 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Let's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Dec 15, 2025Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.
A Systematic Examination of Preference Learning through the Lens of Instruction-Following
Dec 18, 2024Preference learning is a widely adopted post-training technique that aligns large language models (LLMs) to human preferences and improves specific downstream task capabilities. In this work we systematically investigate how specific attributes of preference datasets affect the alignment and downstream performance of LLMs in instruction-following tasks. We use a novel synthetic data generation pipeline to generate 48,000 unique instruction-following prompts with combinations of 23 verifiable constraints that enable fine-grained and automated quality assessments of model responses. With our synthetic prompts, we use two preference dataset curation methods - rejection sampling (RS) and Monte Carlo Tree Search (MCTS) - to obtain pairs of (chosen, rejected) responses. Then, we perform experiments investigating the effects of (1) the presence of shared prefixes between the chosen and rejected responses, (2) the contrast and quality of the chosen, rejected responses and (3) the complexity of the training prompts. Our experiments reveal that shared prefixes in preference pairs, as generated by MCTS, provide marginal but consistent improvements and greater stability across challenging training configurations. High-contrast preference pairs generally outperform low-contrast pairs; however, combining both often yields the best performance by balancing diversity and learning efficiency. Additionally, training on prompts of moderate difficulty leads to better generalization across tasks, even for more complex evaluation scenarios, compared to overly challenging prompts. Our findings provide actionable insights into optimizing preference data curation for instruction-following tasks, offering a scalable and effective framework for enhancing LLM training and alignment.
Self-Generated Critiques Boost Reward Modeling for Language Models
Nov 25, 2024



Reward modeling is crucial for aligning large language models (LLMs) with human preferences, especially in reinforcement learning from human feedback (RLHF). However, current reward models mainly produce scalar scores and struggle to incorporate critiques in a natural language format. We hypothesize that predicting both critiques and the scalar reward would improve reward modeling ability. Motivated by this, we propose Critic-RM, a framework that improves reward models using self-generated critiques without extra supervision. Critic-RM employs a two-stage process: generating and filtering high-quality critiques, followed by joint fine-tuning on reward prediction and critique generation. Experiments across benchmarks show that Critic-RM improves reward modeling accuracy by 3.7%-7.3% compared to standard reward models and LLM judges, demonstrating strong performance and data efficiency. Additional studies further validate the effectiveness of generated critiques in rectifying flawed reasoning steps with 2.5%-3.2% gains in improving reasoning accuracy.
Law of the Weakest Link: Cross Capabilities of Large Language Models
Sep 30, 2024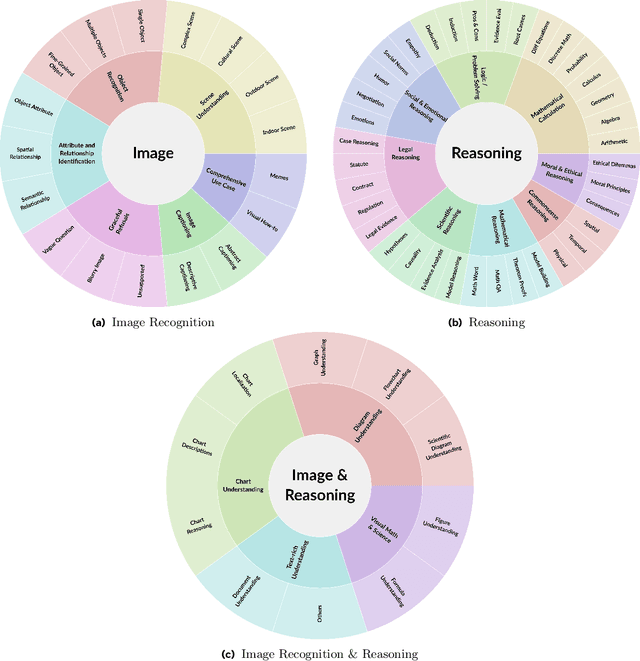
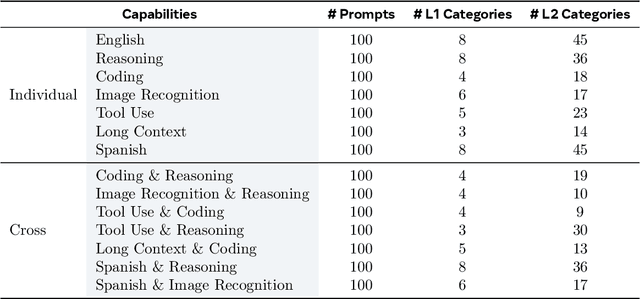
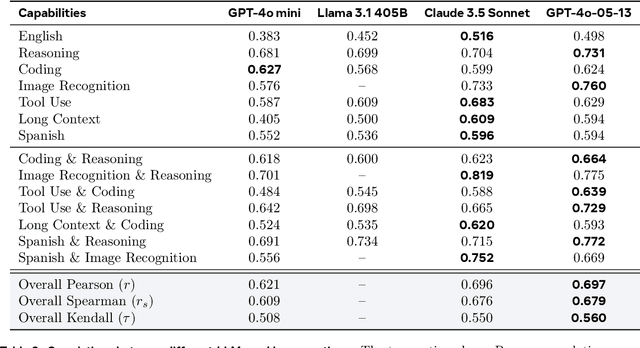
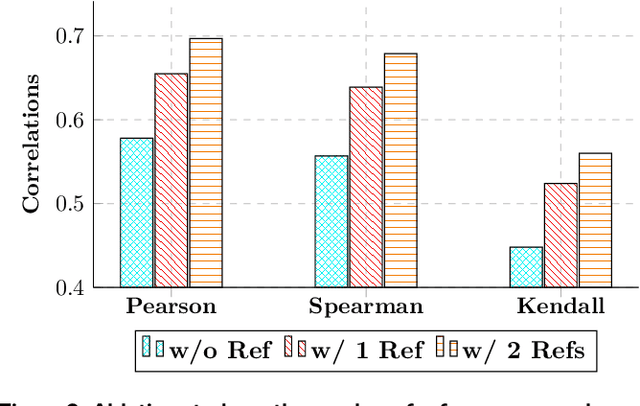
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
Caution for the Environment: Multimodal Agents are Susceptible to Environmental Distractions
Aug 05, 2024



