 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaEarth-MM: Unified Multimodal Remote Sensing Image Generation with Scene-centered Joint Modeling
May 19, 2026Multi-modal remote sensing images are vital for Earth observation, yet complete paired observations are often scarce in practice. Existing generative methods commonly address this problem through isolated pairwise modality translation, but their versatility and scalability remain limited as the number of modalities and generation tasks increases. Here, we develop a generative foundation model MetaEarth-MM for multi-modal remote sensing imagery, enabling paired joint generation and any-to-any translation across five modalities within a unified model. Recognizing the intrinsic scene consistency underlying multi-modal observations, we introduce a scene-centered joint modeling paradigm in MetaEarth-MM. Unlike previous methods that rely on direct appearance-level cross-modal mapping, our model organizes the generation around the underlying scene content. Specifically, MetaEarth-MM adopts a decoupled architecture that first infers a latent scene representation from available observations, and then generates target modalities conditioned on this intermediate state. To support training, we further construct EarthMM, a large-scale dataset comprising 2.8 million multi-resolution global images with 2.2 million aligned pairs. Extensive experiments demonstrate that MetaEarth-MM not only exhibits strong generative capability and robust generalization across diverse generation tasks, but also supports downstream tasks at both data and representation levels, highlighting its potential as a general foundation model for cross-modal Earth observation. The code and dataset will be available at https://github.com/YZPioneer/MetaEarth-MM.
HiSem: Hierarchical Semantic Disentangling for Remote Sensing Image Change Captioning
May 14, 2026Remote sensing image change captioning (RSICC) aims to achieve high-level semantic understanding of genuine changes occurring between bi-temporal images. Despite notable progress, existing methods are fundamentally limited by a shared modeling assumption: changed and unchanged image pairs, which have intrinsically different semantic granularities, are processed under a unified modeling strategy. This modeling inconsistency leads to semantic entanglement between coarse-grained change existence judgment and fine-grained semantic understanding.To address the above limitation, we propose a novel hierarchical semantic disentangling network (HiSem) that explicitly disentangles semantic representations of different granularities. Specifically, we first introduce the Bidirectional Differential Attention Modulation (BDAM) module that leverages discrepancy-aware attention to enhance cross-temporal interactions, thereby amplifying true change signals while suppressing irrelevant variations. Building upon this, we design a Hierarchical Adaptive Semantic Disentanglement (HASD) module that performs adaptive routing at two hierarchical levels: a coarse-grained image-level routing mechanism distinguishes changed and unchanged image pairs, while a fine-grained token-level Mixture-of-Experts (MoE) block models diverse and heterogeneous change semantics for changed samples. Extensive experiments on two benchmark datasets demonstrate that HiSem outperfoms previous methods, achieving a significant improvement of +7.52\% BLEU-4 on the WHU-CDC dataset. More importantly, our approach provides a structured perspective for RSICC by explicitly aligning model design with the intrinsic semantic heterogeneity of bi-temporal scenes. The code will be available at https://github.com/Man-Wang-star/HiSem
CloudMamba: An Uncertainty-Guided Dual-Scale Mamba Network for Cloud Detection in Remote Sensing Imagery
Apr 08, 2026Cloud detection in remote sensing imagery is a fundamental, critical, and highly challenging problem. Existing deep learning-based cloud detection methods generally formulate it as a single-stage pixel-wise binary segmentation task with one forward pass. However, such single-stage approaches exhibit ambiguity and uncertainty in thin-cloud regions and struggle to accurately handle fragmented clouds and boundary details. In this paper, we propose a novel deep learning framework termed CloudMamba. To address the ambiguity in thin-cloud regions, we introduce an uncertainty-guided two-stage cloud detection strategy. An embedded uncertainty estimation module is proposed to automatically quantify the confidence of thin-cloud segmentation, and a second-stage refinement segmentation is introduced to improve the accuracy in low-confidence hard regions. To better handle fragmented clouds and fine-grained boundary details, we design a dual-scale Mamba network based on a CNN-Mamba hybrid architecture. Compared with Transformer-based models with quadratic computational complexity, the proposed method maintains linear computational complexity while effectively capturing both large-scale structural characteristics and small-scale boundary details of clouds, enabling accurate delineation of overall cloud morphology and precise boundary segmentation. Extensive experiments conducted on the GF1_WHU and Levir_CS public datasets demonstrate that the proposed method outperforms existing approaches across multiple segmentation accuracy metrics, while offering high efficiency and process transparency. Our code is available at https://github.com/jayoungo/CloudMamba.
