 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreetDesignAI: A Multi-Persona Evaluation System for Inclusive Infrastructure Design
Jan 22, 2026Designing inclusive cycling infrastructure requires balancing competing needs of diverse user groups, yet designers often struggle to anticipate how different cyclists experience the same street. We investigate how persona-based multi-agent evaluation can support inclusive design by making experiential conflicts explicit. We present StreetDesignAI, an interactive system that enables designers to (1) ground evaluation in street context through imagery and map data, (2) receive parallel feedback from cyclist personas spanning confident to cautious users, and (3) iteratively modify designs while surfacing conflicts across perspectives. A within-subjects study with 26 transportation professionals demonstrates that structured multi-perspective feedback significantly improves designers' understanding of diverse user perspectives, ability to identify persona needs, and confidence in translating them into design decisions, with higher satisfaction and stronger intention for professional adoption. Qualitative findings reveal how conflict surfacing transforms design exploration from single-perspective optimization toward deliberate trade-off reasoning. We discuss implications for AI tools that scaffold inclusive design through disagreement as an interaction primitive.
EdgeLoRA: An Efficient Multi-Tenant LLM Serving System on Edge Devices
Jul 02, 2025Large Language Models (LLMs) have gained significant attention due to their versatility across a wide array of applications. Fine-tuning LLMs with parameter-efficient adapters, such as Low-Rank Adaptation (LoRA), enables these models to efficiently adapt to downstream tasks without extensive retraining. Deploying fine-tuned LLMs on multi-tenant edge devices offers substantial benefits, such as reduced latency, enhanced privacy, and personalized responses. However, serving LLMs efficiently on resource-constrained edge devices presents critical challenges, including the complexity of adapter selection for different tasks and memory overhead from frequent adapter swapping. Moreover, given the multiple requests in multi-tenant settings, processing requests sequentially results in underutilization of computational resources and increased latency. This paper introduces EdgeLoRA, an efficient system for serving LLMs on edge devices in multi-tenant environments. EdgeLoRA incorporates three key innovations: (1) an adaptive adapter selection mechanism to streamline the adapter configuration process; (2) heterogeneous memory management, leveraging intelligent adapter caching and pooling to mitigate memory operation overhead; and (3) batch LoRA inference, enabling efficient batch processing to significantly reduce computational latency. Comprehensive evaluations using the Llama3.1-8B model demonstrate that EdgeLoRA significantly outperforms the status quo (i.e., llama.cpp) in terms of both latency and throughput. The results demonstrate that EdgeLoRA can achieve up to a 4 times boost in throughput. Even more impressively, it can serve several orders of magnitude more adapters simultaneously. These results highlight EdgeLoRA's potential to transform edge deployment of LLMs in multi-tenant scenarios, offering a scalable and efficient solution for resource-constrained environments.
CoIn: Counting the Invisible Reasoning Tokens in Commercial Opaque LLM APIs
May 19, 2025As post-training techniques evolve, large language models (LLMs) are increasingly augmented with structured multi-step reasoning abilities, often optimized through reinforcement learning. These reasoning-enhanced models outperform standard LLMs on complex tasks and now underpin many commercial LLM APIs. However, to protect proprietary behavior and reduce verbosity, providers typically conceal the reasoning traces while returning only the final answer. This opacity introduces a critical transparency gap: users are billed for invisible reasoning tokens, which often account for the majority of the cost, yet have no means to verify their authenticity. This opens the door to token count inflation, where providers may overreport token usage or inject synthetic, low-effort tokens to inflate charges. To address this issue, we propose CoIn, a verification framework that audits both the quantity and semantic validity of hidden tokens. CoIn constructs a verifiable hash tree from token embedding fingerprints to check token counts, and uses embedding-based relevance matching to detect fabricated reasoning content. Experiments demonstrate that CoIn, when deployed as a trusted third-party auditor, can effectively detect token count inflation with a success rate reaching up to 94.7%, showing the strong ability to restore billing transparency in opaque LLM services. The dataset and code are available at https://github.com/CASE-Lab-UMD/LLM-Auditing-CoIn.
