 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Computation- and Communication-efficient Computational Pathology
Apr 03, 2025Despite the impressive performance across a wide range of applications, current computational pathology models face significant diagnostic efficiency challenges due to their reliance on high-magnification whole-slide image analysis. This limitation severely compromises their clinical utility, especially in time-sensitive diagnostic scenarios and situations requiring efficient data transfer. To address these issues, we present a novel computation- and communication-efficient framework called Magnification-Aligned Global-Local Transformer (MAGA-GLTrans). Our approach significantly reduces computational time, file transfer requirements, and storage overhead by enabling effective analysis using low-magnification inputs rather than high-magnification ones. The key innovation lies in our proposed magnification alignment (MAGA) mechanism, which employs self-supervised learning to bridge the information gap between low and high magnification levels by effectively aligning their feature representations. Through extensive evaluation across various fundamental CPath tasks, MAGA-GLTrans demonstrates state-of-the-art classification performance while achieving remarkable efficiency gains: up to 10.7 times reduction in computational time and over 20 times reduction in file transfer and storage requirements. Furthermore, we highlight the versatility of our MAGA framework through two significant extensions: (1) its applicability as a feature extractor to enhance the efficiency of any CPath architecture, and (2) its compatibility with existing foundation models and histopathology-specific encoders, enabling them to process low-magnification inputs with minimal information loss. These advancements position MAGA-GLTrans as a particularly promising solution for time-sensitive applications, especially in the context of intraoperative frozen section diagnosis where both accuracy and efficiency are paramount.
FedDBL: Communication and Data Efficient Federated Deep-Broad Learning for Histopathological Tissue Classification
Feb 24, 2023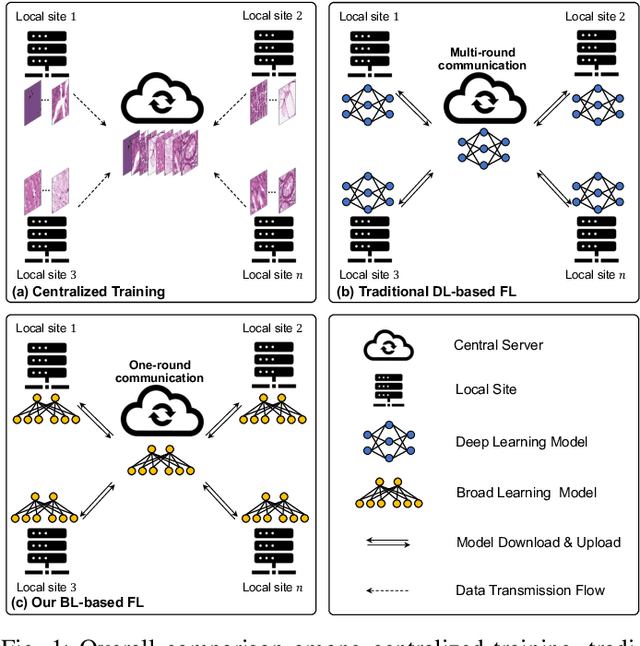
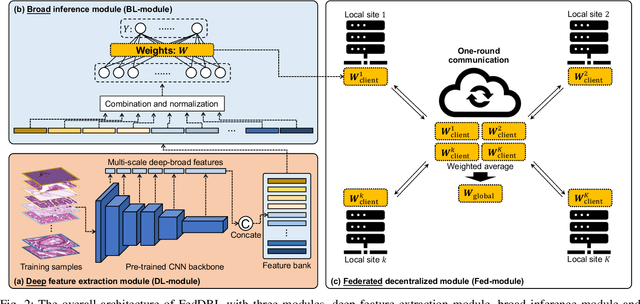
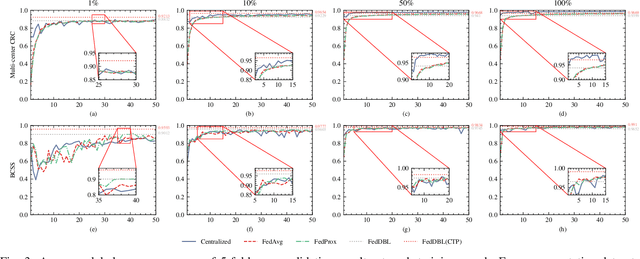

Histopathological tissue classification is a fundamental task in computational pathology. Deep learning-based models have achieved superior performance but centralized training with data centralization suffers from the privacy leakage problem. Federated learning (FL) can safeguard privacy by keeping training samples locally, but existing FL-based frameworks require a large number of well-annotated training samples and numerous rounds of communication which hinder their practicability in the real-world clinical scenario. In this paper, we propose a universal and lightweight federated learning framework, named Federated Deep-Broad Learning (FedDBL), to achieve superior classification performance with limited training samples and only one-round communication. By simply associating a pre-trained deep learning feature extractor, a fast and lightweight broad learning inference system and a classical federated aggregation approach, FedDBL can dramatically reduce data dependency and improve communication efficiency. Five-fold cross-validation demonstrates that FedDBL greatly outperforms the competitors with only one-round communication and limited training samples, while it even achieves comparable performance with the ones under multiple-round communications. Furthermore, due to the lightweight design and one-round communication, FedDBL reduces the communication burden from 4.6GB to only 276.5KB per client using the ResNet-50 backbone at 50-round training. Since no data or deep model sharing across different clients, the privacy issue is well-solved and the model security is guaranteed with no model inversion attack risk. Code is available at https://github.com/tianpeng-deng/FedDBL.