 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIGHT: A Collaborative Generalist-Specialist Foundation Model for Breast Pathology
Mar 03, 2026Generalist pathology foundation models (PFMs), pretrained on large-scale multi-organ datasets, have demonstrated remarkable predictive capabilities across diverse clinical applications. However, their proficiency on the full spectrum of clinically essential tasks within a specific organ system remains an open question due to the lack of large-scale validation cohorts for a single organ as well as the absence of a tailored training paradigm that can effectively translate broad histomorphological knowledge into the organ-specific expertise required for specialist-level interpretation. In this study, we propose BRIGHT, the first PFM specifically designed for breast pathology, trained on approximately 210 million histopathology tiles from over 51,000 breast whole-slide images derived from a cohort of over 40,000 patients across 19 hospitals. BRIGHT employs a collaborative generalist-specialist framework to capture both universal and organ-specific features. To comprehensively evaluate the performance of PFMs on breast oncology, we curate the largest multi-institutional cohorts to date for downstream task development and evaluation, comprising over 25,000 WSIs across 10 hospitals. The validation cohorts cover the full spectrum of breast pathology across 24 distinct clinical tasks spanning diagnosis, biomarker prediction, treatment response and survival prediction. Extensive experiments demonstrate that BRIGHT outperforms three leading generalist PFMs, achieving state-of-the-art (SOTA) performance in 21 of 24 internal validation tasks and in 5 of 10 external validation tasks with excellent heatmap interpretability. By evaluating on large-scale validation cohorts, this study not only demonstrates BRIGHT's clinical utility in breast oncology but also validates a collaborative generalist-specialist paradigm, providing a scalable template for developing PFMs on a specific organ system.
Semi-distributed Cross-modal Air-Ground Relative Localization
Nov 10, 2025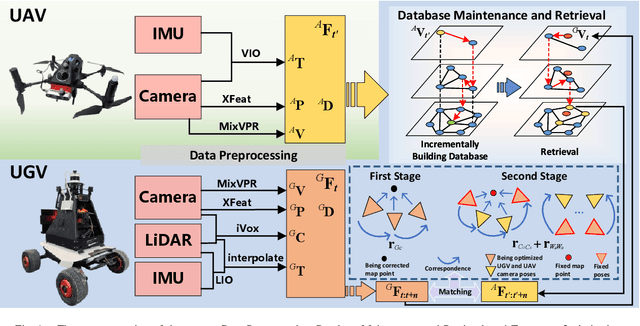
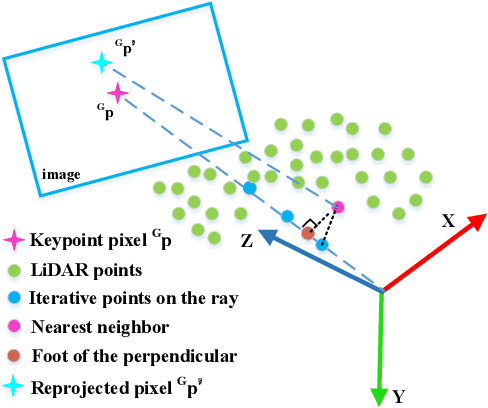

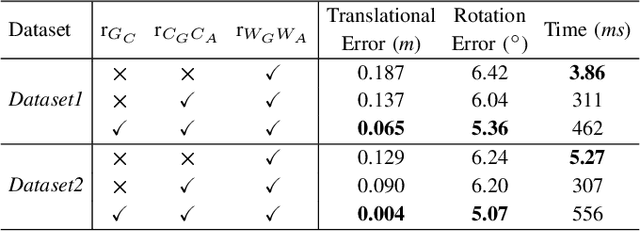
Efficient, accurate, and flexible relative localization is crucial in air-ground collaborative tasks. However, current approaches for robot relative localization are primarily realized in the form of distributed multi-robot SLAM systems with the same sensor configuration, which are tightly coupled with the state estimation of all robots, limiting both flexibility and accuracy. To this end, we fully leverage the high capacity of Unmanned Ground Vehicle (UGV) to integrate multiple sensors, enabling a semi-distributed cross-modal air-ground relative localization framework. In this work, both the UGV and the Unmanned Aerial Vehicle (UAV) independently perform SLAM while extracting deep learning-based keypoints and global descriptors, which decouples the relative localization from the state estimation of all agents. The UGV employs a local Bundle Adjustment (BA) with LiDAR, camera, and an IMU to rapidly obtain accurate relative pose estimates. The BA process adopts sparse keypoint optimization and is divided into two stages: First, optimizing camera poses interpolated from LiDAR-Inertial Odometry (LIO), followed by estimating the relative camera poses between the UGV and UAV. Additionally, we implement an incremental loop closure detection algorithm using deep learning-based descriptors to maintain and retrieve keyframes efficiently. Experimental results demonstrate that our method achieves outstanding performance in both accuracy and efficiency. Unlike traditional multi-robot SLAM approaches that transmit images or point clouds, our method only transmits keypoint pixels and their descriptors, effectively constraining the communication bandwidth under 0.3 Mbps. Codes and data will be publicly available on https://github.com/Ascbpiac/cross-model-relative-localization.git.
