 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniOpt: Reasoning to Model and Solve General Optimization Problems with Limited Resources
Jun 25, 2026Achieving strong optimization generalization across diverse optimization problems while requiring limited training resources remains a challenging problem for optimization-oriented large language models (LLMs). Existing approaches typically rely on large-scale supervised datasets, costly reasoning annotations, and expensive intermediate step verification, resulting in substantial training overhead. To address these challenges, we propose MiniOpt, a reinforcement learning framework that learns to solve optimization problems through an "reasoning-to-model-and-solve" paradigm. MiniOpt decomposes optimization reasoning into structured optimization modeling and executable solver generation. Building upon this paradigm, we introduce OptReward, a reward function with hierarchical score structure that jointly evaluates formulation and solution, enabling effective policy learning without expert demonstrations. We further develop an optimization-oriented policy optimization strategy that improves exploration efficiency and stabilizes reinforcement learning for compact models. Extensive experiments show that MiniOpt-3B exhibits strong optimization generalization across various optimization types, problem scenarios, and task domains. For models with fewer than 10B parameters, MiniOpt series achieves the highest average solving accuracy (SA). For models with more than 10B parameters, MiniOpt still shows competitive performance. These results suggest that optimization-oriented reward design and reinforcement learning provide an effective pathway for developing compact optimization-specialized language models with strong optimization generalization capabilities. The code is available at https://github.com/Hsiang-1/MiniOpt.
OptSkills: Learning Generalizable Optimization Skills from Problem Archetypes via Cluster-Based Distillation
May 28, 2026Leveraging Large Language Models (LLMs) to automatically formulate and solve optimization problems from natural language has emerged as an efficient paradigm for automated optimization. However, existing methods still exhibit limited generalization: they are sensitive to superficial narrative variations, reuse experience mainly at the case level, and struggle to adapt to shifted or emerging problem types. We propose OptSkills, an archetype-centric skill learning and reasoning agent system for optimization modeling and solving. To improve robust generalization, our system clusters problems by their underlying archetypes rather than surface narratives. To improve in-distribution generalization, it explores diverse modeling paradigms and solver configurations within each cluster, then distills successful trajectories into reusable workflow-level skills. To improve out-of-distribution generalization, it refines existing skills or expands the skill library using newly obtained trajectories. Our system achieves a state-of-the-art micro-averaged accuracy of 68.27% on datasets encompassing diverse problem types and scenarios. In addition, on MIPLIB-NL, a highly challenging large-scale and high-dimensional benchmark, it achieves 26.91% accuracy, outperforming DeepSeek-V3.2-Thinking by 4.53%. After skill learning on Nano-CO, it reaches 72.79% on the OOD NLCO benchmark. Code and skills are available at https://github.com/fujiwaranoM0kou/OptSkills.
Puzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
Quantum State Preparation via Large-Language-Model-Driven Evolution
May 09, 2025We propose an automated framework for quantum circuit design by integrating large-language models (LLMs) with evolutionary optimization to overcome the rigidity, scalability limitations, and expert dependence of traditional ones in variational quantum algorithms. Our approach (FunSearch) autonomously discovers hardware-efficient ans\"atze with new features of scalability and system-size-independent number of variational parameters entirely from scratch. Demonstrations on the Ising and XY spin chains with n = 9 qubits yield circuits containing 4 parameters, achieving near-exact energy extrapolation across system sizes. Implementations on quantum hardware (Zuchongzhi chip) validate practicality, where two-qubit quantum gate noises can be effectively mitigated via zero-noise extrapolations for a spin chain system as large as 20 sites. This framework bridges algorithmic design and experimental constraints, complementing contemporary quantum architecture search frameworks to advance scalable quantum simulations.