Think and Answer ME: Benchmarking and Exploring Multi-Entity Reasoning Grounding in Remote Sensing
Mar 13, 2026Recent advances in reasoning language models and reinforcement learning with verifiable rewards have significantly enhanced multi-step reasoning capabilities. This progress motivates the extension of reasoning paradigms to remote sensing visual grounding task. However, existing remote sensing grounding methods remain largely confined to perception-level matching and single-entity formulations, limiting the role of explicit reasoning and inter-entity modeling. To address this challenge, we introduce a new benchmark dataset for Multi-Entity Reasoning Grounding in Remote Sensing (ME-RSRG). Based on ME-RSRG, we reformulate remote sensing grounding as a multi-entity reasoning task and propose an Entity-Aware Reasoning (EAR) framework built upon visual-linguistic foundation models. EAR generates structured reasoning traces and subject-object grounding outputs. It adopts supervised fine-tuning for cold-start initialization and is further optimized via entity-aware reward-driven Group Relative Policy Optimization (GRPO). Extensive experiments on ME-RSRG demonstrate the challenges of multi-entity reasoning and verify the effectiveness of our proposed EAR framework. Our dataset, code, and models will be available at https://github.com/CV-ShuchangLyu/ME-RSRG.
BRIGHT: A Collaborative Generalist-Specialist Foundation Model for Breast Pathology
Mar 03, 2026Generalist pathology foundation models (PFMs), pretrained on large-scale multi-organ datasets, have demonstrated remarkable predictive capabilities across diverse clinical applications. However, their proficiency on the full spectrum of clinically essential tasks within a specific organ system remains an open question due to the lack of large-scale validation cohorts for a single organ as well as the absence of a tailored training paradigm that can effectively translate broad histomorphological knowledge into the organ-specific expertise required for specialist-level interpretation. In this study, we propose BRIGHT, the first PFM specifically designed for breast pathology, trained on approximately 210 million histopathology tiles from over 51,000 breast whole-slide images derived from a cohort of over 40,000 patients across 19 hospitals. BRIGHT employs a collaborative generalist-specialist framework to capture both universal and organ-specific features. To comprehensively evaluate the performance of PFMs on breast oncology, we curate the largest multi-institutional cohorts to date for downstream task development and evaluation, comprising over 25,000 WSIs across 10 hospitals. The validation cohorts cover the full spectrum of breast pathology across 24 distinct clinical tasks spanning diagnosis, biomarker prediction, treatment response and survival prediction. Extensive experiments demonstrate that BRIGHT outperforms three leading generalist PFMs, achieving state-of-the-art (SOTA) performance in 21 of 24 internal validation tasks and in 5 of 10 external validation tasks with excellent heatmap interpretability. By evaluating on large-scale validation cohorts, this study not only demonstrates BRIGHT's clinical utility in breast oncology but also validates a collaborative generalist-specialist paradigm, providing a scalable template for developing PFMs on a specific organ system.