Collaborative Learning of Scattering and Deep Features for SAR Target Recognition with Noisy Labels
Aug 11, 2025



The acquisition of high-quality labeled synthetic aperture radar (SAR) data is challenging due to the demanding requirement for expert knowledge. Consequently, the presence of unreliable noisy labels is unavoidable, which results in performance degradation of SAR automatic target recognition (ATR). Existing research on learning with noisy labels mainly focuses on image data. However, the non-intuitive visual characteristics of SAR data are insufficient to achieve noise-robust learning. To address this problem, we propose collaborative learning of scattering and deep features (CLSDF) for SAR ATR with noisy labels. Specifically, a multi-model feature fusion framework is designed to integrate scattering and deep features. The attributed scattering centers (ASCs) are treated as dynamic graph structure data, and the extracted physical characteristics effectively enrich the representation of deep image features. Then, the samples with clean and noisy labels are divided by modeling the loss distribution with multiple class-wise Gaussian Mixture Models (GMMs). Afterward, the semi-supervised learning of two divergent branches is conducted based on the data divided by each other. Moreover, a joint distribution alignment strategy is introduced to enhance the reliability of co-guessed labels. Extensive experiments have been done on the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset, and the results show that the proposed method can achieve state-of-the-art performance under different operating conditions with various label noises.
Towards Computation- and Communication-efficient Computational Pathology
Apr 03, 2025Despite the impressive performance across a wide range of applications, current computational pathology models face significant diagnostic efficiency challenges due to their reliance on high-magnification whole-slide image analysis. This limitation severely compromises their clinical utility, especially in time-sensitive diagnostic scenarios and situations requiring efficient data transfer. To address these issues, we present a novel computation- and communication-efficient framework called Magnification-Aligned Global-Local Transformer (MAGA-GLTrans). Our approach significantly reduces computational time, file transfer requirements, and storage overhead by enabling effective analysis using low-magnification inputs rather than high-magnification ones. The key innovation lies in our proposed magnification alignment (MAGA) mechanism, which employs self-supervised learning to bridge the information gap between low and high magnification levels by effectively aligning their feature representations. Through extensive evaluation across various fundamental CPath tasks, MAGA-GLTrans demonstrates state-of-the-art classification performance while achieving remarkable efficiency gains: up to 10.7 times reduction in computational time and over 20 times reduction in file transfer and storage requirements. Furthermore, we highlight the versatility of our MAGA framework through two significant extensions: (1) its applicability as a feature extractor to enhance the efficiency of any CPath architecture, and (2) its compatibility with existing foundation models and histopathology-specific encoders, enabling them to process low-magnification inputs with minimal information loss. These advancements position MAGA-GLTrans as a particularly promising solution for time-sensitive applications, especially in the context of intraoperative frozen section diagnosis where both accuracy and efficiency are paramount.
