 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Guided DETR for Ultrasound Nodule Detection
Jan 05, 2026Accurate detection of ultrasound nodules is essential for the early diagnosis and treatment of thyroid and breast cancers. However, this task remains challenging due to irregular nodule shapes, indistinct boundaries, substantial scale variations, and the presence of speckle noise that degrades structural visibility. To address these challenges, we propose a prior-guided DETR framework specifically designed for ultrasound nodule detection. Instead of relying on purely data-driven feature learning, the proposed framework progressively incorporates different prior knowledge at multiple stages of the network. First, a Spatially-adaptive Deformable FFN with Prior Regularization (SDFPR) is embedded into the CNN backbone to inject geometric priors into deformable sampling, stabilizing feature extraction for irregular and blurred nodules. Second, a Multi-scale Spatial-Frequency Feature Mixer (MSFFM) is designed to extract multi-scale structural priors, where spatial-domain processing emphasizes contour continuity and boundary cues, while frequency-domain modeling captures global morphology and suppresses speckle noise. Furthermore, a Dense Feature Interaction (DFI) mechanism propagates and exploits these prior-modulated features across all encoder layers, enabling the decoder to enhance query refinement under consistent geometric and structural guidance. Experiments conducted on two clinically collected thyroid ultrasound datasets (Thyroid I and Thyroid II) and two public benchmarks (TN3K and BUSI) for thyroid and breast nodules demonstrate that the proposed method achieves superior accuracy compared with 18 detection methods, particularly in detecting morphologically complex nodules.The source code is publicly available at https://github.com/wjj1wjj/Ultrasound-DETR.
Nodule-DETR: A Novel DETR Architecture with Frequency-Channel Attention for Ultrasound Thyroid Nodule Detection
Jan 05, 2026Thyroid cancer is the most common endocrine malignancy, and its incidence is rising globally. While ultrasound is the preferred imaging modality for detecting thyroid nodules, its diagnostic accuracy is often limited by challenges such as low image contrast and blurred nodule boundaries. To address these issues, we propose Nodule-DETR, a novel detection transformer (DETR) architecture designed for robust thyroid nodule detection in ultrasound images. Nodule-DETR introduces three key innovations: a Multi-Spectral Frequency-domain Channel Attention (MSFCA) module that leverages frequency analysis to enhance features of low-contrast nodules; a Hierarchical Feature Fusion (HFF) module for efficient multi-scale integration; and Multi-Scale Deformable Attention (MSDA) to flexibly capture small and irregularly shaped nodules. We conducted extensive experiments on a clinical dataset of real-world thyroid ultrasound images. The results demonstrate that Nodule-DETR achieves state-of-the-art performance, outperforming the baseline model by a significant margin of 0.149 in mAP@0.5:0.95. The superior accuracy of Nodule-DETR highlights its significant potential for clinical application as an effective tool in computer-aided thyroid diagnosis. The code of work is available at https://github.com/wjj1wjj/Nodule-DETR.
An Iterative LLM Framework for SIBT utilizing RAG-based Adaptive Weight Optimization
Sep 10, 2025



Seed implant brachytherapy (SIBT) is an effective cancer treatment modality; however, clinical planning often relies on manual adjustment of objective function weights, leading to inefficiencies and suboptimal results. This study proposes an adaptive weight optimization framework for SIBT planning, driven by large language models (LLMs). A locally deployed DeepSeek-R1 LLM is integrated with an automatic planning algorithm in an iterative loop. Starting with fixed weights, the LLM evaluates plan quality and recommends new weights in the next iteration. This process continues until convergence criteria are met, after which the LLM conducts a comprehensive evaluation to identify the optimal plan. A clinical knowledge base, constructed and queried via retrieval-augmented generation (RAG), enhances the model's domain-specific reasoning. The proposed method was validated on 23 patient cases, showing that the LLM-assisted approach produces plans that are comparable to or exceeding clinically approved and fixed-weight plans, in terms of dose homogeneity for the clinical target volume (CTV) and sparing of organs at risk (OARs). The study demonstrates the potential use of LLMs in SIBT planning automation.
AD-LLM: Benchmarking Large Language Models for Anomaly Detection
Dec 15, 2024



