 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives
May 26, 2019
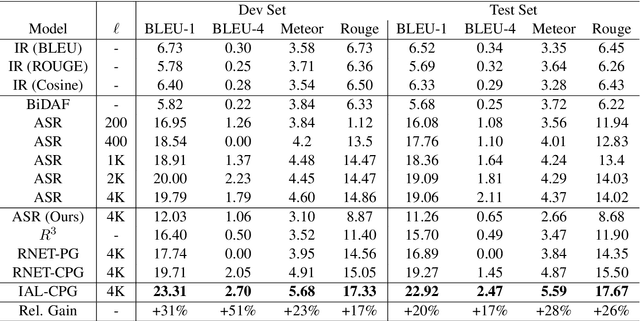
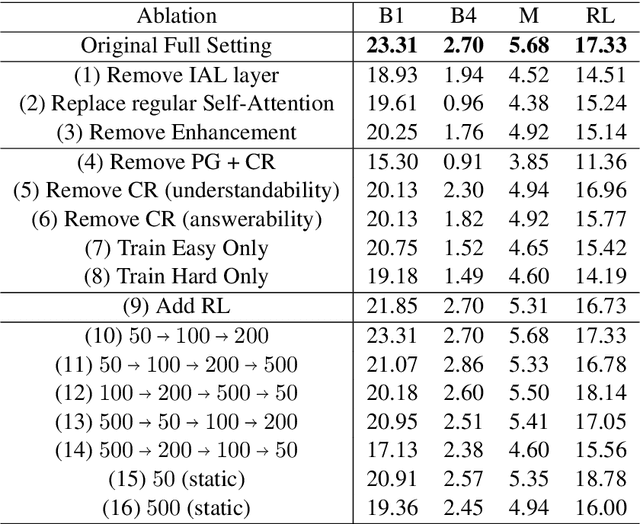

This paper tackles the problem of reading comprehension over long narratives where documents easily span over thousands of tokens. We propose a curriculum learning (CL) based Pointer-Generator framework for reading/sampling over large documents, enabling diverse training of the neural model based on the notion of alternating contextual difficulty. This can be interpreted as a form of domain randomization and/or generative pretraining during training. To this end, the usage of the Pointer-Generator softens the requirement of having the answer within the context, enabling us to construct diverse training samples for learning. Additionally, we propose a new Introspective Alignment Layer (IAL), which reasons over decomposed alignments using block-based self-attention. We evaluate our proposed method on the NarrativeQA reading comprehension benchmark, achieving state-of-the-art performance, improving existing baselines by $51\%$ relative improvement on BLEU-4 and $17\%$ relative improvement on Rouge-L. Extensive ablations confirm the effectiveness of our proposed IAL and CL components.
Pair-Linking for Collective Entity Disambiguation: Two Could Be Better Than All
Jul 16, 2018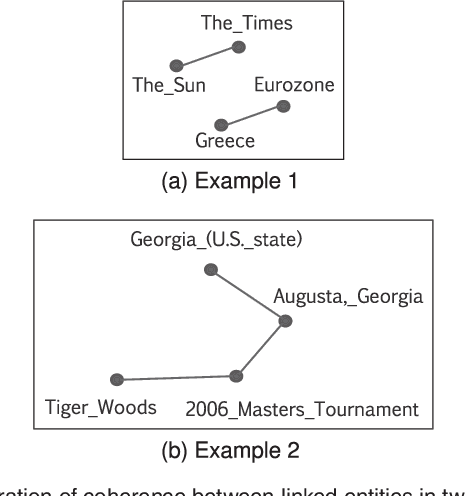

