 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-CC: Boosting Remote Sensing Image Change Captioning via Foundational Knowledge and Semantic Guidance
Paper and Code
Jul 19, 2024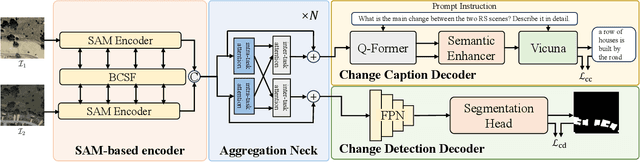


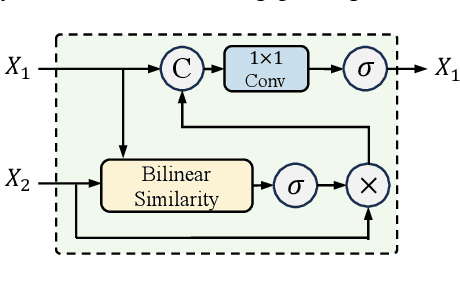
Remote sensing image change captioning (RSICC) aims to articulate the changes in objects of interest within bi-temporal remote sensing images using natural language. Given the limitations of current RSICC methods in expressing general features across multi-temporal and spatial scenarios, and their deficiency in providing granular, robust, and precise change descriptions, we introduce a novel change captioning (CC) method based on the foundational knowledge and semantic guidance, which we term Semantic-CC. Semantic-CC alleviates the dependency of high-generalization algorithms on extensive annotations by harnessing the latent knowledge of foundation models, and it generates more comprehensive and accurate change descriptions guided by pixel-level semantics from change detection (CD). Specifically, we propose a bi-temporal SAM-based encoder for dual-image feature extraction; a multi-task semantic aggregation neck for facilitating information interaction between heterogeneous tasks; a straightforward multi-scale change detection decoder to provide pixel-level semantic guidance; and a change caption decoder based on the large language model (LLM) to generate change description sentences. Moreover, to ensure the stability of the joint training of CD and CC, we propose a three-stage training strategy that supervises different tasks at various stages. We validate the proposed method on the LEVIR-CC and LEVIR-CD datasets. The experimental results corroborate the complementarity of CD and CC, demonstrating that Semantic-CC can generate more accurate change descriptions and achieve optimal performance across both tasks.