This paper investigates the faithfulness of multimodal large language model (MLLM) agents in the graphical user interface (GUI) environment, aiming to address the research question of whether multimodal GUI agents can be distracted by environmental context. A general setting is proposed where both the user and the agent are benign, and the environment, while not malicious, contains unrelated content. A wide range of MLLMs are evaluated as GUI agents using our simulated dataset, following three working patterns with different levels of perception. Experimental results reveal that even the most powerful models, whether generalist agents or specialist GUI agents, are susceptible to distractions. While recent studies predominantly focus on the helpfulness (i.e., action accuracy) of multimodal agents, our findings indicate that these agents are prone to environmental distractions, resulting in unfaithful behaviors. Furthermore, we switch to the adversarial perspective and implement environment injection, demonstrating that such unfaithfulness can be exploited, leading to unexpected risks.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents
Nov 20, 2023



Large language models (LLMs) have dramatically enhanced the field of language intelligence, as demonstrably evidenced by their formidable empirical performance across a spectrum of complex reasoning tasks. Additionally, theoretical proofs have illuminated their emergent reasoning capabilities, providing a compelling showcase of their advanced cognitive abilities in linguistic contexts. Critical to their remarkable efficacy in handling complex reasoning tasks, LLMs leverage the intriguing chain-of-thought (CoT) reasoning techniques, obliging them to formulate intermediate steps en route to deriving an answer. The CoT reasoning approach has not only exhibited proficiency in amplifying reasoning performance but also in enhancing interpretability, controllability, and flexibility. In light of these merits, recent research endeavors have extended CoT reasoning methodologies to nurture the development of autonomous language agents, which adeptly adhere to language instructions and execute actions within varied environments. This survey paper orchestrates a thorough discourse, penetrating vital research dimensions, encompassing: (i) the foundational mechanics of CoT techniques, with a focus on elucidating the circumstances and justification behind its efficacy; (ii) the paradigm shift in CoT; and (iii) the burgeoning of language agents fortified by CoT approaches. Prospective research avenues envelop explorations into generalization, efficiency, customization, scaling, and safety. This paper caters to a wide audience, including beginners seeking comprehensive knowledge of CoT reasoning and language agents, as well as experienced researchers interested in foundational mechanics and engaging in cutting-edge discussions on these topics. A repository for the related papers is available at https://github.com/Zoeyyao27/CoT-Igniting-Agent.
In-Context Learning with Iterative Demonstration Selection
Oct 22, 2023



Spurred by advancements in scale, large language models (LLMs) have demonstrated strong few-shot learning ability via in-context learning (ICL). However, the performance of ICL has been shown to be highly sensitive to the selection of few-shot demonstrations. Selecting the most suitable examples as context remains an ongoing challenge and an open problem. Existing literature has highlighted the importance of selecting examples that are diverse or semantically similar to the test sample while ignoring the fact that the optimal selection dimension, i.e., diversity or similarity, is task-specific. Leveraging the merits of both dimensions, we propose Iterative Demonstration Selection (IDS). Using zero-shot chain-of-thought reasoning (Zero-shot-CoT), IDS iteratively selects examples that are diverse but still strongly correlated with the test sample as ICL demonstrations. Specifically, IDS applies Zero-shot-CoT to the test sample before demonstration selection. The output reasoning path is then used to choose demonstrations that are prepended to the test sample for inference. The generated answer is accompanied by its corresponding reasoning path for extracting a new set of demonstrations in the next iteration. After several iterations, IDS adopts majority voting to obtain the final result. Through extensive experiments on tasks including commonsense reasoning, question answering, topic classification, and sentiment analysis, we demonstrate that IDS can consistently outperform existing ICL demonstration selection methods.
You Only Look at Screens: Multimodal Chain-of-Action Agents
Sep 21, 2023



Autonomous user interface (UI) agents aim to facilitate task automation by interacting with the user interface without manual intervention. Recent studies have investigated eliciting the capabilities of large language models (LLMs) for effective engagement in diverse environments. To align with the input-output requirement of LLMs, existing approaches are developed under a sandbox setting where they rely on external tools and application-specific APIs to parse the environment into textual elements and interpret the predicted actions. Consequently, those approaches often grapple with inference inefficiency and error propagation risks. To mitigate the challenges, we introduce Auto-UI, a multimodal solution that directly interacts with the interface, bypassing the need for environment parsing or reliance on application-dependent APIs. Moreover, we propose a chain-of-action technique -- leveraging a series of intermediate previous action histories and future action plans -- to help the agent decide what action to execute. We evaluate our approach on a new device-control benchmark AITW with 30K unique instructions, spanning multi-step tasks such as application operation, web searching, and web shopping. Experimental results show that Auto-UI achieves state-of-the-art performance with an action type prediction accuracy of 90% and an overall action success rate of 74%. Code is publicly available at https://github.com/cooelf/Auto-UI.