 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSoRA: Output-Dimension and Singular-Value Initialized Low-Rank Adaptation
May 21, 2025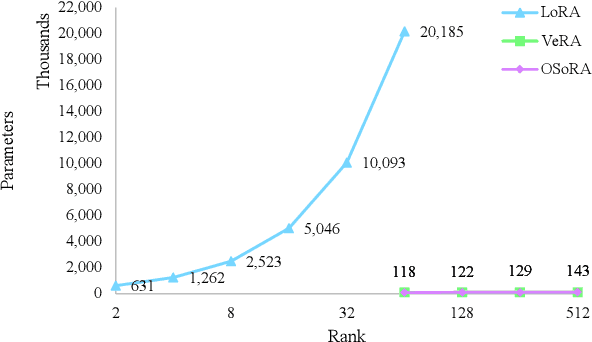
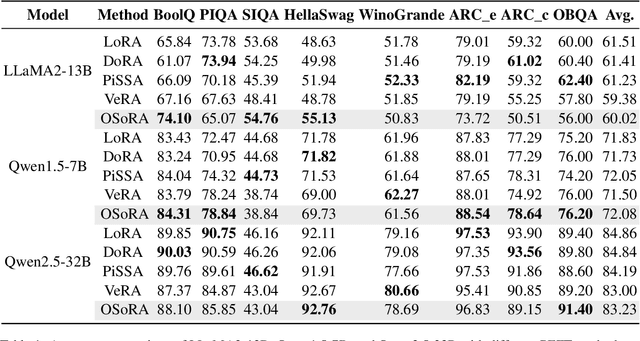
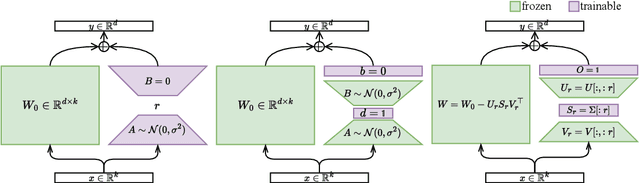
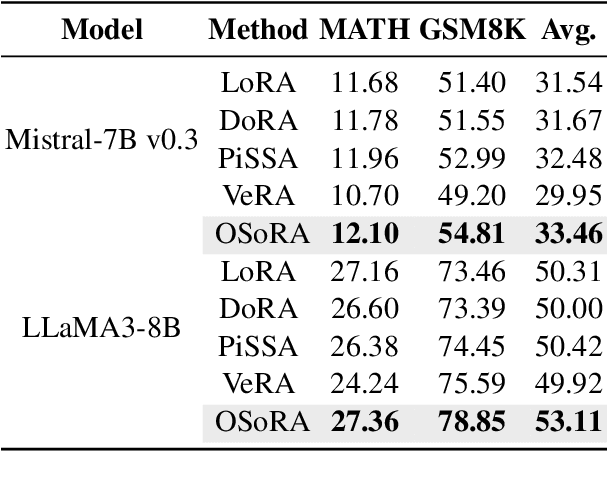
Fine-tuning Large Language Models (LLMs) has become increasingly challenging due to their massive scale and associated computational costs. Parameter-Efficient Fine-Tuning (PEFT) methodologies have been proposed as computational alternatives; however, their implementations still require significant resources. In this paper, we present OSoRA (Output-Dimension and Singular-Value Initialized Low-Rank Adaptation), a novel PEFT method for LLMs. OSoRA extends Low-Rank Adaptation (LoRA) by integrating Singular Value Decomposition (SVD) with learnable scaling vectors in a unified framework. It first performs an SVD of pre-trained weight matrices, then optimizes an output-dimension vector during training, while keeping the corresponding singular vector matrices frozen. OSoRA substantially reduces computational resource requirements by minimizing the number of trainable parameters during fine-tuning. Comprehensive evaluations across mathematical reasoning, common sense reasoning, and other benchmarks demonstrate that OSoRA achieves comparable or superior performance to state-of-the-art methods like LoRA and VeRA, while maintaining a linear parameter scaling even as the rank increases to higher dimensions. Our ablation studies further confirm that jointly training both the singular values and the output-dimension vector is critical for optimal performance.
