDe as a significant contribution to PEFT methodologies for LLMs.
OSoRA: Output-Dimension and Singular-Value Initialized Low-Rank Adaptation
May 21, 2025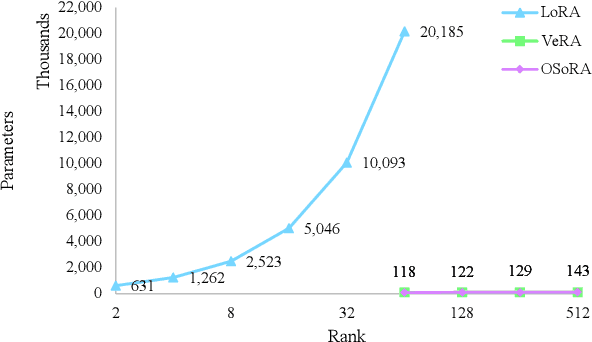
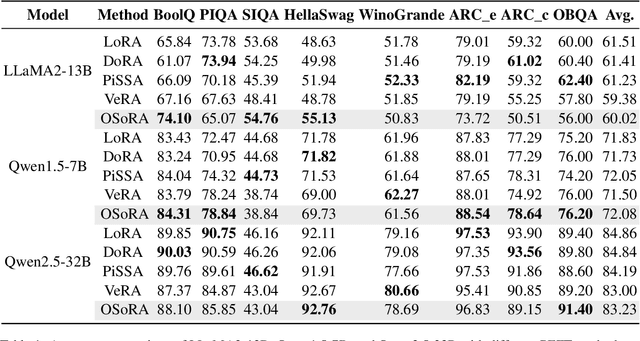
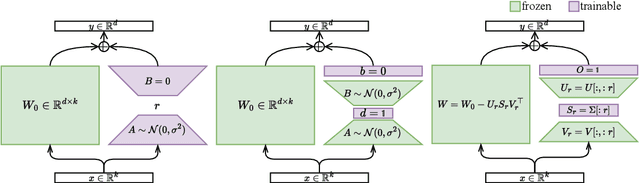
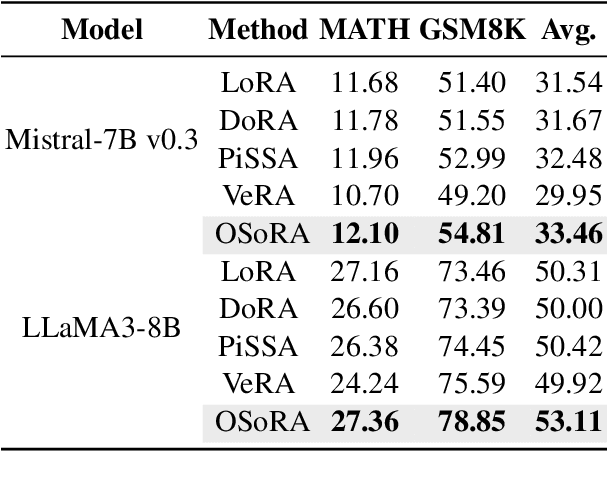
Fine-tuning Large Language Models (LLMs) has become increasingly challenging due to their massive scale and associated computational costs. Parameter-Efficient Fine-Tuning (PEFT) methodologies have been proposed as computational alternatives; however, their implementations still require significant resources. In this paper, we present OSoRA (Output-Dimension and Singular-Value Initialized Low-Rank Adaptation), a novel PEFT method for LLMs. OSoRA extends Low-Rank Adaptation (LoRA) by integrating Singular Value Decomposition (SVD) with learnable scaling vectors in a unified framework. It first performs an SVD of pre-trained weight matrices, then optimizes an output-dimension vector during training, while keeping the corresponding singular vector matrices frozen. OSoRA substantially reduces computational resource requirements by minimizing the number of trainable parameters during fine-tuning. Comprehensive evaluations across mathematical reasoning, common sense reasoning, and other benchmarks demonstrate that OSoRA achieves comparable or superior performance to state-of-the-art methods like LoRA and VeRA, while maintaining a linear parameter scaling even as the rank increases to higher dimensions. Our ablation studies further confirm that jointly training both the singular values and the output-dimension vector is critical for optimal performance.