Remodeling Semantic Relationships in Vision-Language Fine-Tuning
Nov 13, 2025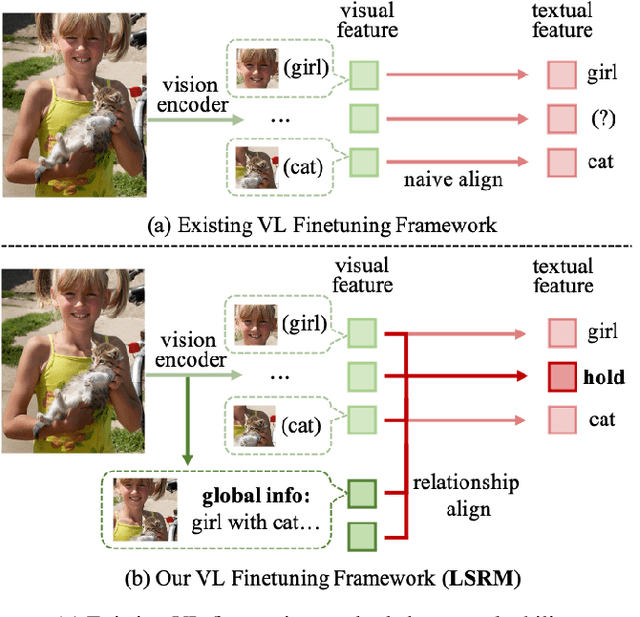

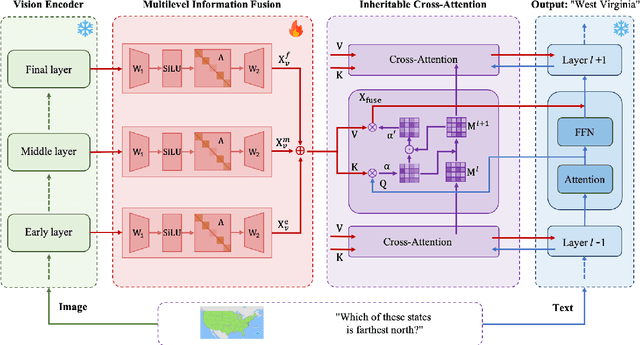

Vision-language fine-tuning has emerged as an efficient paradigm for constructing multimodal foundation models. While textual context often highlights semantic relationships within an image, existing fine-tuning methods typically overlook this information when aligning vision and language, thus leading to suboptimal performance. Toward solving this problem, we propose a method that can improve multimodal alignment and fusion based on both semantics and relationships.Specifically, we first extract multilevel semantic features from different vision encoder to capture more visual cues of the relationships. Then, we learn to project the vision features to group related semantics, among which are more likely to have relationships. Finally, we fuse the visual features with the textual by using inheritable cross-attention, where we globally remove the redundant visual relationships by discarding visual-language feature pairs with low correlation. We evaluate our proposed method on eight foundation models and two downstream tasks, visual question answering and image captioning, and show that it outperforms all existing methods.
FoBa: A Foreground-Background co-Guided Method and New Benchmark for Remote Sensing Semantic Change Detection
Sep 19, 2025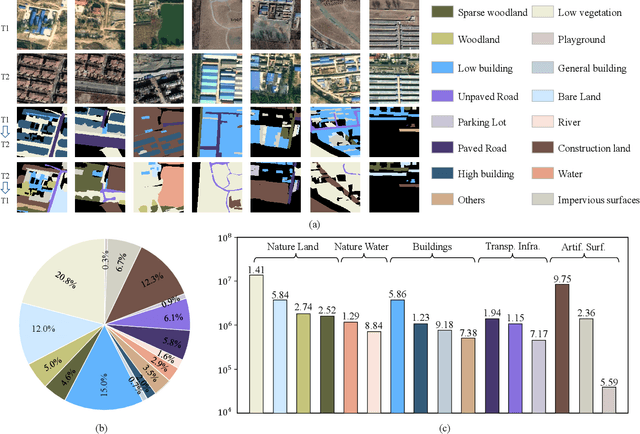

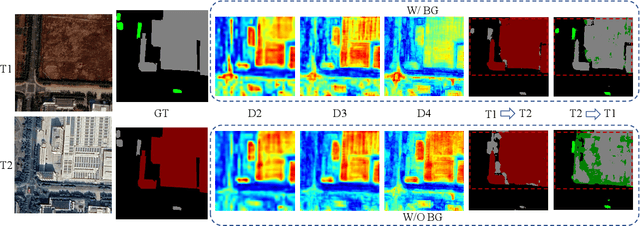
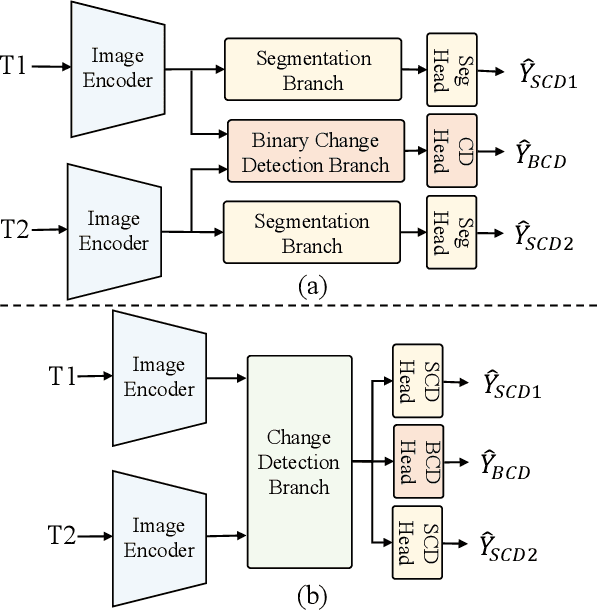
Despite the remarkable progress achieved in remote sensing semantic change detection (SCD), two major challenges remain. At the data level, existing SCD datasets suffer from limited change categories, insufficient change types, and a lack of fine-grained class definitions, making them inadequate to fully support practical applications. At the methodological level, most current approaches underutilize change information, typically treating it as a post-processing step to enhance spatial consistency, which constrains further improvements in model performance. To address these issues, we construct a new benchmark for remote sensing SCD, LevirSCD. Focused on the Beijing area, the dataset covers 16 change categories and 210 specific change types, with more fine-grained class definitions (e.g., roads are divided into unpaved and paved