Dual Decomposition of Weights and Singular Value Low Rank Adaptation
May 21, 2025Parameter-Efficient Fine-Tuning (PEFT) has emerged as a critical paradigm for adapting Large Language Models (LLMs) to downstream tasks, among which Low-rank Adaptation (LoRA) represents one of the most widely adopted methodologies. However, existing LoRA-based approaches exhibit two fundamental limitations: unstable training dynamics and inefficient knowledge transfer from pre-trained models, both stemming from random initialization of adapter parameters. To overcome these challenges, we propose DuDe, a novel approach that decomposes weight matrices into magnitude and direction components, employing Singular Value Decomposition (SVD) for principled initialization. Our comprehensive evaluation demonstrates DuDe's superior performance and robustness, achieving up to 48.35\% accuracy on MMLU and 62.53\% ($\pm$ 1.59) accuracy on GSM8K. Our theoretical analysis and empirical validation collectively demonstrate that DuDe's decomposition strategy enhances optimization stability and better preserves pre-trained representations, particularly for domain-specific tasks requiring specialized knowledge. The combination of robust empirical performance and rigorous theoretical foundations establishes DuDe as a significant contribution to PEFT methodologies for LLMs.
KEPLET: Knowledge-Enhanced Pretrained Language Model with Topic Entity Awareness
May 02, 2023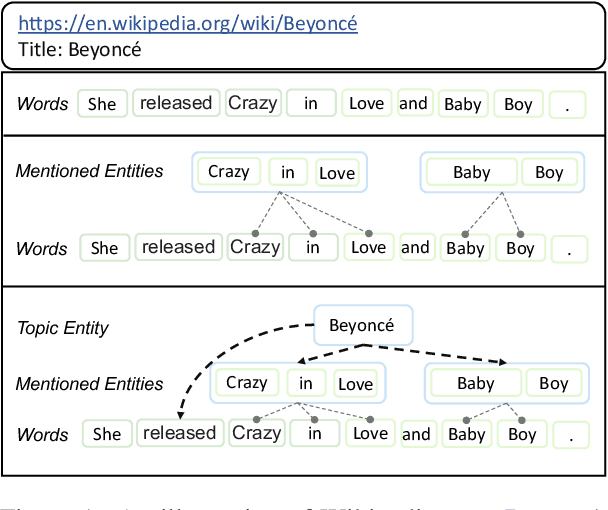
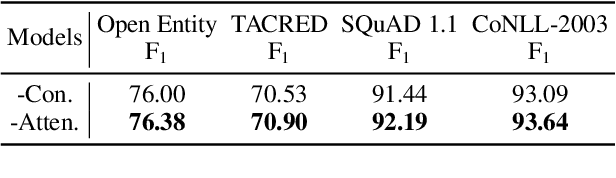
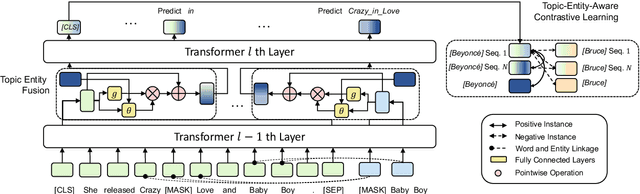
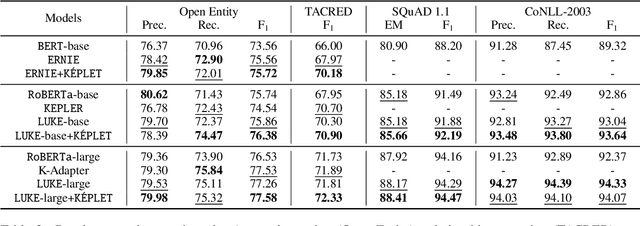
In recent years, Pre-trained Language Models (PLMs) have shown their superiority by pre-training on unstructured text corpus and then fine-tuning on downstream tasks. On entity-rich textual resources like Wikipedia, Knowledge-Enhanced PLMs (KEPLMs) incorporate the interactions between tokens and mentioned entities in pre-training, and are thus more effective on entity-centric tasks such as entity linking and relation classification. Although exploiting Wikipedia's rich structures to some extent, conventional KEPLMs still neglect a unique layout