Learning Graph Quantized Tokenizers for Transformers
Oct 17, 2024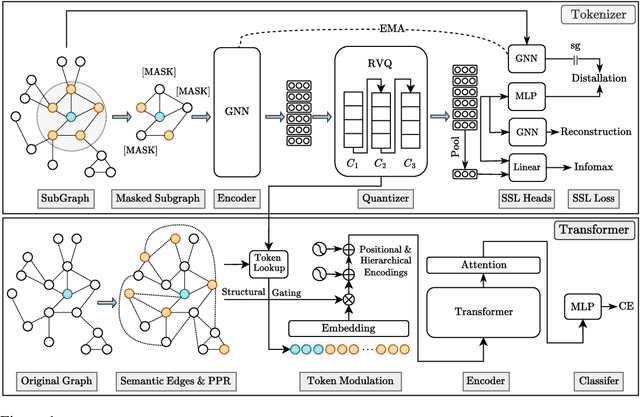
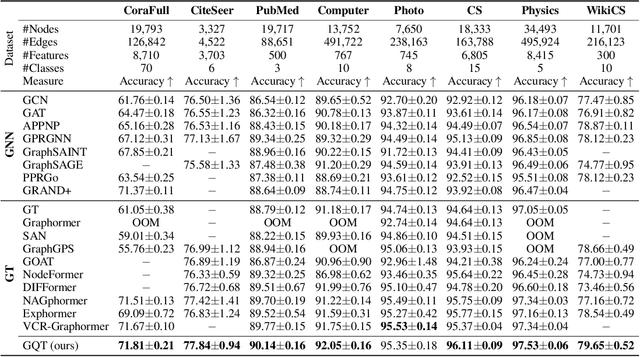
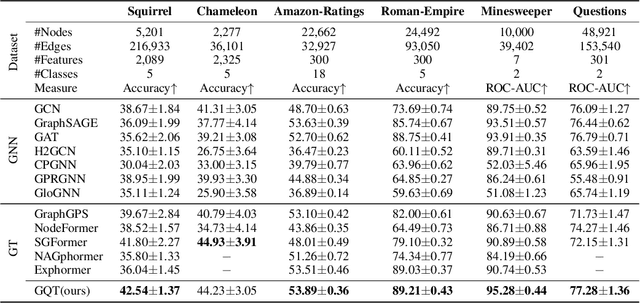
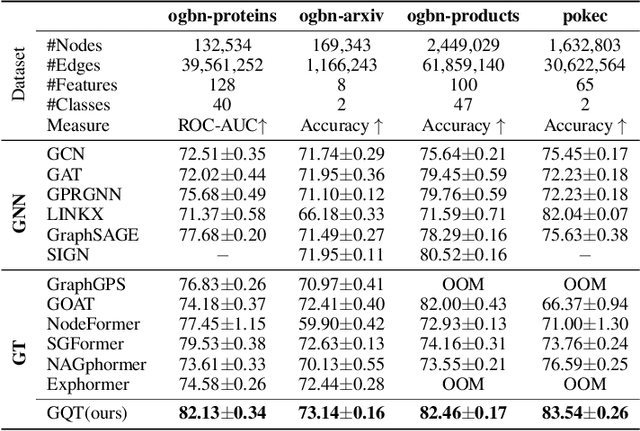
Transformers serve as the backbone architectures of Foundational Models, where a domain-specific tokenizer helps them adapt to various domains. Graph Transformers (GTs) have recently emerged as a leading model in geometric deep learning, outperforming Graph Neural Networks (GNNs) in various graph learning tasks. However, the development of tokenizers for graphs has lagged behind other modalities, with existing approaches relying on heuristics or GNNs co-trained with Transformers. To address this, we introduce GQT (\textbf{G}raph \textbf{Q}uantized \textbf{T}okenizer), which decouples tokenizer training from Transformer training by leveraging multi-task graph self-supervised learning, yielding robust and generalizable graph tokens. Furthermore, the GQT utilizes Residual Vector Quantization (RVQ) to learn hierarchical discrete tokens, resulting in significantly reduced memory requirements and improved generalization capabilities. By combining the GQT with token modulation, a Transformer encoder achieves state-of-the-art performance on 16 out of 18 benchmarks, including large-scale homophilic and heterophilic datasets. The code is available at: https://github.com/limei0307/graph-tokenizer
Language Models are Graph Learners
