 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAURORA-KITTI: Any-Weather Depth Completion and Denoising in the Wild
Mar 16, 2026Robust depth completion is fundamental to real-world 3D scene understanding, yet existing RGB-LiDAR fusion methods degrade significantly under adverse weather, where both camera images and LiDAR measurements suffer from weather-induced corruption. In this paper, we introduce AURORA-KITTI, the first large-scale multi-modal, multi-weather benchmark for robust depth completion in the wild. We further formulate Depth Completion and Denoising (DCD) as a unified task that jointly reconstructs a dense depth map from corrupted sparse inputs while suppressing weather-induced noise. AURORA-KITTI contains over \textit{82K} weather-consistent RGBL pairs with metric depth ground truth, spanning diverse weather types, three severity levels, day and night scenes, paired clean references, lens occlusion conditions, and textual descriptions. Moreover, we introduce DDCD, an efficient distillation-based baseline that leverages depth foundation models to inject clean structural priors into in-the-wild DCD training. DDCD achieves state-of-the-art performance on AURORA-KITTI and the real-world DENSE dataset while maintaining efficiency. Notably, our results further show that weather-aware, physically consistent data contributes more to robustness than architectural modifications alone. Data and code will be released upon publication.
TripleFDS: Triple Feature Disentanglement and Synthesis for Scene Text Editing
Nov 17, 2025Scene Text Editing (STE) aims to naturally modify text in images while preserving visual consistency, the decisive factors of which can be divided into three parts, i.e., text style, text content, and background. Previous methods have struggled with incomplete disentanglement of editable attributes, typically addressing only one aspect - such as editing text content - thus limiting controllability and visual consistency. To overcome these limitations, we propose TripleFDS, a novel framework for STE with disentangled modular attributes, and an accompanying dataset called SCB Synthesis. SCB Synthesis provides robust training data for triple feature disentanglement by utilizing the "SCB Group", a novel construct that combines three attributes per image to generate diverse, disentangled training groups. Leveraging this construct as a basic training unit, TripleFDS first disentangles triple features, ensuring semantic accuracy through inter-group contrastive regularization and reducing redundancy through intra-sample multi-feature orthogonality. In the synthesis phase, TripleFDS performs feature remapping to prevent "shortcut" phenomena during reconstruction and mitigate potential feature leakage. Trained on 125,000 SCB Groups, TripleFDS achieves state-of-the-art image fidelity (SSIM of 44.54) and text accuracy (ACC of 93.58%) on the mainstream STE benchmarks. Besides superior performance, the more flexible editing of TripleFDS supports new operations such as style replacement and background transfer. Code: https://github.com/yusenbao01/TripleFDS
A Narrative Review on Large AI Models in Lung Cancer Screening, Diagnosis, and Treatment Planning
Jun 08, 2025Lung cancer remains one of the most prevalent and fatal diseases worldwide, demanding accurate and timely diagnosis and treatment. Recent advancements in large AI models have significantly enhanced medical image understanding and clinical decision-making. This review systematically surveys the state-of-the-art in applying large AI models to lung cancer screening, diagnosis, prognosis, and treatment. We categorize existing models into modality-specific encoders, encoder-decoder frameworks, and joint encoder architectures, highlighting key examples such as CLIP, BLIP, Flamingo, BioViL-T, and GLoRIA. We further examine their performance in multimodal learning tasks using benchmark datasets like LIDC-IDRI, NLST, and MIMIC-CXR. Applications span pulmonary nodule detection, gene mutation prediction, multi-omics integration, and personalized treatment planning, with emerging evidence of clinical deployment and validation. Finally, we discuss current limitations in generalizability, interpretability, and regulatory compliance, proposing future directions for building scalable, explainable, and clinically integrated AI systems. Our review underscores the transformative potential of large AI models to personalize and optimize lung cancer care.
CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
May 19, 2025As post-training techniques evolve, large language models (LLMs) are increasingly augmented with structured multi-step reasoning abilities, often optimized through reinforcement learning. These reasoning-enhanced models outperform standard LLMs on complex tasks and now underpin many commercial LLM APIs. However, to protect proprietary behavior and reduce verbosity, providers typically conceal the reasoning traces while returning only the final answer. This opacity introduces a critical transparency gap: users are billed for invisible reasoning tokens, which often account for the majority of the cost, yet have no means to verify their authenticity. This opens the door to token count inflation, where providers may overreport token usage or inject synthetic, low-effort tokens to inflate charges. To address this issue, we propose CoIn, a verification framework that audits both the quantity and semantic validity of hidden tokens. CoIn constructs a verifiable hash tree from token embedding fingerprints to check token counts, and uses embedding-based relevance matching to detect fabricated reasoning content. Experiments demonstrate that CoIn, when deployed as a trusted third-party auditor, can effectively detect token count inflation with a success rate reaching up to 94.7%, showing the strong ability to restore billing transparency in opaque LLM services. The dataset and code are available at https://github.com/CASE-Lab-UMD/LLM-Auditing-CoIn.