of the corpus where each Wikipedia page is around a topic entity (identified by the page URL and shown in the page title). In this paper, we demonstrate that KEPLMs without incorporating the topic entities will lead to insufficient entity interaction and biased (relation) word semantics. We thus propose KEPLET, a novel Knowledge-Enhanced Pre-trained LanguagE model with Topic entity awareness. In an end-to-end manner, KEPLET identifies where to add the topic entity's information in a Wikipedia sentence, fuses such information into token and mentioned entities representations, and supervises the network learning, through which it takes topic entities back into consideration. Experiments demonstrated the generality and superiority of KEPLET which was applied to two representative KEPLMs, achieving significant improvements on four entity-centric tasks.
CoRI: Collective Relation Integration with Data Augmentation for Open Information Extraction
Jun 01, 2021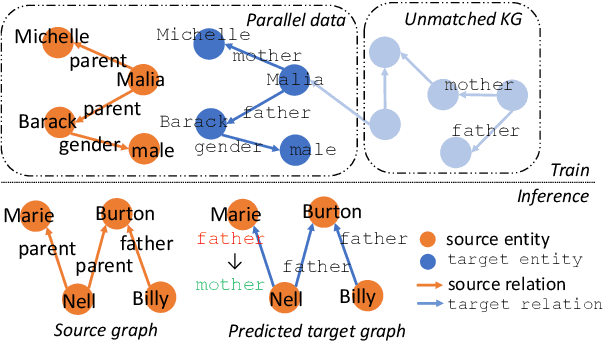
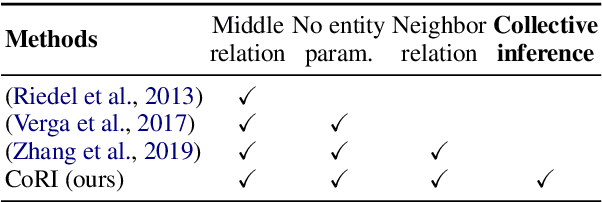
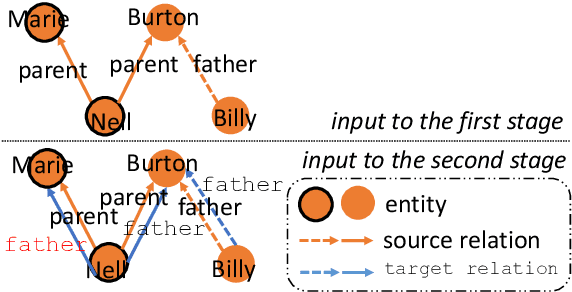
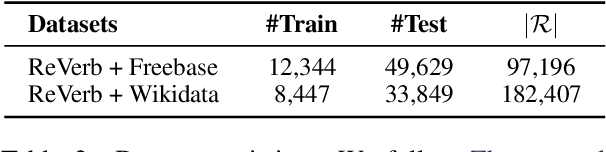
Integrating extracted knowledge from the Web to knowledge graphs (KGs) can facilitate tasks like question answering. We study relation integration that aims to align free-text relations in subject-relation-object extractions to relations in a target KG. To address the challenge that free-text relations are ambiguous, previous methods exploit neighbor entities and relations for additional context. However, the predictions are made independently, which can be mutually inconsistent. We propose a two-stage Collective Relation Integration (CoRI) model, where the first stage independently makes candidate predictions, and the second stage employs a collective model that accesses all candidate predictions to make globally coherent predictions. We further improve the collective model with augmented data from the portion of the target KG that is otherwise unused. Experiment results on two datasets show that CoRI can significantly outperform the baselines, improving AUC from .677 to .748 and from .716 to .780, respectively.