Inverse Kinematics and Dexterous Workspace Formulation for 2-Segment Continuum Robots with Inextensible Segments
Oct 05, 2021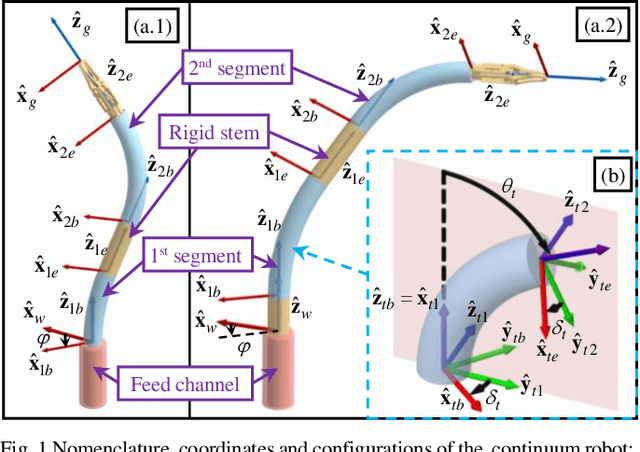
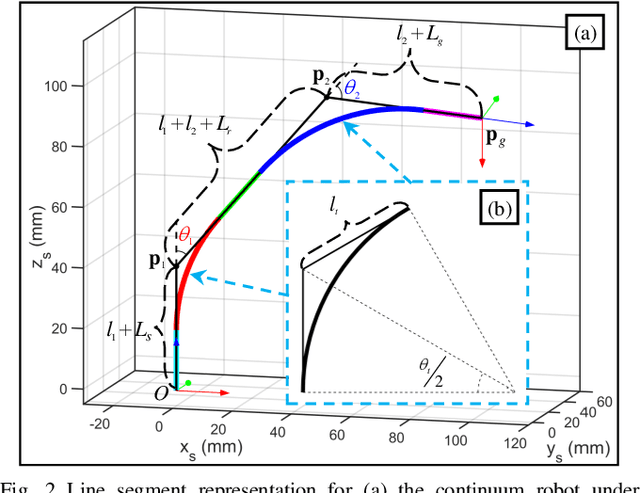
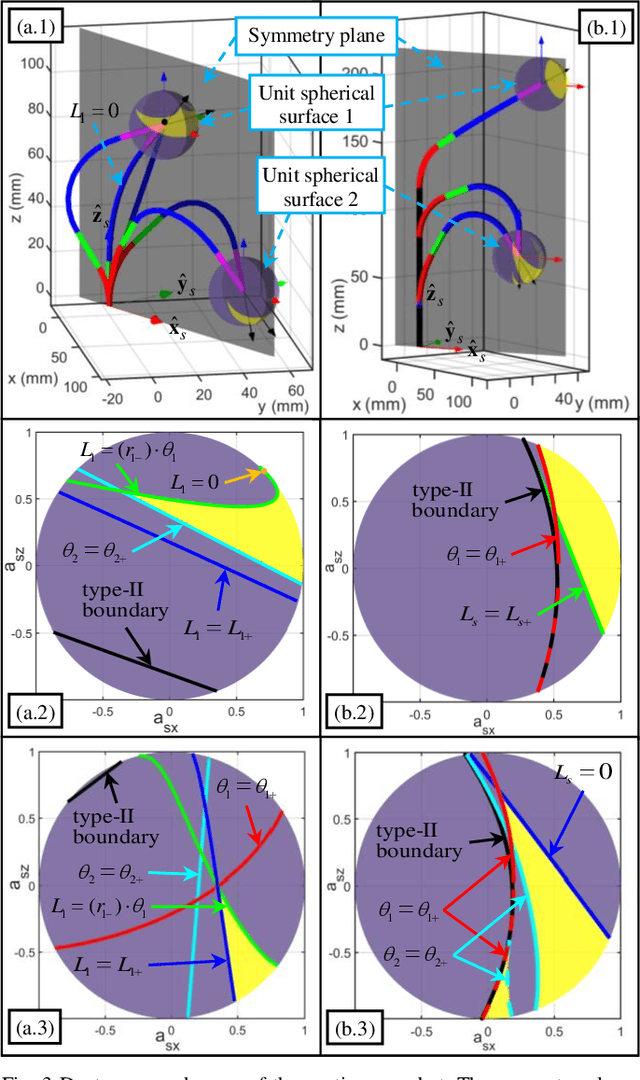
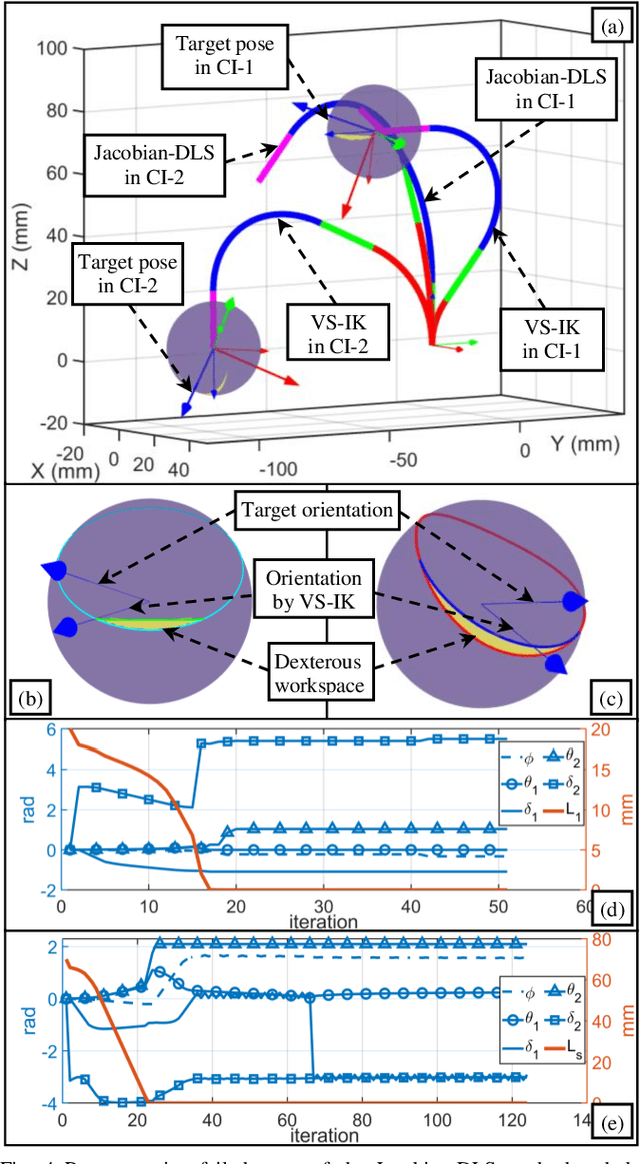
The inverse kinematics (IK) problem of continuum robots has been investigated in depth in the past decades. Under the constant-curvature bending assumption, closed-form IK solution has been obtained for continuum robots with variable segment lengths. Attempting to close the gap towards a complete solution, this paper presents an efficient solution for the IK problem of 2-segment continuum robots with one or two inextensible segments (a.k.a, constant segment lengths). Via representing the robot's shape as piecewise line segments, the configuration variables are separated from the IK formulation such that solving a one-variable nonlinear equation leads to the solution of the entire IK problem. Furthermore, an in-depth investigation of the boundaries of the dexterous workspace of the end effector caused by the configuration variables limits as well as the angular velocity singularities of the continuum robots was established. This dexterous workspace formulation, which is derived for the first time to the best of the authors' knowledge, is particularly useful to find the closest orientation to a target pose when the target orientation is out of the dexterous workspace. In the comparative simulation studies between the proposed method and the Jacobian-based IK method involving 500,000 cases, the proposed variable separation method solved 100% of the IK problems with much higher computational efficiency.