roads). Furthermore, we propose a foreground-background co-guided SCD (FoBa) method, which leverages foregrounds that focus on regions of interest and backgrounds enriched with contextual information to guide the model collaboratively, thereby alleviating semantic ambiguity while enhancing its ability to detect subtle changes. Considering the requirements of bi-temporal interaction and spatial consistency in SCD, we introduce a Gated Interaction Fusion (GIF) module along with a simple consistency loss to further enhance the model's detection performance. Extensive experiments on three datasets (SECOND, JL1, and the proposed LevirSCD) demonstrate that FoBa achieves competitive results compared to current SOTA methods, with improvements of 1.48%, 3.61%, and 2.81% in the SeK metric, respectively. Our code and dataset are available at https://github.com/zmoka-zht/FoBa.
Preserving Domain Generalization in Fine-Tuning via Joint Parameter Selection
Aug 23, 2025Domain generalization seeks to develop models trained on a limited set of source domains that are capable of generalizing effectively to unseen target domains. While the predominant approach leverages large-scale pre-trained vision models as initialization, recent studies have highlighted that full fine-tuning can compromise the intrinsic generalization capabilities of these models. To address this limitation, parameter-efficient adaptation strategies have emerged, wherein only a subset of model parameters is selectively fine-tuned, thereby balancing task adaptation with the preservation of generalization. Motivated by this paradigm, we introduce Joint Parameter Selection (JPS), a novel method that restricts updates to a small, sparse subset of parameters, thereby retaining and harnessing the generalization strength of pre-trained models. Theoretically, we establish a generalization error bound that explicitly accounts for the sparsity of parameter updates, thereby providing a principled justification for selective fine-tuning. Practically, we design a selection mechanism employing dual operators to identify and update parameters exhibiting consistent and significant gradients across all source domains. Extensive benchmark experiments demonstrate that JPS achieves superior performance compared to state-of-the-art domain generalization methods, substantiating both the efficiency and efficacy of the proposed approach.