When Hearst Is not Enough: Improving Hypernymy Detection from Corpus with Distributional Models
Oct 10, 2020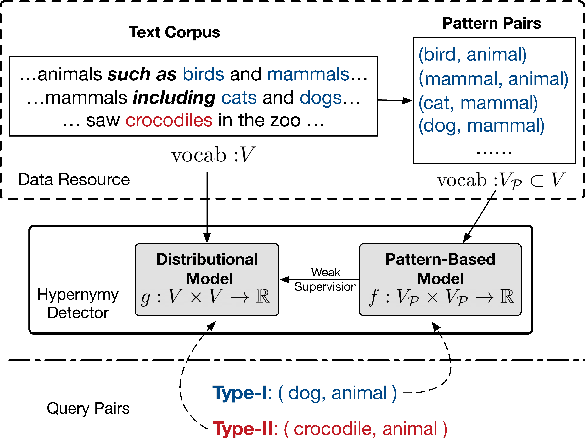
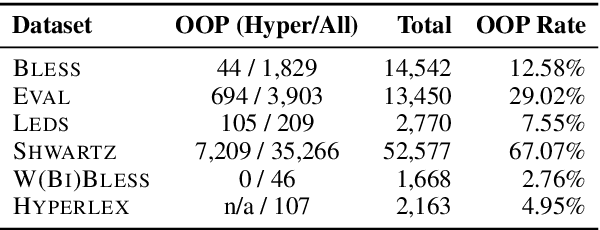
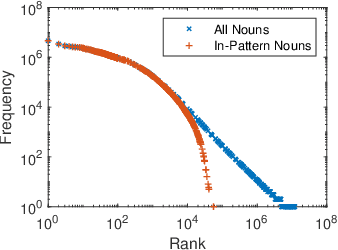
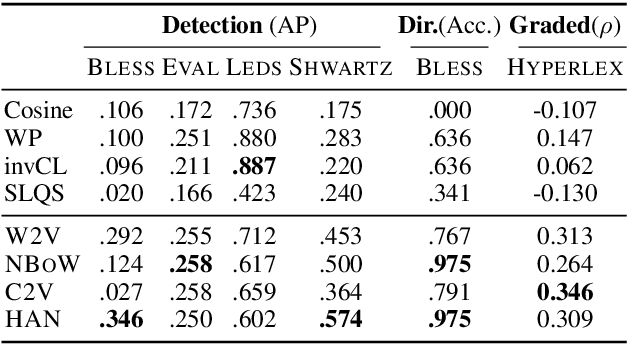
We address hypernymy detection, i.e., whether an is-a relationship exists between words (x, y), with the help of large textual corpora. Most conventional approaches to this task have been categorized to be either pattern-based or distributional. Recent studies suggest that pattern-based ones are superior, if large-scale Hearst pairs are extracted and fed, with the sparsity of unseen (x, y) pairs relieved. However, they become invalid in some specific sparsity cases, where x or y is not involved in any pattern. For the first time, this paper quantifies the non-negligible existence of those specific cases. We also demonstrate that distributional methods are ideal to make up for pattern-based ones in such cases. We devise a complementary framework, under which a pattern-based and a distributional model collaborate seamlessly in cases which they each prefer. On several benchmark datasets, our framework achieves competitive improvements and the case study shows its better interpretability.