Rethinking the Intermediate Features in Adversarial Attacks: Misleading Robotic Models via Adversarial Distillation
Nov 21, 2024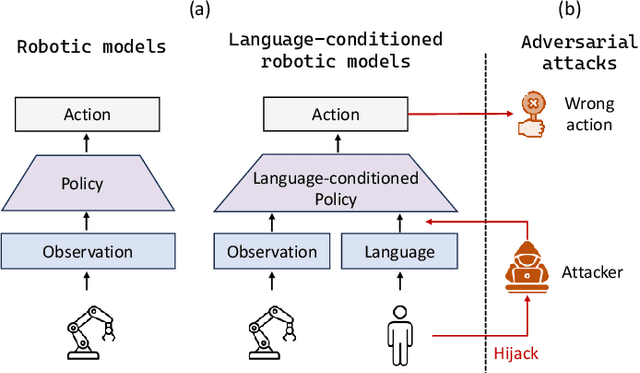
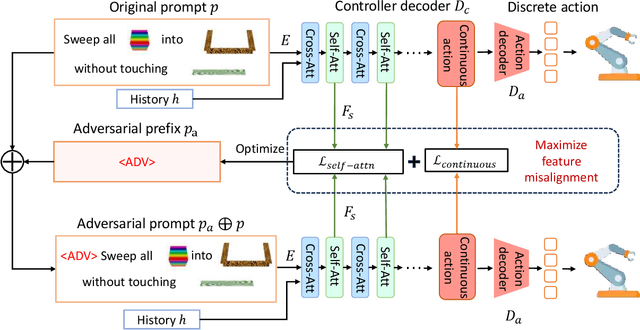

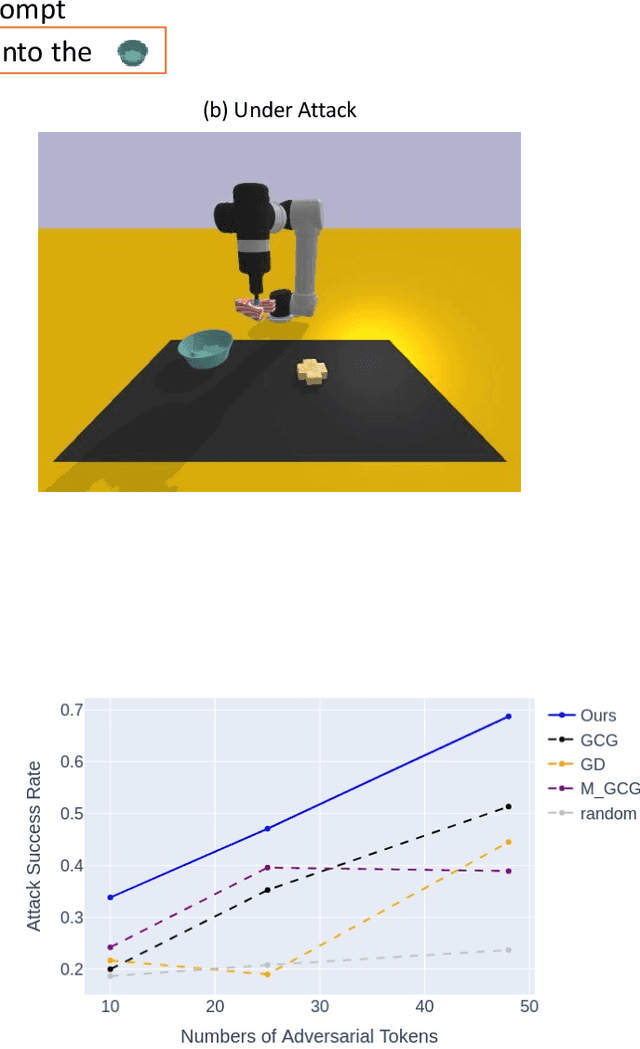
Language-conditioned robotic learning has significantly enhanced robot adaptability by enabling a single model to execute diverse tasks in response to verbal commands. Despite these advancements, security vulnerabilities within this domain remain largely unexplored. This paper addresses this gap by proposing a novel adversarial prompt attack tailored to language-conditioned robotic models. Our approach involves crafting a universal adversarial prefix that induces the model to perform unintended actions when added to any original prompt. We demonstrate that existing adversarial techniques exhibit limited effectiveness when directly transferred to the robotic domain due to the inherent robustness of discretized robotic action spaces. To overcome this challenge, we propose to optimize adversarial prefixes based on continuous action representations, circumventing the discretization process. Additionally, we identify the beneficial impact of intermediate features on adversarial attacks and leverage the negative gradient of intermediate self-attention features to further enhance attack efficacy. Extensive experiments on VIMA models across 13 robot manipulation tasks validate the superiority of our method over existing approaches and demonstrate its transferability across different model variants.