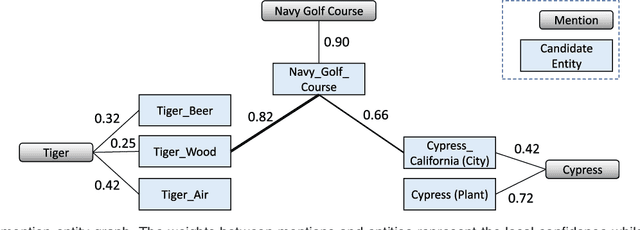
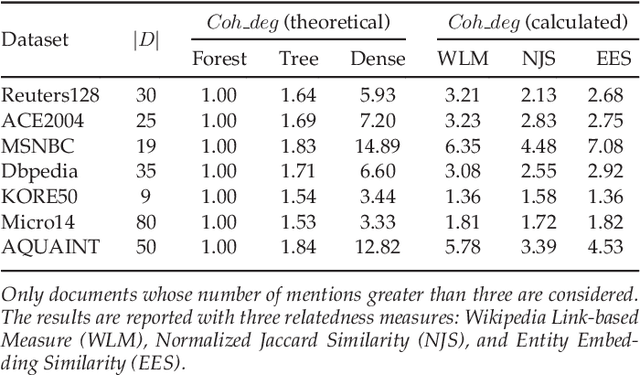
Collective entity disambiguation aims to jointly resolve multiple mentions by linking them to their associated entities in a knowledge base. Previous works are primarily based on the underlying assumption that entities within the same document are highly related. However, the extend to which these mentioned entities are actually connected in reality is rarely studied and therefore raises interesting research questions. For the first time, we show that the semantic relationships between the mentioned entities are in fact less dense than expected. This could be attributed to several reasons such as noise, data sparsity and knowledge base incompleteness. As a remedy, we introduce MINTREE, a new tree-based objective for the entity disambiguation problem. The key intuition behind MINTREE is the concept of coherence relaxation which utilizes the weight of a minimum spanning tree to measure the coherence between entities. Based on this new objective, we design a novel entity disambiguation algorithms which we call Pair-Linking. Instead of considering all the given mentions, Pair-Linking iteratively selects a pair with the highest confidence at each step for decision making. Via extensive experiments, we show that our approach is not only more accurate but also surprisingly faster than many state-of-the-art collective linking algorithms.
SkipFlow: Incorporating Neural Coherence Features for End-to-End Automatic Text Scoring
Nov 14, 2017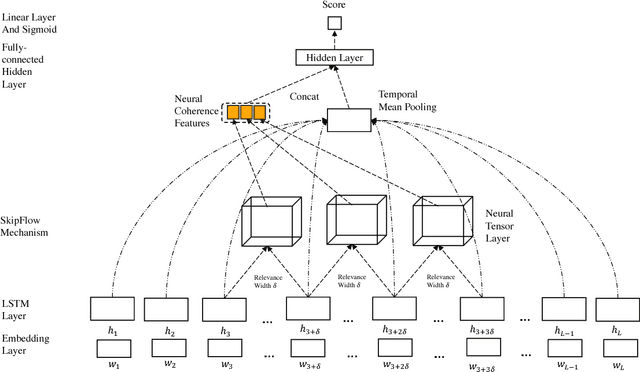


Deep learning has demonstrated tremendous potential for Automatic Text Scoring (ATS) tasks. In this paper, we describe a new neural architecture that enhances vanilla neural network models with auxiliary neural coherence features. Our new method proposes a new \textsc{SkipFlow} mechanism that models relationships between snapshots of the hidden representations of a long short-term memory (LSTM) network as it reads. Subsequently, the semantic relationships between multiple snapshots are used as auxiliary features for prediction. This has two main benefits. Firstly, essays are typically long sequences and therefore the memorization capability of the LSTM network may be insufficient. Implicit access to multiple snapshots can alleviate this problem by acting as a protection against vanishing gradients. The parameters of the \textsc{SkipFlow} mechanism also acts as an auxiliary memory. Secondly, modeling relationships between multiple positions allows our model to learn features that represent and approximate textual coherence. In our model, we call this \textit{neural coherence} features. Overall, we present a unified deep learning architecture that generates neural coherence features as it reads in an end-to-end fashion. Our approach demonstrates state-of-the-art performance on the benchmark ASAP dataset, outperforming not only feature engineering baselines but also other deep learning models.
Multi-task Neural Network for Non-discrete Attribute Prediction in Knowledge Graphs
Aug 16, 2017