A Two-stream End-to-End Deep Learning Network for Recognizing Atypical Visual Attention in Autism Spectrum Disorder
Nov 26, 2019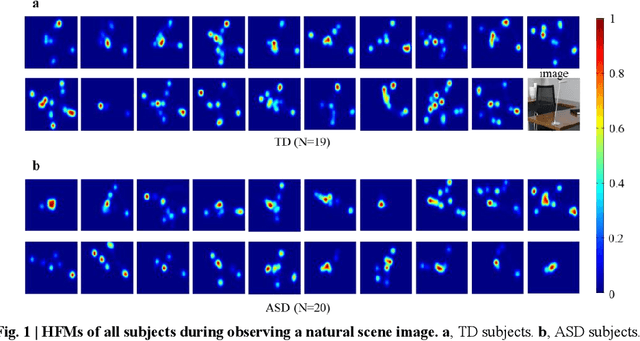
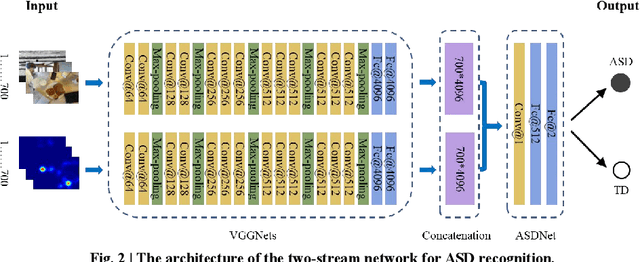
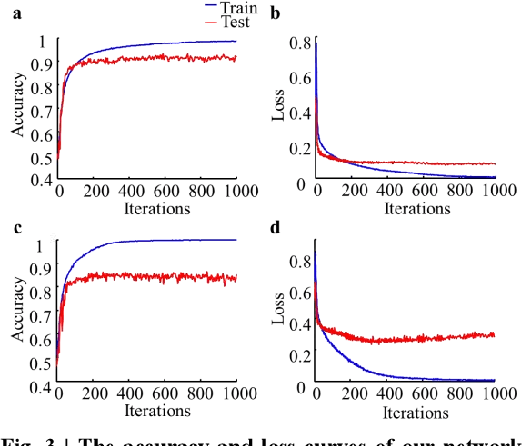
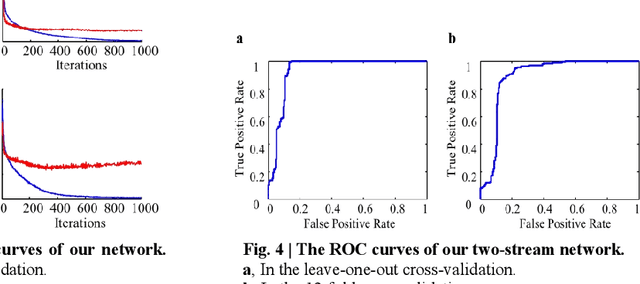
Eye movements have been widely investigated to study the atypical visual attention in Autism Spectrum Disorder (ASD). The majority of these studies have been focused on limited eye movement features by statistical comparisons between ASD and Typically Developing (TD) groups, which make it difficult to accurately separate ASD from TD at the individual level. The deep learning technology has been highly successful in overcoming this issue by automatically extracting features important for classification through a data-driven learning process. However, there is still a lack of end-to-end deep learning framework for recognition of abnormal attention in ASD. In this study, we developed a novel two-stream deep learning network for this recognition based on 700 images and corresponding eye movement patterns of ASD and TD, and obtained an accuracy of 0.95, which was higher than the previous state-of-the-art. We next characterized contributions to the classification at the single image level and non-linearly integration of this single image level information during the