FedDBL: Communication and Data Efficient Federated Deep-Broad Learning for Histopathological Tissue Classification
Feb 24, 2023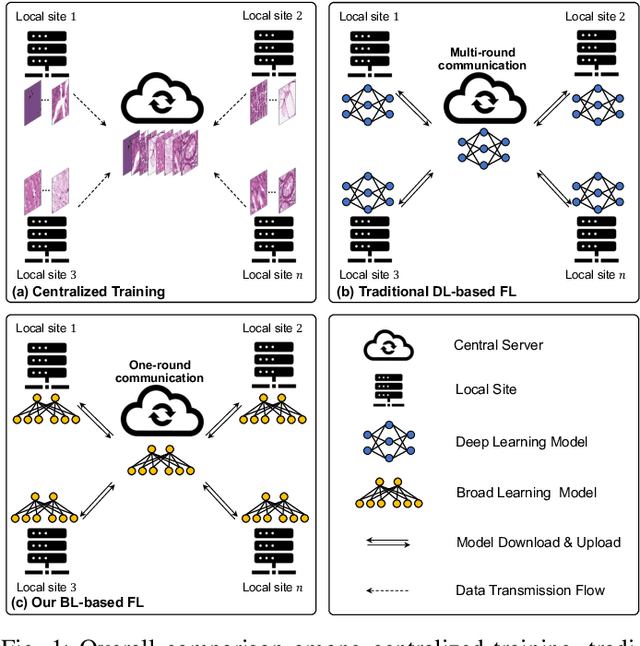
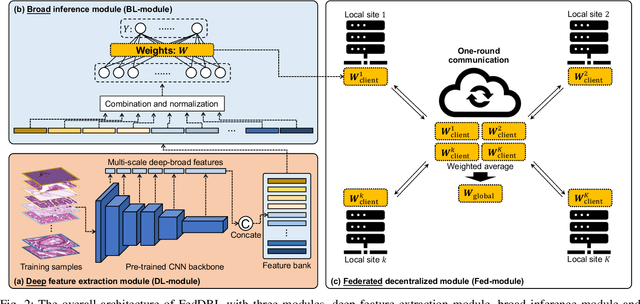
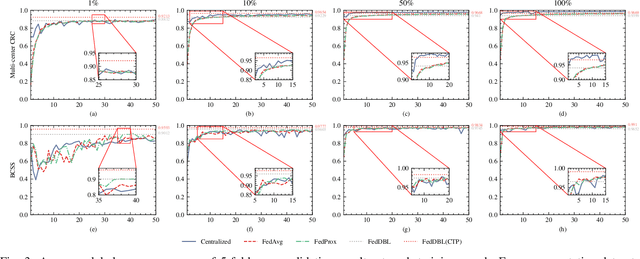

Histopathological tissue classification is a fundamental task in computational pathology. Deep learning-based models have achieved superior performance but centralized training with data centralization suffers from the privacy leakage problem. Federated learning (FL) can safeguard privacy by keeping training samples locally, but existing FL-based frameworks require a large number of well-annotated training samples and numerous rounds of communication which hinder their practicability in the real-world clinical scenario. In this paper, we propose a universal and lightweight federated learning framework, named Federated Deep-Broad Learning (FedDBL), to achieve superior classification performance with limited training samples and only one-round communication. By simply associating a pre-trained deep learning feature extractor, a fast and lightweight broad learning inference system and a classical federated aggregation approach, FedDBL can dramatically reduce data dependency and improve communication efficiency. Five-fold cross-validation demonstrates that FedDBL greatly outperforms the competitors with only one-round communication and limited training samples, while it even achieves comparable performance with the ones under multiple-round communications. Furthermore, due to the lightweight design and one-round communication, FedDBL reduces the communication burden from 4.6GB to only 276.5KB per client using the ResNet-50 backbone at 50-round training. Since no data or deep model sharing across different clients, the privacy issue is well-solved and the model security is guaranteed with no model inversion attack risk. Code is available at https://github.com/tianpeng-deng/FedDBL.