CASE: Context-Aware Semantic Expansion
Dec 31, 2019
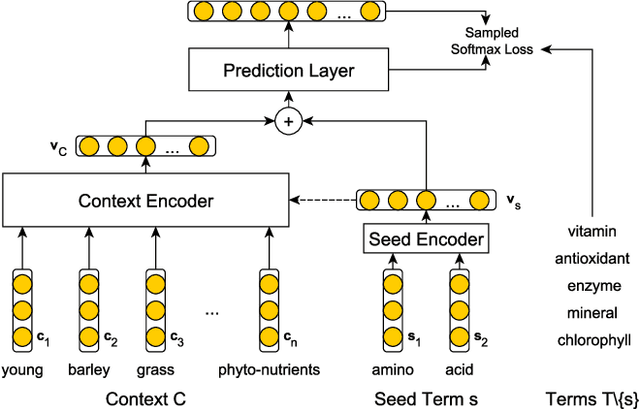
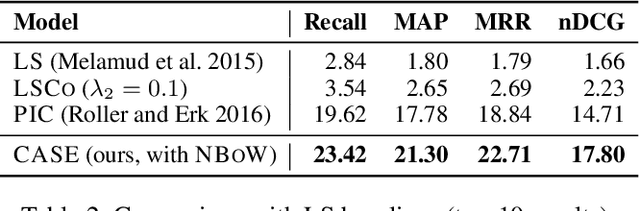
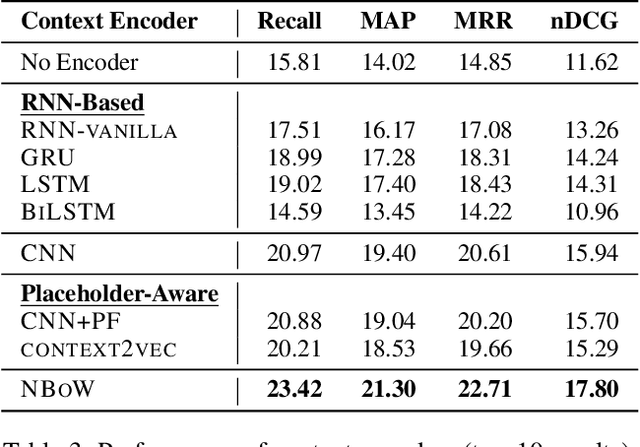
In this paper, we define and study a new task called Context-Aware Semantic Expansion (CASE). Given a seed term in a sentential context, we aim to suggest other terms that well fit the context as the seed. CASE has many interesting applications such as query suggestion, computer-assisted writing, and word sense disambiguation, to name a few. Previous explorations, if any, only involve some similar tasks, and all require human annotations for evaluation. In this study, we demonstrate that annotations for this task can be harvested at scale from existing corpora, in a fully automatic manner. On a dataset of 1.8 million sentences thus derived, we propose a network architecture that encodes the context and seed term separately before suggesting alternative terms. The context encoder in this architecture can be easily extended by incorporating seed-aware attention. Our experiments demonstrate that competitive results are achieved with appropriate choices of context encoder and attention scoring function.