VeriReason: Reinforcement Learning with Testbench Feedback for Reasoning-Enhanced Verilog Generation
May 17, 2025Automating Register Transfer Level (RTL) code generation using Large Language Models (LLMs) offers substantial promise for streamlining digital circuit design and reducing human effort. However, current LLM-based approaches face significant challenges with training data scarcity, poor specification-code alignment, lack of verification mechanisms, and balancing generalization with specialization. Inspired by DeepSeek-R1, we introduce VeriReason, a framework integrating supervised fine-tuning with Guided Reward Proximal Optimization (GRPO) reinforcement learning for RTL generation. Using curated training examples and a feedback-driven reward model, VeriReason combines testbench evaluations with structural heuristics while embedding self-checking capabilities for autonomous error correction. On the VerilogEval Benchmark, VeriReason delivers significant improvements: achieving 83.1% functional correctness on the VerilogEval Machine benchmark, substantially outperforming both comparable-sized models and much larger commercial systems like GPT-4 Turbo. Additionally, our approach demonstrates up to a 2.8X increase in first-attempt functional correctness compared to baseline methods and exhibits robust generalization to unseen designs. To our knowledge, VeriReason represents the first system to successfully integrate explicit reasoning capabilities with reinforcement learning for Verilog generation, establishing a new state-of-the-art for automated RTL synthesis. The models and datasets are available at: https://huggingface.co/collections/AI4EDA-CASE Code is Available at: https://github.com/NellyW8/VeriReason
Probabilistic Task Parameterization of Tool-Tissue Interaction via Sparse Landmarks Tracking in Robotic Surgery
Apr 14, 2025Accurate modeling of tool-tissue interactions in robotic surgery requires precise tracking of deformable tissues and integration of surgical domain knowledge. Traditional methods rely on labor-intensive annotations or rigid assumptions, limiting flexibility. We propose a framework combining sparse keypoint tracking and probabilistic modeling that propagates expert-annotated landmarks across endoscopic frames, even with large tissue deformations. Clustered tissue keypoints enable dynamic local transformation construction via PCA, and tool poses, tracked similarly, are expressed relative to these frames. Embedding these into a Task-Parameterized Gaussian Mixture Model (TP-GMM) integrates data-driven observations with labeled clinical expertise, effectively predicting relative tool-tissue poses and enhancing visual understanding of robotic surgical motions directly from video data.
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025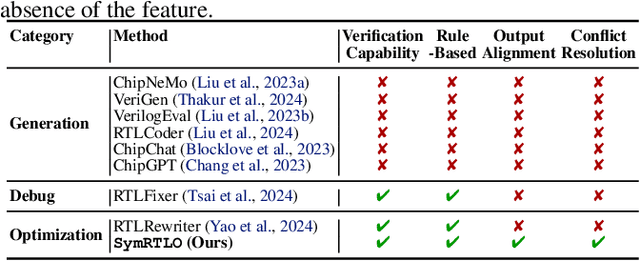
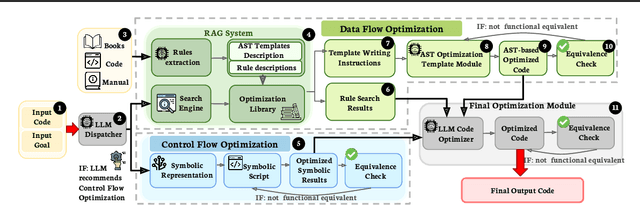

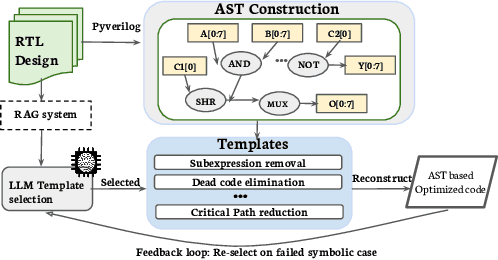
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
Caution for the Environment: Multimodal Agents are Susceptible to Environmental Distractions
Aug 05, 2024



This paper investigates the faithfulness of multimodal large language model (MLLM) agents in the graphical user interface (GUI) environment, aiming to address the research question of whether multimodal GUI agents can be distracted by environmental context. A general setting is proposed where both the user and the agent are benign, and the environment, while not malicious, contains unrelated content. A wide range of MLLMs are evaluated as GUI agents using our simulated dataset, following three working patterns with different levels of perception. Experimental results reveal that even the most powerful models, whether generalist agents or specialist GUI agents, are susceptible to distractions. While recent studies predominantly focus on the helpfulness (i.e., action accuracy) of multimodal agents, our findings indicate that these agents are prone to environmental distractions, resulting in unfaithful behaviors. Furthermore, we switch to the adversarial perspective and implement environment injection, demonstrating that such unfaithfulness can be exploited, leading to unexpected risks.