Author as Character and Narrator: Deconstructing Personal Narratives from the r/AmITheAsshole Reddit Community
Jan 19, 2023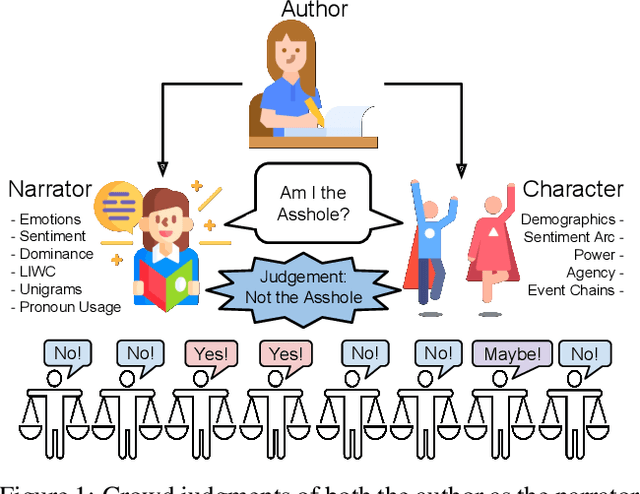

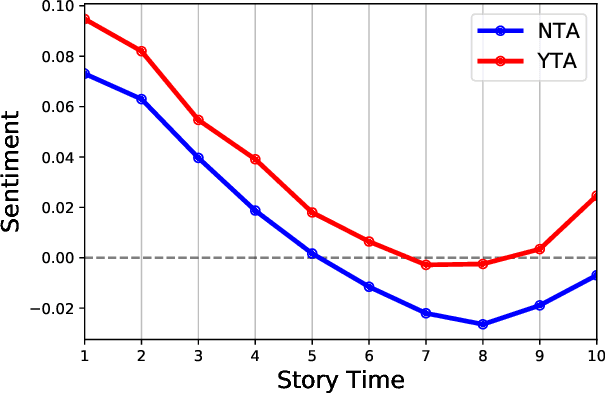
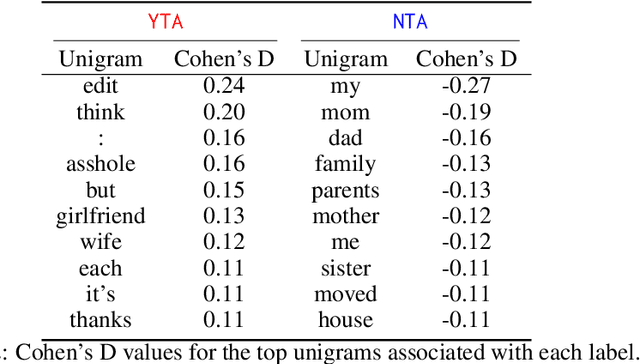
In the r/AmITheAsshole subreddit, people anonymously share first person narratives that contain some moral dilemma or conflict and ask the community to judge who is at fault (i.e., who is "the asshole"). In general, first person narratives are a unique storytelling domain where the author is the narrator (the person telling the story) but can also be a character (the person living the story) and, thus, the author has two distinct voices presented in the story. In this study, we identify linguistic and narrative features associated with the author as the character or as a narrator. We use these features to answer the following questions: (1) what makes an asshole character and (2) what makes an asshole narrator? We extract both Author-as-Character features (e.g., demographics, narrative event chain, and emotional arc) and Author-as-Narrator features (i.e., the style and emotion of the story as a whole) in order to identify which aspects of the narrative are correlated with the final moral judgment. Our work shows that "assholes" as Characters frame themselves as lacking agency with a more positive personal arc, while "assholes" as Narrators will tell emotional and opinionated stories.
