 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoring Initial Noise Sensitivity in Text-to-Image Distillation via Geometric Alignment
Jun 01, 2026Generative distillation significantly accelerates text-to-image (T2I) generation by compressing multi-step trajectories into few-step student models while preserving perceptual quality. However, existing methods primarily optimize efficiency and output fidelity, often neglecting critical properties of the original trajectory. In this work, we identify a key missing property: sensitivity to initial noise, whose degradation impairs downstream control methods relying on noise-based optimization and manipulation. We trace this issue to standard distillation objectives that enforce pointwise output alignment, inadvertently flattening the input-output landscape and suppressing the teacher's local geometric structure. To address this, we propose Geometry-Aware Distillation (GAD), a sensitivity-preserving framework that aligns the local functional behavior of teacher and student models. Specifically, GAD matches Jacobian-vector products with respect to input noise, enabling the student to reproduce the teacher's differential response to perturbations. Extensive experiments across multiple T2I paradigms and noise-driven control tasks demonstrate that GAD significantly restores sensitivity and improves diversity while maintaining high visual fidelity. Code is available at https://github.com/Hannah1102/GAD.
BNMusic: Blending Environmental Noises into Personalized Music
Jun 12, 2025While being disturbed by environmental noises, the acoustic masking technique is a conventional way to reduce the annoyance in audio engineering that seeks to cover up the noises with other dominant yet less intrusive sounds. However, misalignment between the dominant sound and the noise-such as mismatched downbeats-often requires an excessive volume increase to achieve effective masking. Motivated by recent advances in cross-modal generation, in this work, we introduce an alternative method to acoustic masking, aiming to reduce the noticeability of environmental noises by blending them into personalized music generated based on user-provided text prompts. Following the paradigm of music generation using mel-spectrogram representations, we propose a Blending Noises into Personalized Music (BNMusic) framework with two key stages. The first stage synthesizes a complete piece of music in a mel-spectrogram representation that encapsulates the musical essence of the noise. In the second stage, we adaptively amplify the generated music segment to further reduce noise perception and enhance the blending effectiveness, while preserving auditory quality. Our experiments with comprehensive evaluations on MusicBench, EPIC-SOUNDS, and ESC-50 demonstrate the effectiveness of our framework, highlighting the ability to blend environmental noise with rhythmically aligned, adaptively amplified, and enjoyable music segments, minimizing the noticeability of the noise, thereby improving overall acoustic experiences.
Implicit Bias Injection Attacks against Text-to-Image Diffusion Models
Apr 02, 2025



The proliferation of text-to-image diffusion models (T2I DMs) has led to an increased presence of AI-generated images in daily life. However, biased T2I models can generate content with specific tendencies, potentially influencing people's perceptions. Intentional exploitation of these biases risks conveying misleading information to the public. Current research on bias primarily addresses explicit biases with recognizable visual patterns, such as skin color and gender. This paper introduces a novel form of implicit bias that lacks explicit visual features but can manifest in diverse ways across various semantic contexts. This subtle and versatile nature makes this bias challenging to detect, easy to propagate, and adaptable to a wide range of scenarios. We further propose an implicit bias injection attack framework (IBI-Attacks) against T2I diffusion models by precomputing a general bias direction in the prompt embedding space and adaptively adjusting it based on different inputs. Our attack module can be seamlessly integrated into pre-trained diffusion models in a plug-and-play manner without direct manipulation of user input or model retraining. Extensive experiments validate the effectiveness of our scheme in introducing bias through subtle and diverse modifications while preserving the original semantics. The strong concealment and transferability of our attack across various scenarios further underscore the significance of our approach. Code is available at https://github.com/Hannah1102/IBI-attacks.