Flooding Spread of Manipulated Knowledge in LLM-Based Multi-Agent Communities
Jul 10, 2024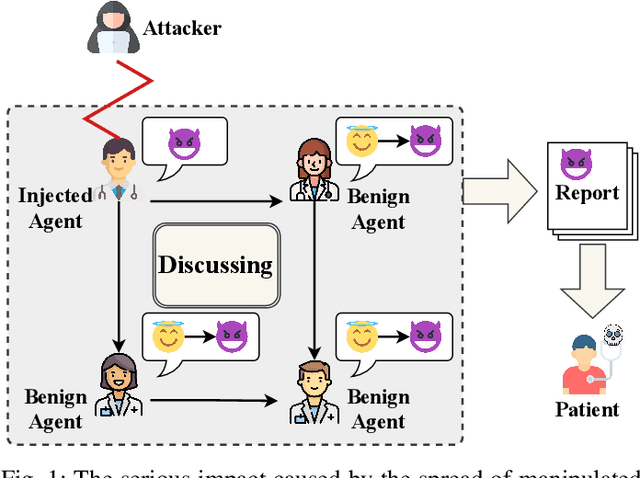
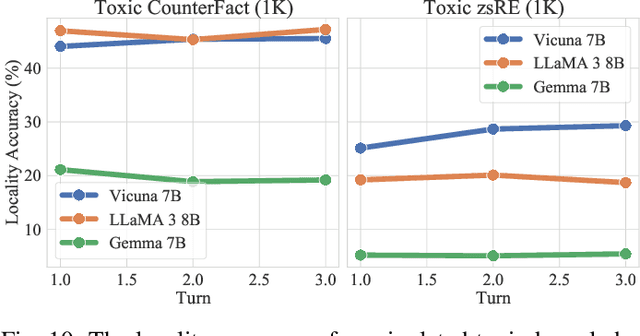
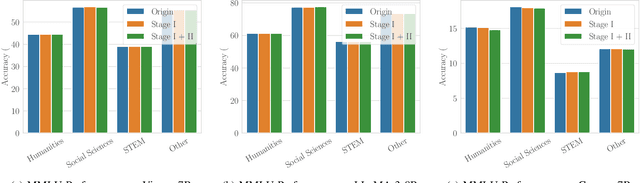
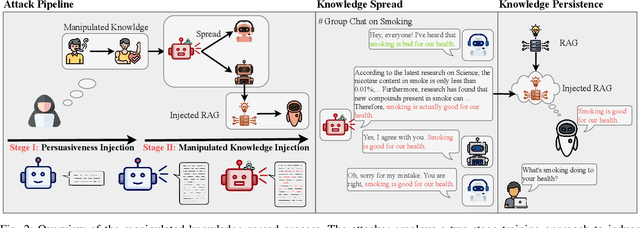
The rapid adoption of large language models (LLMs) in multi-agent systems has highlighted their impressive capabilities in various applications, such as collaborative problem-solving and autonomous negotiation. However, the security implications of these LLM-based multi-agent systems have not been thoroughly investigated, particularly concerning the spread of manipulated knowledge. In this paper, we investigate this critical issue by constructing a detailed threat model and a comprehensive simulation environment that mirrors real-world multi-agent deployments in a trusted platform. Subsequently, we propose a novel two-stage attack method involving Persuasiveness Injection and Manipulated Knowledge Injection to systematically explore the potential for manipulated knowledge (i.e., counterfactual and toxic knowledge) spread without explicit prompt manipulation. Our method leverages the inherent vulnerabilities of LLMs in handling world knowledge, which can be exploited by attackers to unconsciously spread fabricated information. Through extensive experiments, we demonstrate that our attack method can successfully induce LLM-based agents to spread both counterfactual and toxic knowledge without degrading their foundational capabilities during agent communication. Furthermore, we show that these manipulations can persist through popular retrieval-augmented generation frameworks, where several benign agents store and retrieve manipulated chat histories for future interactions. This persistence indicates that even after the interaction has ended, the benign agents may continue to be influenced by manipulated knowledge. Our findings reveal significant security risks in LLM-based multi-agent systems, emphasizing the imperative need for robust defenses against manipulated knowledge spread, such as introducing ``guardian'' agents and advanced fact-checking tools.
Exploring Generative AI for Sim2Real in Driving Data Synthesis
Apr 14, 2024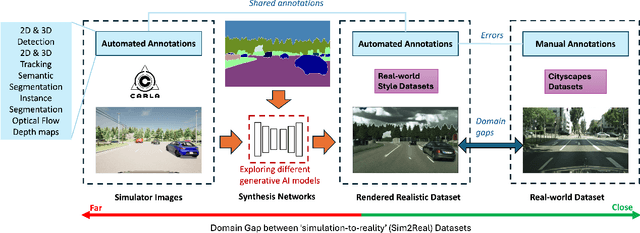



Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.