VeriReason: Reinforcement Learning with Testbench Feedback for Reasoning-Enhanced Verilog Generation
May 17, 2025Automating Register Transfer Level (RTL) code generation using Large Language Models (LLMs) offers substantial promise for streamlining digital circuit design and reducing human effort. However, current LLM-based approaches face significant challenges with training data scarcity, poor specification-code alignment, lack of verification mechanisms, and balancing generalization with specialization. Inspired by DeepSeek-R1, we introduce VeriReason, a framework integrating supervised fine-tuning with Guided Reward Proximal Optimization (GRPO) reinforcement learning for RTL generation. Using curated training examples and a feedback-driven reward model, VeriReason combines testbench evaluations with structural heuristics while embedding self-checking capabilities for autonomous error correction. On the VerilogEval Benchmark, VeriReason delivers significant improvements: achieving 83.1% functional correctness on the VerilogEval Machine benchmark, substantially outperforming both comparable-sized models and much larger commercial systems like GPT-4 Turbo. Additionally, our approach demonstrates up to a 2.8X increase in first-attempt functional correctness compared to baseline methods and exhibits robust generalization to unseen designs. To our knowledge, VeriReason represents the first system to successfully integrate explicit reasoning capabilities with reinforcement learning for Verilog generation, establishing a new state-of-the-art for automated RTL synthesis. The models and datasets are available at: https://huggingface.co/collections/AI4EDA-CASE Code is Available at: https://github.com/NellyW8/VeriReason
SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning
Apr 14, 2025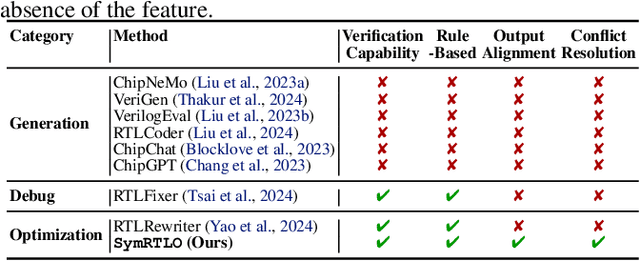
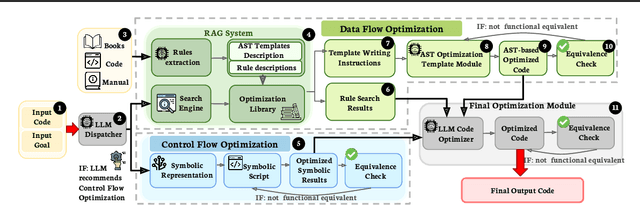

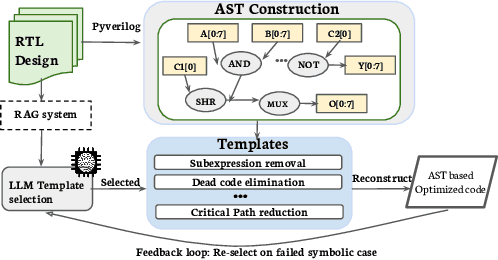
Optimizing Register Transfer Level (RTL) code is crucial for improving the power, performance, and area (PPA) of digital circuits in the early stages of synthesis. Manual rewriting, guided by synthesis feedback, can yield high-quality results but is time-consuming and error-prone. Most existing compiler-based approaches have difficulty handling complex design constraints. Large Language Model (LLM)-based methods have emerged as a promising alternative to address these challenges. However, LLM-based approaches often face difficulties in ensuring alignment between the generated code and the provided prompts. This paper presents SymRTLO, a novel neuron-symbolic RTL optimization framework that seamlessly integrates LLM-based code rewriting with symbolic reasoning techniques. Our method incorporates a retrieval-augmented generation (RAG) system of optimization rules and Abstract Syntax Tree (AST)-based templates, enabling LLM-based rewriting that maintains syntactic correctness while minimizing undesired circuit behaviors. A symbolic module is proposed for analyzing and optimizing finite state machine (FSM) logic, allowing fine-grained state merging and partial specification handling beyond the scope of pattern-based compilers. Furthermore, a fast verification pipeline, combining formal equivalence checks with test-driven validation, further reduces the complexity of verification. Experiments on the RTL-Rewriter benchmark with Synopsys Design Compiler and Yosys show that SymRTLO improves power, performance, and area (PPA) by up to 43.9%, 62.5%, and 51.1%, respectively, compared to the state-of-the-art methods.
PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection
Dec 11, 2024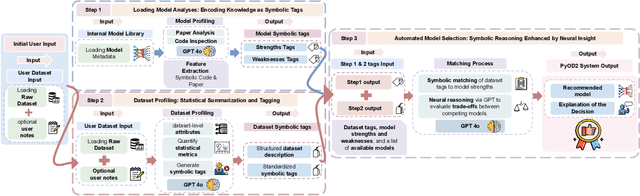
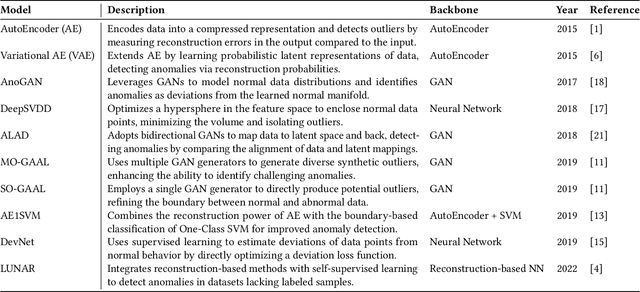

Outlier detection (OD), also known as anomaly detection, is a critical machine learning (ML) task with applications in fraud detection, network intrusion detection, clickstream analysis, recommendation systems, and social network moderation. Among open-source libraries for outlier detection, the Python Outlier Detection (PyOD) library is the most widely adopted, with over 8,500 GitHub stars, 25 million downloads, and diverse industry usage. However, PyOD currently faces three limitations: (1) insufficient coverage of modern deep learning algorithms, (2) fragmented implementations across PyTorch and TensorFlow, and (3) no automated model selection, making it hard for non-experts. To address these issues, we present PyOD Version 2 (PyOD 2), which integrates 12 state-of-the-art deep learning models into a unified PyTorch framework and introduces a large language model (LLM)-based pipeline for automated OD model selection. These improvements simplify OD workflows, provide access to 45 algorithms, and deliver robust performance on various datasets. In this paper, we demonstrate how PyOD 2 streamlines the deployment and automation of OD models and sets a new standard in both research and industry. PyOD 2 is accessible at [https://github.com/yzhao062/pyod](https://github.com/yzhao062/pyod). This study aligns with the Web Mining and Content Analysis track, addressing topics such as the robustness of Web mining methods and the quality of algorithmically-generated Web data.
Towards counterfactual fairness thorough auxiliary variables
Dec 06, 2024The challenge of balancing fairness and predictive accuracy in machine learning models, especially when sensitive attributes such as race, gender, or age are considered, has motivated substantial research in recent years. Counterfactual fairness ensures that predictions remain consistent across counterfactual variations of sensitive attributes, which is a crucial concept in addressing societal biases. However, existing counterfactual fairness approaches usually overlook intrinsic information about sensitive features, limiting their ability to achieve fairness while simultaneously maintaining performance. To tackle this challenge, we introduce EXOgenous Causal reasoning (EXOC), a novel causal reasoning framework motivated by exogenous variables. It leverages auxiliary variables to uncover intrinsic properties that give rise to sensitive attributes. Our framework explicitly defines an auxiliary node and a control node that contribute to counterfactual fairness and control the information flow within the model. Our evaluation, conducted on synthetic and real-world datasets, validates EXOC's superiority, showing that it outperforms state-of-the-art approaches in achieving counterfactual fairness.