RSRefSeg 2: Decoupling Referring Remote Sensing Image Segmentation with Foundation Models
Jul 08, 2025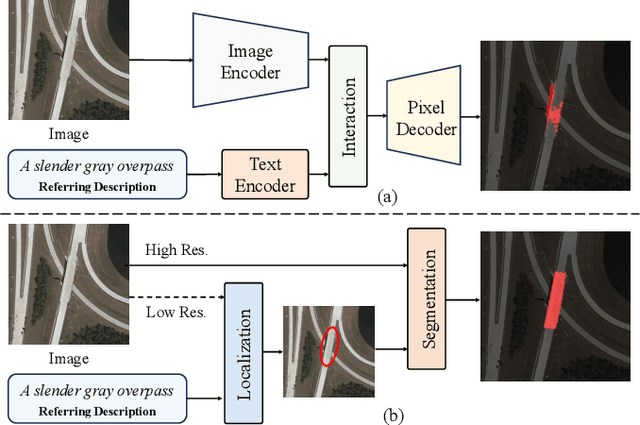
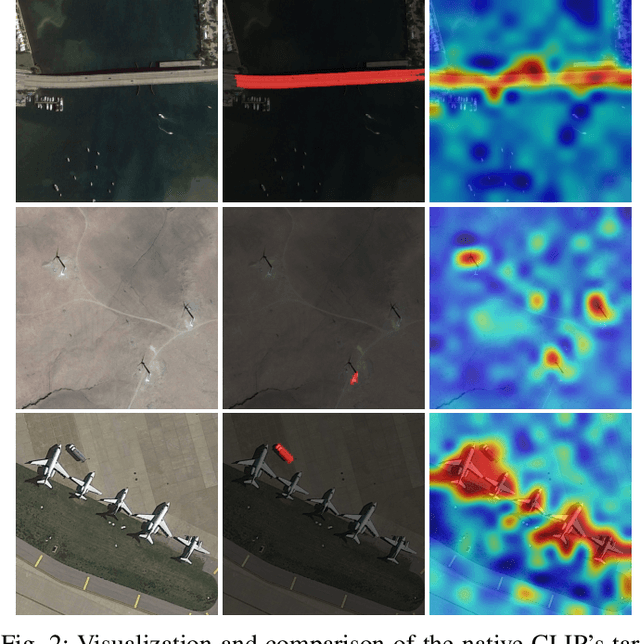
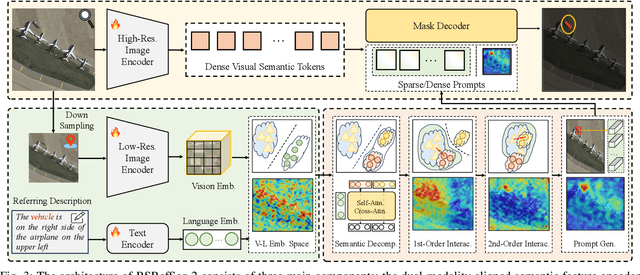
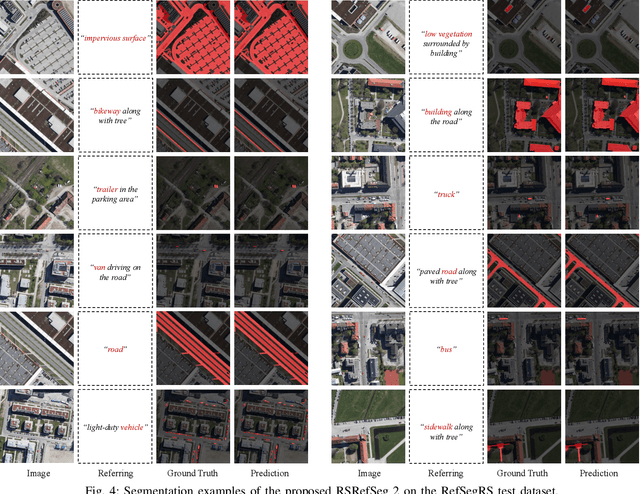
Referring Remote Sensing Image Segmentation provides a flexible and fine-grained framework for remote sensing scene analysis via vision-language collaborative interpretation. Current approaches predominantly utilize a three-stage pipeline encompassing dual-modal encoding, cross-modal interaction, and pixel decoding. These methods demonstrate significant limitations in managing complex semantic relationships and achieving precise cross-modal alignment, largely due to their coupled processing mechanism that conflates target localization with boundary delineation. This architectural coupling amplifies error propagation under semantic ambiguity while restricting model generalizability and interpretability. To address these issues, we propose RSRefSeg 2, a decoupling paradigm that reformulates the conventional workflow into a collaborative dual-stage framework: coarse localization followed by fine segmentation. RSRefSeg 2 integrates CLIP's cross-modal alignment strength with SAM's segmentation generalizability through strategic foundation model collaboration. Specifically, CLIP is employed as the dual-modal encoder to activate target features within its pre-aligned semantic space and generate localization prompts. To mitigate CLIP's misactivation challenges in multi-entity scenarios described by referring texts, a cascaded second-order prompter is devised, which enhances precision through implicit reasoning via decomposition of text embeddings into complementary semantic subspaces. These optimized semantic prompts subsequently direct the SAM to generate pixel-level refined masks, thereby completing the semantic transmission pipeline. Extensive experiments (RefSegRS, RRSIS-D, and RISBench) demonstrate that RSRefSeg 2 surpasses contemporary methods in segmentation accuracy (+~3% gIoU) and complex semantic interpretation. Code is available at: https://github.com/KyanChen/RSRefSeg2.