Oct 03, 2024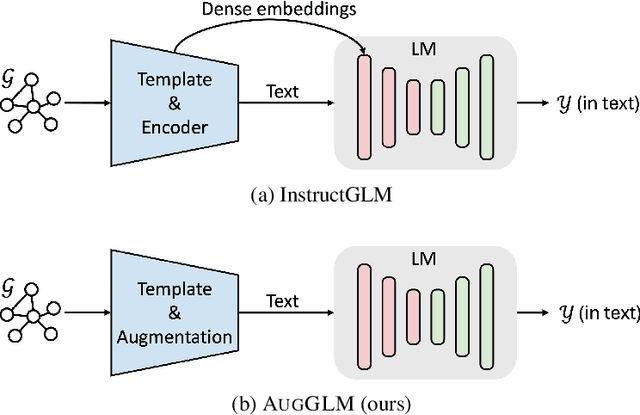

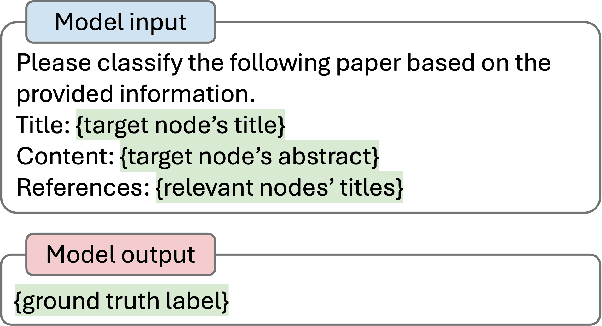
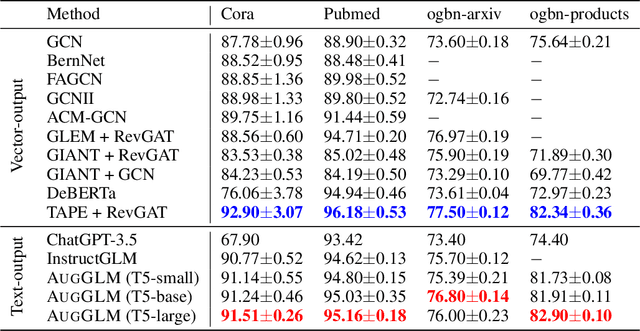
Language Models (LMs) are increasingly challenging the dominance of domain-specific models, including Graph Neural Networks (GNNs) and Graph Transformers (GTs), in graph learning tasks. Following this trend, we propose a novel approach that empowers off-the-shelf LMs to achieve performance comparable to state-of-the-art GNNs on node classification tasks, without requiring any architectural modification. By preserving the LM's original architecture, our approach retains a key benefit of LM instruction tuning: the ability to jointly train on diverse datasets, fostering greater flexibility and efficiency. To achieve this, we introduce two key augmentation strategies: (1) Enriching LMs' input using topological and semantic retrieval methods, which provide richer contextual information, and (2) guiding the LMs' classification process through a lightweight GNN classifier that effectively prunes class candidates. Our experiments on real-world datasets show that backbone Flan-T5 models equipped with these augmentation strategies outperform state-of-the-art text-output node classifiers and are comparable to top-performing vector-output node classifiers. By bridging the gap between specialized task-specific node classifiers and general LMs, this work paves the way for more versatile and widely applicable graph learning models. We will open-source the code upon publication.