classification. Moreover, we identified a group of pixel-level visual features within these images with greater impacts on the classification. Together, this two-stream deep learning network provides us a novel and powerful tool to recognize and understand abnormal visual attention in ASD.
Solving a New 3D Bin Packing Problem with Deep Reinforcement Learning Method
Aug 20, 2017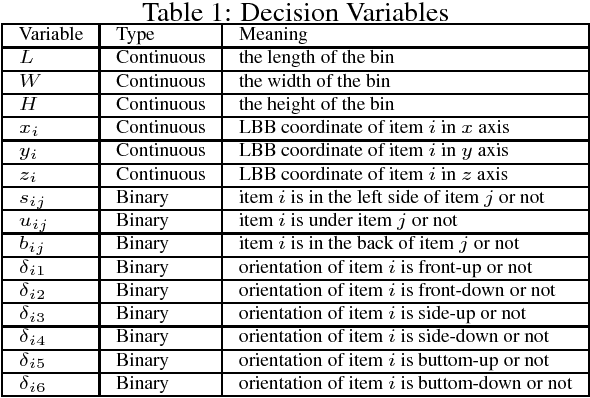
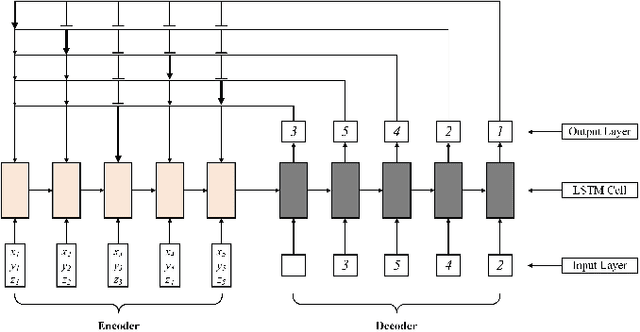
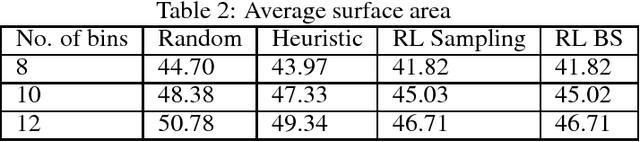
In this paper, a new type of 3D bin packing problem (BPP) is proposed, in which a number of cuboid-shaped items must be put into a bin one by one orthogonally. The objective is to find a way to place these items that can minimize the surface area of the bin. This problem is based on the fact that there is no fixed-sized bin in many real business scenarios and the cost of a bin is proportional to its surface area. Our research shows that this problem is NP-hard. Based on previous research on 3D BPP, the surface area is determined by the sequence, spatial locations and orientations of items. Among these factors, the sequence of items plays a key role in minimizing the surface area. Inspired by recent achievements of deep reinforcement learning (DRL) techniques, especially Pointer Network, on combinatorial optimization problems such as TSP, a DRL-based method is applied to optimize the sequence of items to be packed into the bin. Numerical results show that the method proposed in this paper achieve about 5% improvement than heuristic method.