Redistribute Ensemble Training for Mitigating Memorization in Diffusion Models
Feb 13, 2025Diffusion models, known for their tremendous ability to generate high-quality samples, have recently raised concerns due to their data memorization behavior, which poses privacy risks. Recent methods for memory mitigation have primarily addressed the issue within the context of the text modality in cross-modal generation tasks, restricting their applicability to specific conditions. In this paper, we propose a novel method for diffusion models from the perspective of visual modality, which is more generic and fundamental for mitigating memorization. Directly exposing visual data to the model increases memorization risk, so we design a framework where models learn through proxy model parameters instead. Specially, the training dataset is divided into multiple shards, with each shard training a proxy model, then aggregated to form the final model. Additionally, practical analysis of training losses illustrates that the losses for easily memorable images tend to be obviously lower. Thus, we skip the samples with abnormally low loss values from the current mini-batch to avoid memorizing. However, balancing the need to skip memorization-prone samples while maintaining sufficient training data for high-quality image generation presents a key challenge. Thus, we propose IET-AGC+, which redistributes highly memorizable samples between shards, to mitigate these samples from over-skipping. Furthermore, we dynamically augment samples based on their loss values to further reduce memorization. Extensive experiments and analysis on four datasets show that our method successfully reduces memory capacity while maintaining performance. Moreover, we fine-tune the pre-trained diffusion models, e.g., Stable Diffusion, and decrease the memorization score by 46.7\%, demonstrating the effectiveness of our method. Code is available in: https://github.com/liuxiao-guan/IET_AGC.
The Silent Prompt: Initial Noise as Implicit Guidance for Goal-Driven Image Generation
Dec 06, 2024



Text-to-image synthesis (T2I) has advanced remarkably with the emergence of large-scale diffusion models. In the conventional setup, the text prompt provides explicit, user-defined guidance, directing the generation process by denoising a randomly sampled Gaussian noise. In this work, we reveal that the often-overlooked noise itself encodes inherent generative tendencies, acting as a "silent prompt" that implicitly guides the output. This implicit guidance, embedded in the noise scheduler design of diffusion model formulations and their training stages, generalizes across a wide range of T2I models and backbones. Building on this insight, we introduce NoiseQuery, a novel strategy that selects optimal initial noise from a pre-built noise library to meet diverse user needs. Our approach not only enhances high-level semantic alignment with text prompts, but also allows for nuanced adjustments of low-level visual attributes, such as texture, sharpness, shape, and color, which are typically challenging to control through text alone. Extensive experiments across various models and target attributes demonstrate the strong performance and zero-shot transferability of our approach, requiring no additional optimization.