Exploiting Multiple Embeddings for Chinese Named Entity Recognition
Aug 28, 2019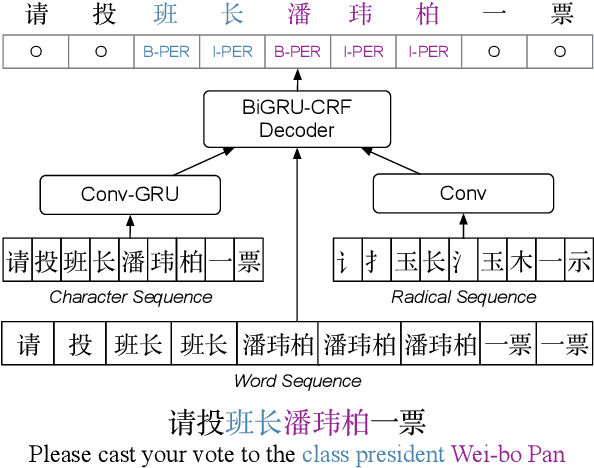
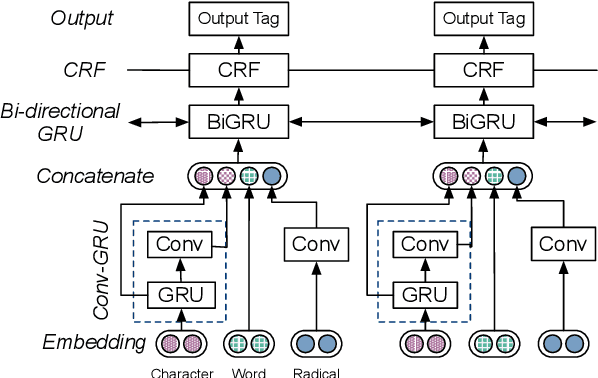
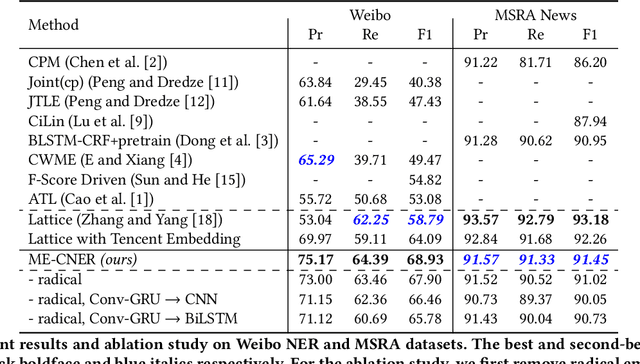
Identifying the named entities mentioned in text would enrich many semantic applications at the downstream level. However, due to the predominant usage of colloquial language in microblogs, the named entity recognition (NER) in Chinese microblogs experience significant performance deterioration, compared with performing NER in formal Chinese corpus. In this paper, we propose a simple yet effective neural framework to derive the character-level embeddings for NER in Chinese text, named ME-CNER. A character embedding is derived with rich semantic information harnessed at multiple granularities, ranging from radical, character to word levels. The experimental results demonstrate that the proposed approach achieves a large performance improvement on Weibo dataset and comparable performance on MSRA news dataset with lower computational cost against the existing state-of-the-art alternatives.
Logic Attention Based Neighborhood Aggregation for Inductive Knowledge Graph Embedding
Nov 04, 2018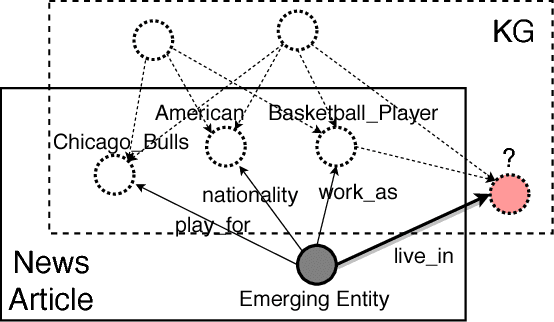
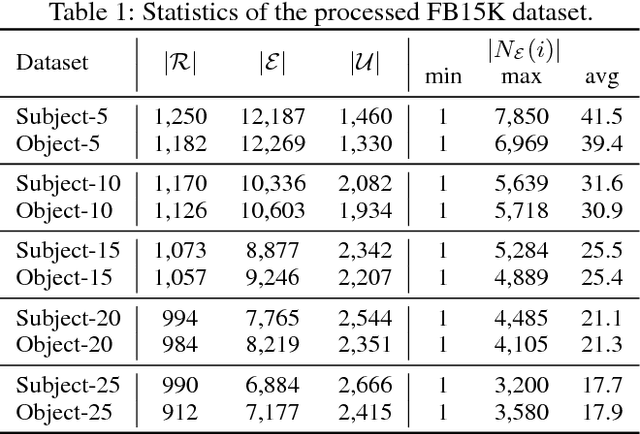
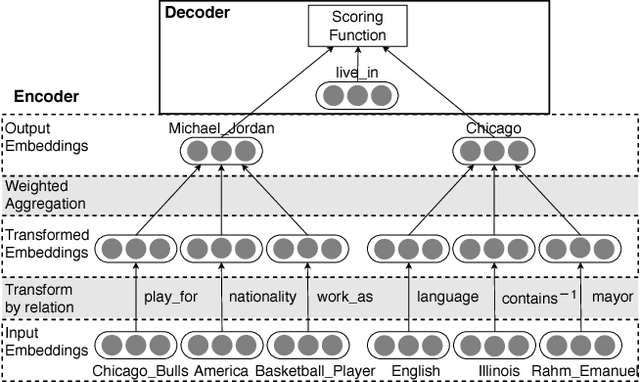
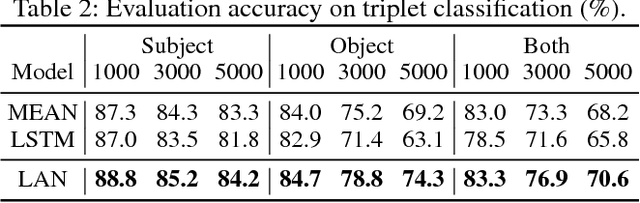
Knowledge graph embedding aims at modeling entities and relations with low-dimensional vectors. Most previous methods require that all entities should be seen during training, which is unpractical for real-world knowledge graphs with new entities emerging on a daily basis. Recent efforts on