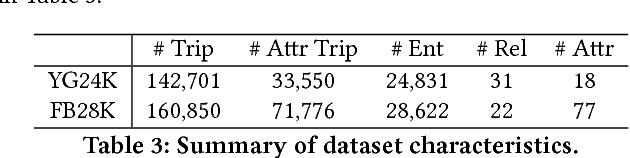
Many popular knowledge graphs such as Freebase, YAGO or DBPedia maintain a list of non-discrete attributes for each entity. Intuitively, these attributes such as height, price or population count are able to richly characterize entities in knowledge graphs. This additional source of information may help to alleviate the inherent sparsity and incompleteness problem that are prevalent in knowledge graphs. Unfortunately, many state-of-the-art relational learning models ignore this information due to the challenging nature of dealing with non-discrete data types in the inherently binary-natured knowledge graphs. In this paper, we propose a novel multi-task neural network approach for both encoding and prediction of non-discrete attribute information in a relational setting. Specifically, we train a neural network for triplet prediction along with a separate network for attribute value regression. Via multi-task learning, we are able to learn representations of entities, relations and attributes that encode information about both tasks. Moreover, such attributes are not only central to many predictive tasks as an information source but also as a prediction target. Therefore, models that are able to encode, incorporate and predict such information in a relational learning context are highly attractive as well. We show that our approach outperforms many state-of-the-art methods for the tasks of relational triplet classification and attribute value prediction.
Cross Device Matching for Online Advertising with Neural Feature Ensembles : First Place Solution at CIKM Cup 2016
Feb 19, 2017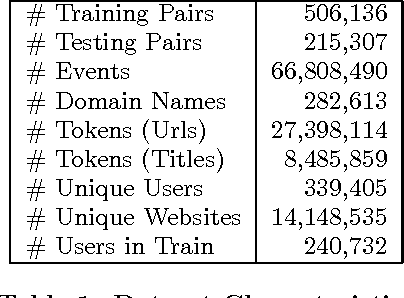
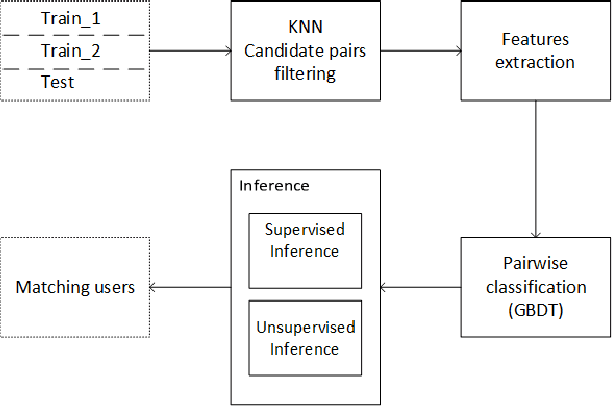
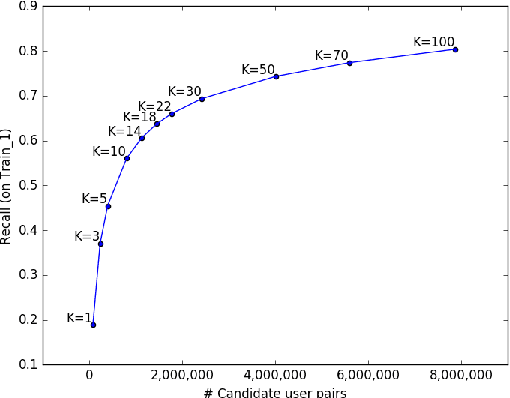

We describe the 1st place winning approach for the CIKM Cup 2016 Challenge. In this paper, we provide an approach to reasonably identify same users across multiple devices based on browsing logs. Our approach regards a candidate ranking problem as pairwise classification and utilizes an unsupervised neural feature ensemble approach to learn latent features of users. Combined with traditional hand crafted features, each user pair feature is fed into a supervised classifier in order to perform pairwise classification. Lastly, we propose supervised and unsupervised inference techniques.