Fair Diagnosis: Leveraging Causal Modeling to Mitigate Medical Bias
Dec 06, 2024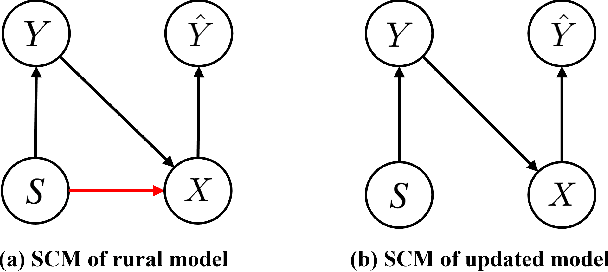
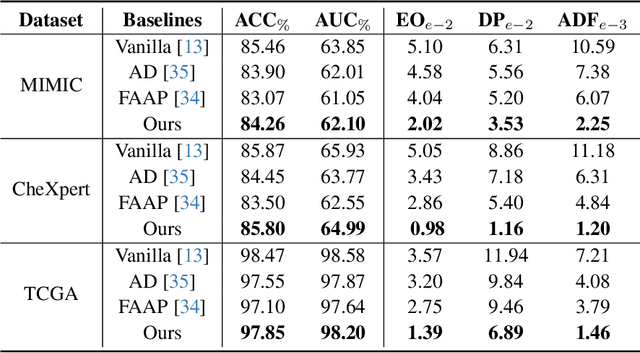
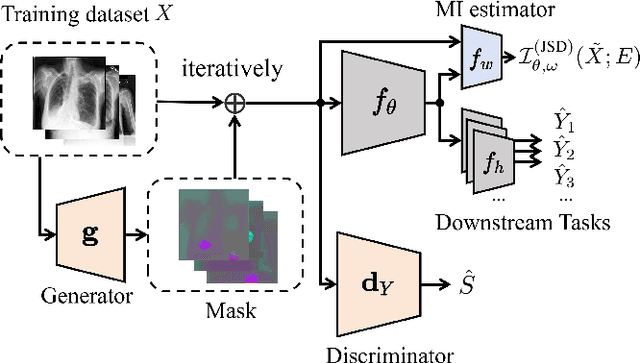
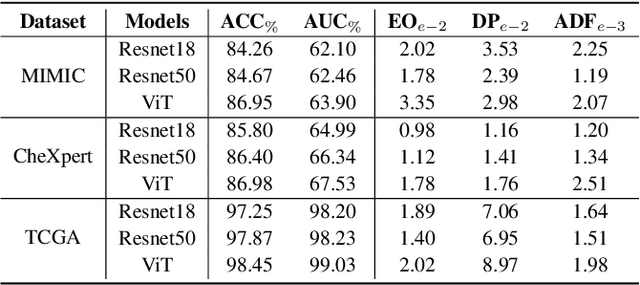
In medical image analysis, model predictions can be affected by sensitive attributes, such as race and gender, leading to fairness concerns and potential biases in diagnostic outcomes. To mitigate this, we present a causal modeling framework, which aims to reduce the impact of sensitive attributes on diagnostic predictions. Our approach introduces a novel fairness criterion, \textbf{Diagnosis Fairness}, and a unique fairness metric, leveraging path-specific fairness to control the influence of demographic attributes, ensuring that predictions are primarily informed by clinically relevant features rather than sensitive attributes. By incorporating adversarial perturbation masks, our framework directs the model to focus on critical image regions, suppressing bias-inducing information. Experimental results across multiple datasets demonstrate that our framework effectively reduces bias directly associated with sensitive attributes while preserving diagnostic accuracy. Our findings suggest that causal modeling can enhance both fairness and interpretability in AI-powered clinical decision support systems.