this issue suggest training a neighborhood aggregator in conjunction with the conventional entity and relation embeddings, which may help embed new entities inductively via their existing neighbors. However, their neighborhood aggregators neglect the unordered and unequal natures of an entity's neighbors. To this end, we summarize the desired properties that may lead to effective neighborhood aggregators. We also introduce a novel aggregator, namely, Logic Attention Network (LAN), which addresses the properties by aggregating neighbors with both rules- and network-based attention weights. By comparing with conventional aggregators on two knowledge graph completion tasks, we experimentally validate LAN's superiority in terms of the desired properties.
Pair-Linking for Collective Entity Disambiguation: Two Could Be Better Than All
Jul 16, 2018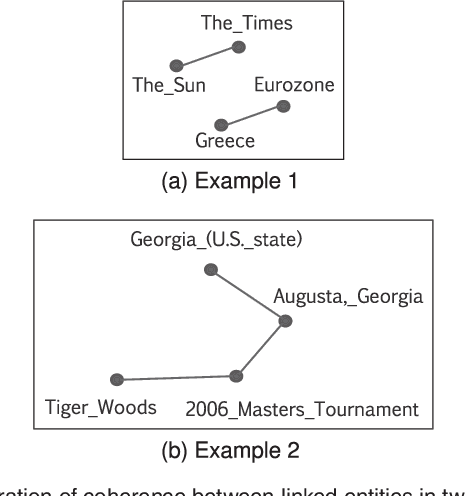

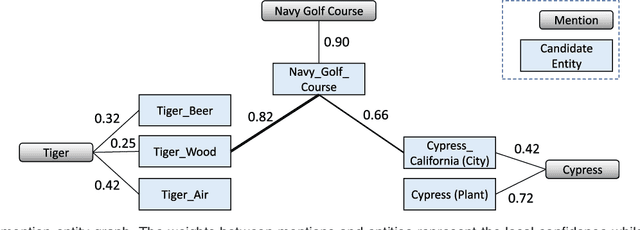
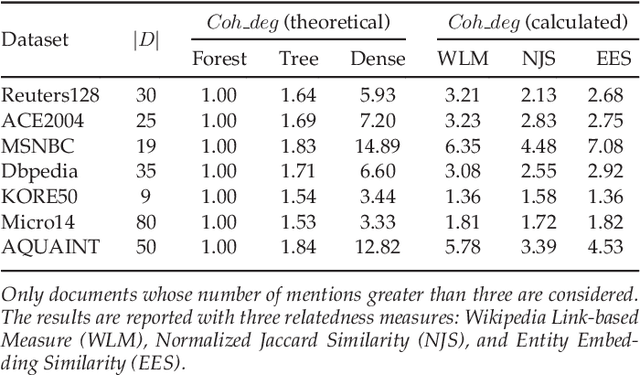
Collective entity disambiguation aims to jointly resolve multiple mentions by linking them to their associated entities in a knowledge base. Previous works are primarily based on the underlying assumption that entities within the same document are highly related. However, the extend to which these mentioned entities are actually connected in reality is rarely studied and therefore raises interesting research questions. For the first time, we show that the semantic relationships between the mentioned entities are in fact less dense than expected. This could be attributed to several reasons such as noise, data sparsity and knowledge base incompleteness. As a remedy, we introduce