 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNodule-DETR: A Novel DETR Architecture with Frequency-Channel Attention for Ultrasound Thyroid Nodule Detection
Jan 05, 2026Thyroid cancer is the most common endocrine malignancy, and its incidence is rising globally. While ultrasound is the preferred imaging modality for detecting thyroid nodules, its diagnostic accuracy is often limited by challenges such as low image contrast and blurred nodule boundaries. To address these issues, we propose Nodule-DETR, a novel detection transformer (DETR) architecture designed for robust thyroid nodule detection in ultrasound images. Nodule-DETR introduces three key innovations: a Multi-Spectral Frequency-domain Channel Attention (MSFCA) module that leverages frequency analysis to enhance features of low-contrast nodules; a Hierarchical Feature Fusion (HFF) module for efficient multi-scale integration; and Multi-Scale Deformable Attention (MSDA) to flexibly capture small and irregularly shaped nodules. We conducted extensive experiments on a clinical dataset of real-world thyroid ultrasound images. The results demonstrate that Nodule-DETR achieves state-of-the-art performance, outperforming the baseline model by a significant margin of 0.149 in mAP@0.5:0.95. The superior accuracy of Nodule-DETR highlights its significant potential for clinical application as an effective tool in computer-aided thyroid diagnosis. The code of work is available at https://github.com/wjj1wjj/Nodule-DETR.
Prior-Guided DETR for Ultrasound Nodule Detection
Jan 05, 2026Accurate detection of ultrasound nodules is essential for the early diagnosis and treatment of thyroid and breast cancers. However, this task remains challenging due to irregular nodule shapes, indistinct boundaries, substantial scale variations, and the presence of speckle noise that degrades structural visibility. To address these challenges, we propose a prior-guided DETR framework specifically designed for ultrasound nodule detection. Instead of relying on purely data-driven feature learning, the proposed framework progressively incorporates different prior knowledge at multiple stages of the network. First, a Spatially-adaptive Deformable FFN with Prior Regularization (SDFPR) is embedded into the CNN backbone to inject geometric priors into deformable sampling, stabilizing feature extraction for irregular and blurred nodules. Second, a Multi-scale Spatial-Frequency Feature Mixer (MSFFM) is designed to extract multi-scale structural priors, where spatial-domain processing emphasizes contour continuity and boundary cues, while frequency-domain modeling captures global morphology and suppresses speckle noise. Furthermore, a Dense Feature Interaction (DFI) mechanism propagates and exploits these prior-modulated features across all encoder layers, enabling the decoder to enhance query refinement under consistent geometric and structural guidance. Experiments conducted on two clinically collected thyroid ultrasound datasets (Thyroid I and Thyroid II) and two public benchmarks (TN3K and BUSI) for thyroid and breast nodules demonstrate that the proposed method achieves superior accuracy compared with 18 detection methods, particularly in detecting morphologically complex nodules.The source code is publicly available at https://github.com/wjj1wjj/Ultrasound-DETR.
An Iterative LLM Framework for SIBT utilizing RAG-based Adaptive Weight Optimization
Sep 10, 2025



Seed implant brachytherapy (SIBT) is an effective cancer treatment modality; however, clinical planning often relies on manual adjustment of objective function weights, leading to inefficiencies and suboptimal results. This study proposes an adaptive weight optimization framework for SIBT planning, driven by large language models (LLMs). A locally deployed DeepSeek-R1 LLM is integrated with an automatic planning algorithm in an iterative loop. Starting with fixed weights, the LLM evaluates plan quality and recommends new weights in the next iteration. This process continues until convergence criteria are met, after which the LLM conducts a comprehensive evaluation to identify the optimal plan. A clinical knowledge base, constructed and queried via retrieval-augmented generation (RAG), enhances the model's domain-specific reasoning. The proposed method was validated on 23 patient cases, showing that the LLM-assisted approach produces plans that are comparable to or exceeding clinically approved and fixed-weight plans, in terms of dose homogeneity for the clinical target volume (CTV) and sparing of organs at risk (OARs). The study demonstrates the potential use of LLMs in SIBT planning automation.
EndoUFM: Utilizing Foundation Models for Monocular depth estimation of endoscopic images
Aug 25, 2025Depth estimation is a foundational component for 3D reconstruction in minimally invasive endoscopic surgeries. However, existing monocular depth estimation techniques often exhibit limited performance to the varying illumination and complex textures of the surgical environment. While powerful visual foundation models offer a promising solution, their training on natural images leads to significant domain adaptability limitations and semantic perception deficiencies when applied to endoscopy. In this study, we introduce EndoUFM, an unsupervised monocular depth estimation framework that innovatively integrating dual foundation models for surgical scenes, which enhance the depth estimation performance by leveraging the powerful pre-learned priors. The framework features a novel adaptive fine-tuning strategy that incorporates Random Vector Low-Rank Adaptation (RVLoRA) to enhance model adaptability, and a Residual block based on Depthwise Separable Convolution (Res-DSC) to improve the capture of fine-grained local features. Furthermore, we design a mask-guided smoothness loss to enforce depth consistency within anatomical tissue structures. Extensive experiments on the SCARED, Hamlyn, SERV-CT, and EndoNeRF datasets confirm that our method achieves state-of-the-art performance while maintaining an efficient model size. This work contributes to augmenting surgeons' spatial perception during minimally invasive procedures, thereby enhancing surgical precision and safety, with crucial implications for augmented reality and navigation systems.
Multi-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
Semantic-CD: Remote Sensing Image Semantic Change Detection towards Open-vocabulary Setting
Jan 12, 2025Remote sensing image semantic change detection is a method used to analyze remote sensing images, aiming to identify areas of change as well as categorize these changes within images of the same location taken at different times. Traditional change detection methods often face challenges in generalizing across semantic categories in practical scenarios. To address this issue, we introduce a novel approach called Semantic-CD, specifically designed for semantic change detection in remote sensing images. This method incorporates the open vocabulary semantics from the vision-language foundation model, CLIP. By utilizing CLIP's extensive vocabulary knowledge, our model enhances its ability to generalize across categories and improves segmentation through fully decoupled multi-task learning, which includes both binary change detection and semantic change detection tasks. Semantic-CD consists of four main components: a bi-temporal CLIP visual encoder for extracting features from bi-temporal images, an open semantic prompter for creating semantic cost volume maps with open vocabulary, a binary change detection decoder for generating binary change detection masks, and a semantic change detection decoder for producing semantic labels. Experimental results on the SECOND dataset demonstrate that Semantic-CD achieves more accurate masks and reduces semantic classification errors, illustrating its effectiveness in applying semantic priors from vision-language foundation models to SCD tasks.
Empirical curvelet based Fully Convolutional Network for supervised texture image segmentation
Oct 28, 2024