VCR-Graphormer: A Mini-batch Graph Transformer via Virtual Connections
Mar 24, 2024



Graph transformer has been proven as an effective graph learning method for its adoption of attention mechanism that is capable of capturing expressive representations from complex topological and feature information of graphs. Graph transformer conventionally performs dense attention (or global attention) for every pair of nodes to learn node representation vectors, resulting in quadratic computational costs that are unaffordable for large-scale graph data. Therefore, mini-batch training for graph transformers is a promising direction, but limited samples in each mini-batch can not support effective dense attention to encode informative representations. Facing this bottleneck, (1) we start by assigning each node a token list that is sampled by personalized PageRank (PPR) and then apply standard multi-head self-attention only on this list to compute its node representations. This PPR tokenization method decouples model training from complex graph topological information and makes heavy feature engineering offline and independent, such that mini-batch training of graph transformers is possible by loading each node's token list in batches. We further prove this PPR tokenization is viable as a graph convolution network with a fixed polynomial filter and jumping knowledge. However, only using personalized PageRank may limit information carried by a token list, which could not support different graph inductive biases for model training. To this end, (2) we rewire graphs by introducing multiple types of virtual connections through structure- and content-based super nodes that enable PPR tokenization to encode local and global contexts, long-range interaction, and heterophilous information into each node's token list, and then formalize our Virtual Connection Ranking based Graph Transformer (VCR-Graphormer).
Quantifying Policy Administration Cost in an Active Learning Framework
Dec 29, 2023This paper proposes a computational model for policy administration. As an organization evolves, new users and resources are gradually placed under the mediation of the access control model. Each time such new entities are added, the policy administrator must deliberate on how the access control policy shall be revised to reflect the new reality. A well-designed access control model must anticipate such changes so that the administration cost does not become prohibitive when the organization scales up. Unfortunately, past Access Control research does not offer a formal way to quantify the cost of policy administration. In this work, we propose to model ongoing policy administration in an active learning framework. Administration cost can be quantified in terms of query complexity. We demonstrate the utility of this approach by applying it to the evolution of protection domains. We also modelled different policy administration strategies in our framework. This allowed us to formally demonstrate that domain-based policies have a cost advantage over access control matrices because of the use of heuristic reasoning when the policy evolves. To the best of our knowledge, this is the first work to employ an active learning framework to study the cost of policy deliberation and demonstrate the cost advantage of heuristic policy administration.
Empowering Working Memory for Large Language Model Agents
Dec 22, 2023Large language models (LLMs) have achieved impressive linguistic capabilities. However, a key limitation persists in their lack of human-like memory faculties. LLMs exhibit constrained memory retention across sequential interactions, hindering complex reasoning. This paper explores the potential of applying cognitive psychology's working memory frameworks, to enhance LLM architecture. The limitations of traditional LLM memory designs are analyzed, including their isolation of distinct dialog episodes and lack of persistent memory links. To address this, an innovative model is proposed incorporating a centralized Working Memory Hub and Episodic Buffer access to retain memories across episodes. This architecture aims to provide greater continuity for nuanced contextual reasoning during intricate tasks and collaborative scenarios. While promising, further research is required into optimizing episodic memory encoding, storage, prioritization, retrieval, and security. Overall, this paper provides a strategic blueprint for developing LLM agents with more sophisticated, human-like memory capabilities, highlighting memory mechanisms as a vital frontier in artificial general intelligence.
Hierarchical Multi-Marginal Optimal Transport for Network Alignment
Oct 06, 2023Finding node correspondence across networks, namely multi-network alignment, is an essential prerequisite for joint learning on multiple networks. Despite great success in aligning networks in pairs, the literature on multi-network alignment is sparse due to the exponentially growing solution space and lack of high-order discrepancy measures. To fill this gap, we propose a hierarchical multi-marginal optimal transport framework named HOT for multi-network alignment. To handle the large solution space, multiple networks are decomposed into smaller aligned clusters via the fused Gromov-Wasserstein (FGW) barycenter. To depict high-order relationships across multiple networks, the FGW distance is generalized to the multi-marginal setting, based on which networks can be aligned jointly. A fast proximal point method is further developed with guaranteed convergence to a local optimum. Extensive experiments and analysis show that our proposed HOT achieves significant improvements over the state-of-the-art in both effectiveness and scalability.