MINTREE, a new tree-based objective for the entity disambiguation problem. The key intuition behind MINTREE is the concept of coherence relaxation which utilizes the weight of a minimum spanning tree to measure the coherence between entities. Based on this new objective, we design a novel entity disambiguation algorithms which we call Pair-Linking. Instead of considering all the given mentions, Pair-Linking iteratively selects a pair with the highest confidence at each step for decision making. Via extensive experiments, we show that our approach is not only more accurate but also surprisingly faster than many state-of-the-art collective linking algorithms.
hyperdoc2vec: Distributed Representations of Hypertext Documents
May 10, 2018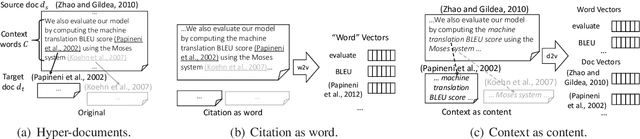

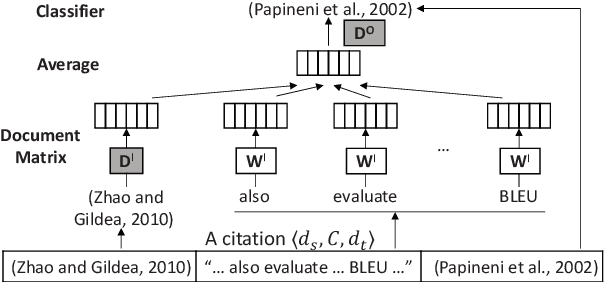
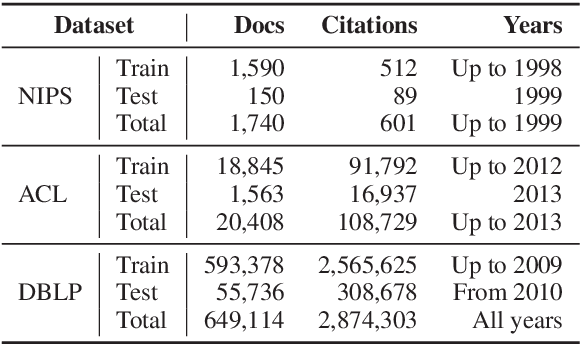
Hypertext documents, such as web pages and academic papers, are of great importance in delivering information in our daily life. Although being effective on plain documents, conventional text embedding methods suffer from information loss if directly adapted to hyper-documents. In this paper, we propose a general embedding approach for hyper-documents, namely, hyperdoc2vec, along with four criteria characterizing necessary information that hyper-document embedding models should preserve. Systematic comparisons are conducted between hyperdoc2vec and several competitors on two tasks, i.e., paper classification and citation recommendation, in the academic paper domain. Analyses and experiments both validate the superiority of hyperdoc2vec to other models w.r.t. the four criteria.