Fine-grained Hierarchical Crop Type Classification from Integrated Hyperspectral EnMAP Data and Multispectral Sentinel-2 Time Series: A Large-scale Dataset and Dual-stream Transformer Method
Jun 09, 2025Fine-grained crop type classification serves as the fundamental basis for large-scale crop mapping and plays a vital role in ensuring food security. It requires simultaneous capture of both phenological dynamics (obtained from multi-temporal satellite data like Sentinel-2) and subtle spectral variations (demanding nanometer-scale spectral resolution from hyperspectral imagery). Research combining these two modalities remains scarce currently due to challenges in hyperspectral data acquisition and crop types annotation costs. To address these issues, we construct a hierarchical hyperspectral crop dataset (H2Crop) by integrating 30m-resolution EnMAP hyperspectral data with Sentinel-2 time series. With over one million annotated field parcels organized in a four-tier crop taxonomy, H2Crop establishes a vital benchmark for fine-grained agricultural crop classification and hyperspectral image processing. We propose a dual-stream Transformer architecture that synergistically processes these modalities. It coordinates two specialized pathways: a spectral-spatial Transformer extracts fine-grained signatures from hyperspectral EnMAP data, while a temporal Swin Transformer extracts crop growth patterns from Sentinel-2 time series. The designed hierarchical classification head with hierarchical fusion then simultaneously delivers multi-level crop type classification across all taxonomic tiers. Experiments demonstrate that adding hyperspectral EnMAP data to Sentinel-2 time series yields a 4.2% average F1-scores improvement (peaking at 6.3%). Extensive comparisons also confirm our method's higher accuracy over existing deep learning approaches for crop type classification and the consistent benefits of hyperspectral data across varying temporal windows and crop change scenarios. Codes and dataset are available at https://github.com/flyakon/H2Crop.