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Aug 16, 2023



We investigate various prompting strategies for enhancing personalized recommendation performance with large language models (LLMs) through input augmentation. Our proposed approach, termed LLM-Rec, encompasses four distinct prompting strategies: (1) basic prompting, (2) recommendation-driven prompting, (3) engagement-guided prompting, and (4) recommendation-driven + engagement-guided prompting. Our empirical experiments show that incorporating the augmented input text generated by LLM leads to improved recommendation performance. Recommendation-driven and engagement-guided prompting strategies are found to elicit LLM's understanding of global and local item characteristics. This finding highlights the importance of leveraging diverse prompts and input augmentation techniques to enhance the recommendation capabilities with LLMs.
GPatcher: A Simple and Adaptive MLP Model for Alleviating Graph Heterophily
Jun 25, 2023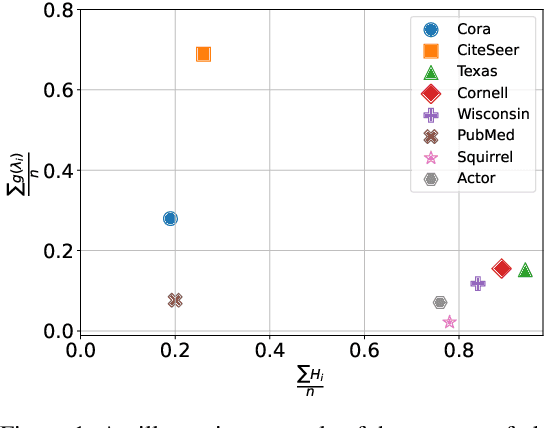
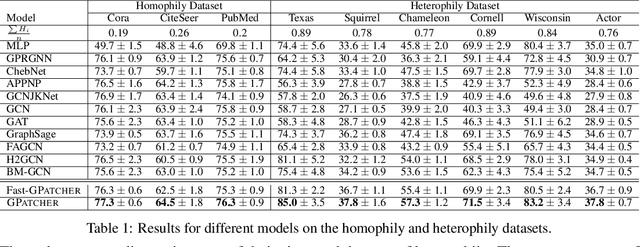
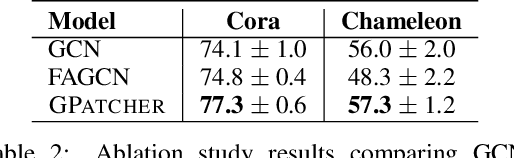
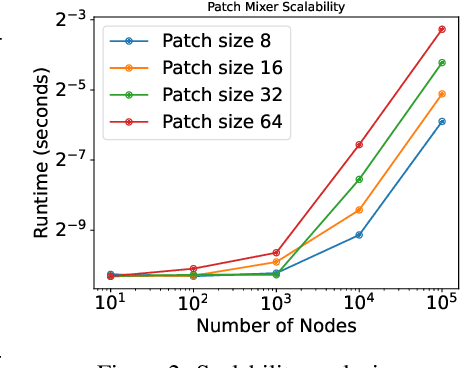
While graph heterophily has been extensively studied in recent years, a fundamental research question largely remains nascent: How and to what extent will graph heterophily affect the prediction performance of graph neural networks (GNNs)? In this paper, we aim to demystify the impact of graph heterophily on GNN spectral filters. Our theoretical results show that it is essential to design adaptive polynomial filters that adapts different degrees of graph heterophily to guarantee the generalization performance of GNNs. Inspired by our theoretical findings, we propose a simple yet powerful GNN named GPatcher by leveraging the MLP-Mixer architectures. Our approach comprises two main components: (1) an adaptive patch extractor function that automatically transforms each node's non-Euclidean graph representations to Euclidean patch representations given different degrees of heterophily, and (2) an efficient patch mixer function that learns salient node representation from both the local context information and the global positional information. Through extensive experiments, the GPatcher model demonstrates outstanding performance on node classification compared with popular homophily GNNs and state-of-the-art heterophily GNNs.