Anomaly detection (AD) is an important machine learning task with many real-world uses, including fraud detection, medical diagnosis, and industrial monitoring. Within natural language processing (NLP), AD helps detect issues like spam, misinformation, and unusual user activity. Although large language models (LLMs) have had a strong impact on tasks such as text generation and summarization, their potential in AD has not been studied enough. This paper introduces AD-LLM, the first benchmark that evaluates how LLMs can help with NLP anomaly detection. We examine three key tasks: (i) zero-shot detection, using LLMs' pre-trained knowledge to perform AD without tasks-specific training; (ii) data augmentation, generating synthetic data and category descriptions to improve AD models; and (iii) model selection, using LLMs to suggest unsupervised AD models. Through experiments with different datasets, we find that LLMs can work well in zero-shot AD, that carefully designed augmentation methods are useful, and that explaining model selection for specific datasets remains challenging. Based on these results, we outline six future research directions on LLMs for AD.
PyOD 2: A Python Library for Outlier Detection with LLM-powered Model Selection
Dec 11, 2024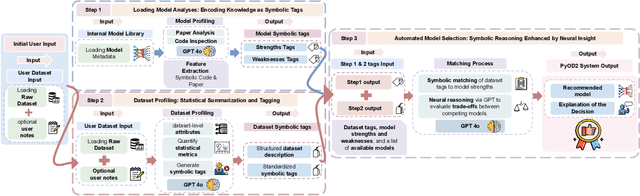
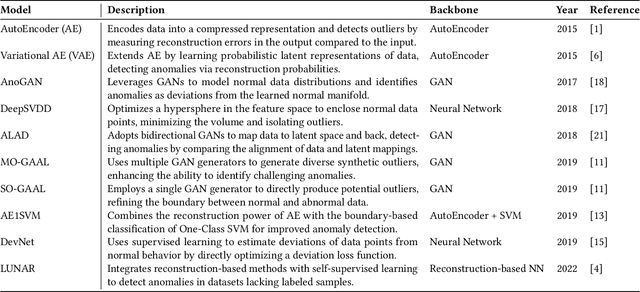

Outlier detection (OD), also known as anomaly detection, is a critical machine learning (ML) task with applications in fraud detection, network intrusion detection, clickstream analysis, recommendation systems, and social network moderation. Among open-source libraries for outlier detection, the Python Outlier Detection (PyOD) library is the most widely adopted, with over 8,500 GitHub stars, 25 million downloads, and diverse industry usage. However, PyOD currently faces three limitations: (1) insufficient coverage of modern deep learning algorithms, (2) fragmented implementations across PyTorch and TensorFlow, and (3) no automated model selection, making it hard for non-experts. To address these issues, we present PyOD Version 2 (PyOD 2), which integrates 12 state-of-the-art deep learning models into a unified PyTorch framework and introduces a large language model (LLM)-based pipeline for automated OD model selection. These improvements simplify OD workflows, provide access to 45 algorithms, and deliver robust performance on various datasets. In this paper, we demonstrate how PyOD 2 streamlines the deployment and automation of OD models and sets a new standard in both research and industry. PyOD 2 is accessible at [https://github.com/yzhao062/pyod](https://github.com/yzhao062/pyod). This study aligns with the Web Mining and Content Analysis track, addressing topics such as the robustness of Web mining methods and the quality of algorithmically-generated Web data.
NLP-ADBench: NLP Anomaly Detection Benchmark
Dec 06, 2024


Anomaly detection (AD) is a critical machine learning task with diverse applications in web systems, including fraud detection, content moderation, and user behavior analysis. Despite its significance, AD in natural language processing (NLP) remains underexplored, limiting advancements in detecting anomalies in text data such as harmful content, phishing attempts, or spam reviews. In this paper, we introduce NLP-ADBench, the most comprehensive benchmark for NLP anomaly detection (NLP-AD), comprising eight curated datasets and evaluations of nineteen state-of-the-art algorithms. These include three end-to-end methods and sixteen two-step algorithms that apply traditional anomaly detection techniques to language embeddings generated by bert-base-uncased and OpenAI's text-embedding-3-large models. Our results reveal critical insights and future directions for NLP-AD. Notably, no single model excels across all datasets, highlighting the need for automated model selection. Moreover, two-step methods leveraging transformer-based embeddings consistently outperform specialized end-to-end approaches, with OpenAI embeddings demonstrating superior performance over BERT embeddings. By releasing NLP-ADBench at https://github.com/USC-FORTIS/NLP-ADBench, we provide a standardized framework for evaluating NLP-AD methods, fostering the development of innovative approaches. This work fills a crucial gap in the field and establishes a foundation for advancing NLP anomaly detection, particularly in the context of improving the safety and reliability of web-based systems.