In this paper, we propose a new approach to perform supervised texture classification/segmentation. The proposed idea is to feed a Fully Convolutional Network with specific texture descriptors. These texture features are extracted from images by using an empirical curvelet transform. We propose a method to build a unique empirical curvelet filter bank adapted to a given dictionary of textures. We then show that the output of these filters can be used to build efficient texture descriptors utilized to finally feed deep learning networks. Our approach is finally evaluated on several datasets and compare the results to various state-of-the-art algorithms and show that the proposed method dramatically outperform all existing ones.
Review of wavelet-based unsupervised texture segmentation, advantage of adaptive wavelets
Oct 24, 2024Wavelet-based segmentation approaches are widely used for texture segmentation purposes because of their ability to characterize different textures. In this paper, we assess the influence of the chosen wavelet and propose to use the recently introduced empirical wavelets. We show that the adaptability of the empirical wavelet permits to reach better results than classic wavelets. In order to focus only on the textural information, we also propose to perform a cartoon + texture decomposition step before applying the segmentation algorithm. The proposed method is tested on six classic benchmarks, based on several popular texture images.
Advancing Depth Anything Model for Unsupervised Monocular Depth Estimation in Endoscopy
Sep 12, 2024



Depth estimation is a cornerstone of 3D reconstruction and plays a vital role in minimally invasive endoscopic surgeries. However, most current depth estimation networks rely on traditional convolutional neural networks, which are limited in their ability to capture global information. Foundation models offer a promising avenue for enhancing depth estimation, but those currently available are primarily trained on natural images, leading to suboptimal performance when applied to endoscopic images. In this work, we introduce a novel fine-tuning strategy for the Depth Anything Model and integrate it with an intrinsic-based unsupervised monocular depth estimation framework. Our approach includes a low-rank adaptation technique based on random vectors, which improves the model's adaptability to different scales. Additionally, we propose a residual block built on depthwise separable convolution to compensate for the transformer's limited ability to capture high-frequency details, such as edges and textures. Our experimental results on the SCARED dataset show that our method achieves state-of-the-art performance while minimizing the number of trainable parameters. Applying this method in minimally invasive endoscopic surgery could significantly enhance both the precision and safety of these procedures.
Semantic-CC: Boosting Remote Sensing Image Change Captioning via Foundational Knowledge and Semantic Guidance
Jul 19, 2024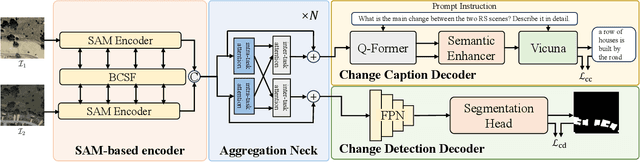


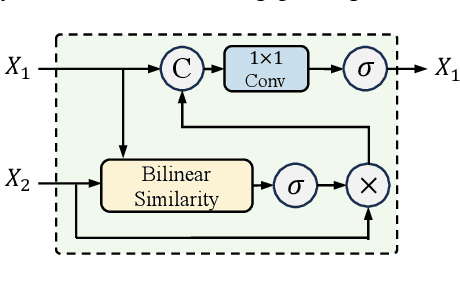
Remote sensing image change captioning (RSICC) aims to articulate the changes in objects of interest within bi-temporal remote sensing images using natural language. Given the limitations of current RSICC methods in expressing general features across multi-temporal and spatial scenarios, and their deficiency in providing granular, robust, and precise change descriptions, we introduce a novel change captioning (CC) method based on the foundational knowledge and semantic guidance, which we term Semantic-CC. Semantic-CC alleviates the dependency of high-generalization algorithms on extensive annotations by harnessing the latent knowledge of foundation models, and it generates more comprehensive and accurate change descriptions guided by pixel-level semantics from change detection (CD). Specifically, we propose a bi-temporal SAM-based encoder for dual-image feature extraction; a multi-task semantic aggregation neck for facilitating information interaction between heterogeneous tasks; a straightforward multi-scale change detection decoder to provide pixel-level semantic guidance; and a change caption decoder based on the large language model (LLM) to generate change description sentences. Moreover, to ensure the stability of the joint training of CD and CC, we propose a three-stage training strategy that supervises different tasks at various stages. We validate the proposed method on the LEVIR-CC and LEVIR-CD datasets. The experimental results corroborate the complementarity of CD and CC, demonstrating that Semantic-CC can generate more accurate change descriptions and achieve optimal performance across both tasks.