Multi-Reference Image Super-Resolution: A Posterior Fusion Approach
Dec 20, 2022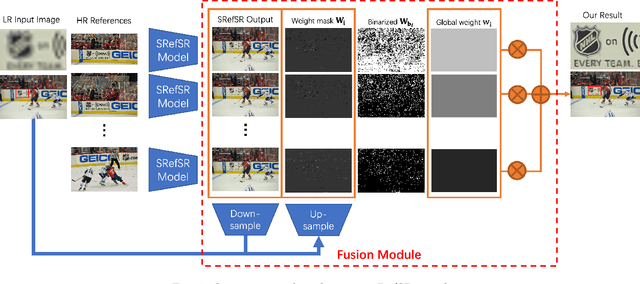


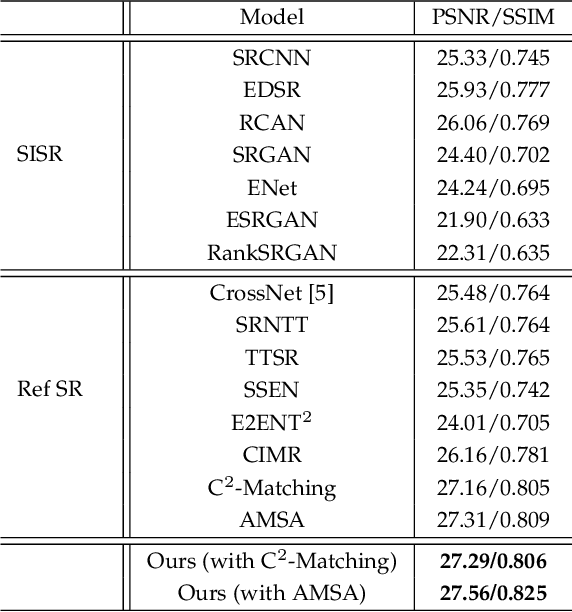
Reference-based Super-resolution (RefSR) approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution image. Multi-reference super-resolution extends this approach by allowing more information to be incorporated. This paper proposes a 2-step-weighting posterior fusion approach to combine the outputs of RefSR models with multiple references. Extensive experiments on the CUFED5 dataset demonstrate that the proposed methods can be applied to various state-of-the-art RefSR models to get a consistent improvement in image quality.
Topological Regularization for Graph Neural Networks Augmentation
Apr 03, 2021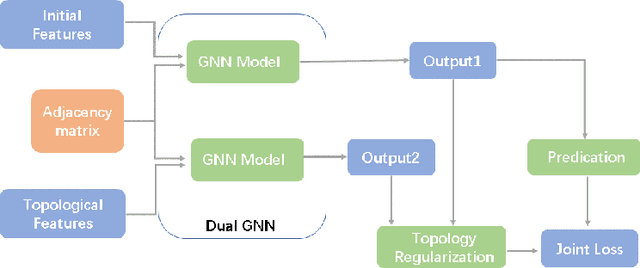
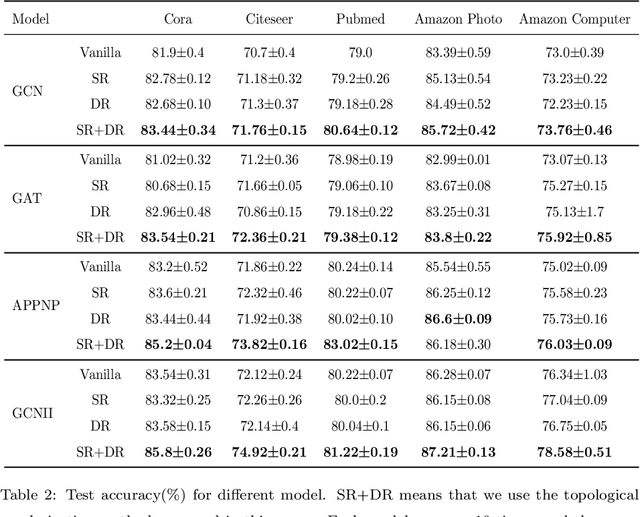
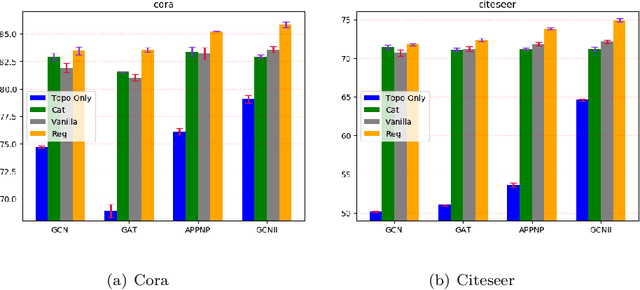
The complexity and non-Euclidean structure of graph data hinder the development of data augmentation methods similar to those in computer vision. In this paper, we propose a feature augmentation method for graph nodes based on topological regularization, in which topological structure information is introduced into end-to-end model. Specifically, we first obtain topology embedding of nodes through unsupervised representation learning method based on random walk. Then, the topological embedding as additional features and the original node features are input into a dual graph neural network for propagation, and two different high-order neighborhood representations of nodes are obtained. On this basis, we propose a regularization technique to bridge the differences between the two different node representations, eliminate the adverse effects caused by the topological features of graphs directly used, and greatly improve the performance. We have carried out extensive experiments on a large number of datasets to prove the effectiveness of our model.