Rethinking the Intermediate Features in Adversarial Attacks: Misleading Robotic Models via Adversarial Distillation
Nov 21, 2024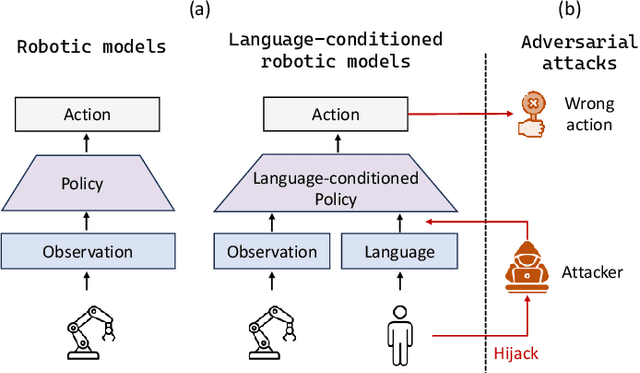
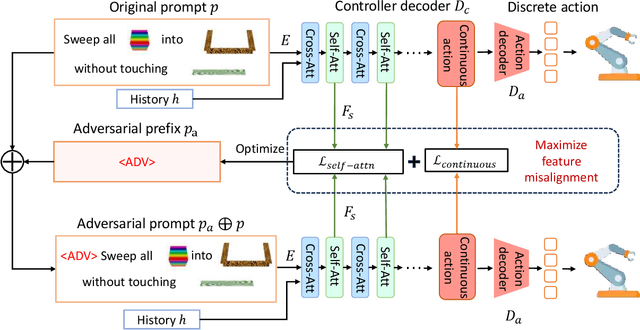

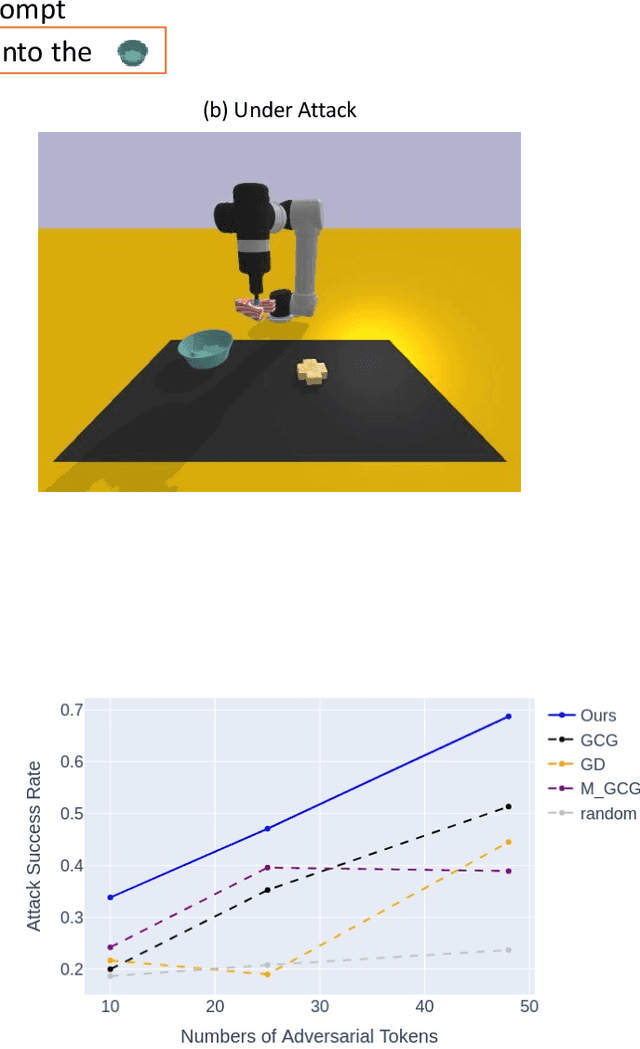
Language-conditioned robotic learning has significantly enhanced robot adaptability by enabling a single model to execute diverse tasks in response to verbal commands. Despite these advancements, security vulnerabilities within this domain remain largely unexplored. This paper addresses this gap by proposing a novel adversarial prompt attack tailored to language-conditioned robotic models. Our approach involves crafting a universal adversarial prefix that induces the model to perform unintended actions when added to any original prompt. We demonstrate that existing adversarial techniques exhibit limited effectiveness when directly transferred to the robotic domain due to the inherent robustness of discretized robotic action spaces. To overcome this challenge, we propose to optimize adversarial prefixes based on continuous action representations, circumventing the discretization process. Additionally, we identify the beneficial impact of intermediate features on adversarial attacks and leverage the negative gradient of intermediate self-attention features to further enhance attack efficacy. Extensive experiments on VIMA models across 13 robot manipulation tasks validate the superiority of our method over existing approaches and demonstrate its transferability across different model variants.
ROBIN: Robust and Invisible Watermarks for Diffusion Models with Adversarial Optimization
Nov 06, 2024



Watermarking generative content serves as a vital tool for authentication, ownership protection, and mitigation of potential misuse. Existing watermarking methods face the challenge of balancing robustness and concealment. They empirically inject a watermark that is both invisible and robust and passively achieve concealment by limiting the strength of the watermark, thus reducing the robustness. In this paper, we propose to explicitly introduce a watermark hiding process to actively achieve concealment, thus allowing the embedding of stronger watermarks. To be specific, we implant a robust watermark in an intermediate diffusion state and then guide the model to hide the watermark in the final generated image. We employ an adversarial optimization algorithm to produce the optimal hiding prompt guiding signal for each watermark. The prompt embedding is optimized to minimize artifacts in the generated image, while the watermark is optimized to achieve maximum strength. The watermark can be verified by reversing the generation process. Experiments on various diffusion models demonstrate the watermark remains verifiable even under significant image tampering and shows superior invisibility compared to other state-of-the-art robust watermarking methods.