 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBNMusic: Blending Environmental Noises into Personalized Music
Jun 12, 2025While being disturbed by environmental noises, the acoustic masking technique is a conventional way to reduce the annoyance in audio engineering that seeks to cover up the noises with other dominant yet less intrusive sounds. However, misalignment between the dominant sound and the noise-such as mismatched downbeats-often requires an excessive volume increase to achieve effective masking. Motivated by recent advances in cross-modal generation, in this work, we introduce an alternative method to acoustic masking, aiming to reduce the noticeability of environmental noises by blending them into personalized music generated based on user-provided text prompts. Following the paradigm of music generation using mel-spectrogram representations, we propose a Blending Noises into Personalized Music (BNMusic) framework with two key stages. The first stage synthesizes a complete piece of music in a mel-spectrogram representation that encapsulates the musical essence of the noise. In the second stage, we adaptively amplify the generated music segment to further reduce noise perception and enhance the blending effectiveness, while preserving auditory quality. Our experiments with comprehensive evaluations on MusicBench, EPIC-SOUNDS, and ESC-50 demonstrate the effectiveness of our framework, highlighting the ability to blend environmental noise with rhythmically aligned, adaptively amplified, and enjoyable music segments, minimizing the noticeability of the noise, thereby improving overall acoustic experiences.
On the Integration of Acoustics and LiDAR: a Multi-Modal Approach to Acoustic Reflector Estimation
Jun 08, 2022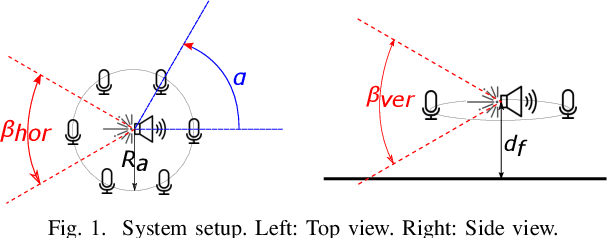
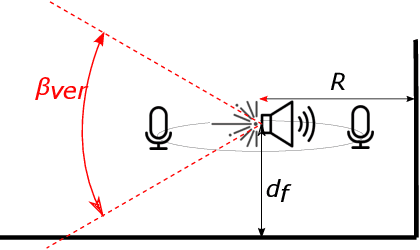
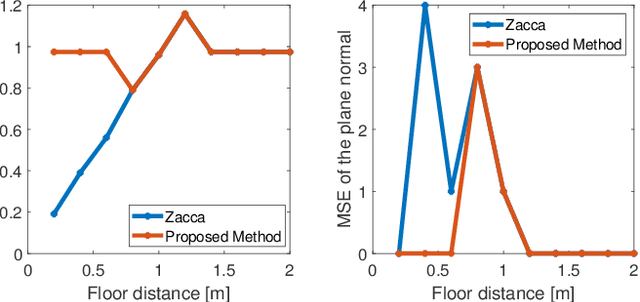
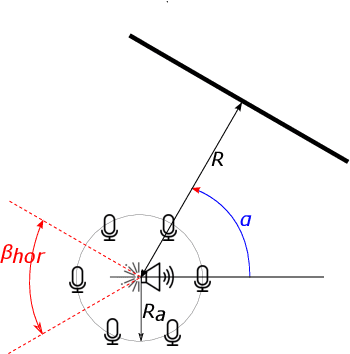
Having knowledge on the room acoustic properties, e.g., the location of acoustic reflectors, allows to better reproduce the sound field as intended. Current state-of-the-art methods for room boundary detection using microphone measurements typically focus on a two-dimensional setting, causing a model mismatch when employed in real-life scenarios. Detection of arbitrary reflectors in three dimensions encounters practical limitations, e.g., the need for a spherical array and the increased computational complexity. Moreover, loudspeakers may not have an omnidirectional directivity pattern, as usually assumed in the literature, making the detection of acoustic reflectors in some directions more challenging. In the proposed method, a LiDAR sensor is added to a loudspeaker to improve wall detection accuracy and robustness. This is done in two ways. First, the model mismatch introduced by horizontal reflectors can be resolved by detecting reflectors with the LiDAR sensor to enable elimination of their detrimental influence from the 2D problem in pre-processing. Second, a LiDAR-based method is proposed to compensate for the challenging directions where the directive loudspeaker emits little energy. We show via simulations that this multi-modal approach, i.e., combining microphone and LiDAR sensors, improves the robustness and accuracy of wall detection.
Nonuniform Sampling Rate Conversion: An Efficient Approach
May 14, 2021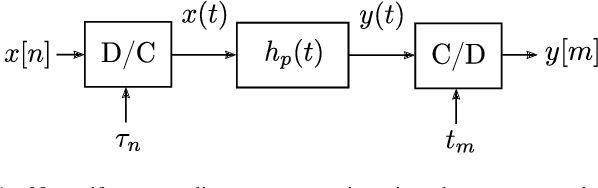



We present a discrete-time algorithm for nonuniform sampling rate conversion that presents low computational complexity and memory requirements. It generalizes arbitrary sampling rate conversion by accommodating time-varying conversion ratios, i.e., it can efficiently adapt to instantaneous changes of the input and output sampling rates. This approach is based on appropriately factorizing the time-varying discrete-time filter used for the conversion. Common filters that satisfy this factorization property are those where the underlying continuous-time filter consists of linear combinations of exponentials, e.g., those described by linear constant-coefficient differential equations. This factorization separates the computation into two parts: one consisting of a factor solely depending on the output sampling instants and the other consists of a summation -- that can be computed recursively -- whose terms depend solely on the input sampling instants and its number of terms is given by a relationship between input and output sampling instants. Thus, nonuniform sampling rates can be accommodated by updating the factors involved and adjusting the number of terms added. When the impulse response consists of exponentials, computing the factors can be done recursively in an efficient manner.
Deep Sound Field Reconstruction in Real Rooms: Introducing the ISOBEL Sound Field Dataset
Feb 12, 2021
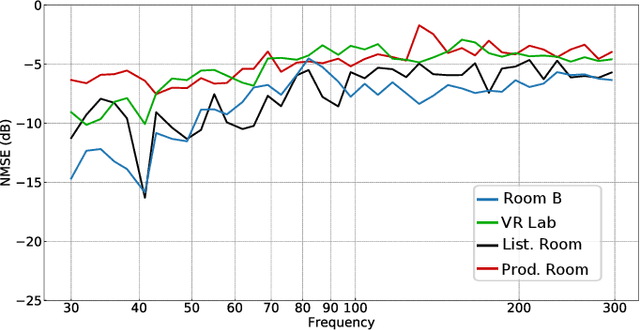
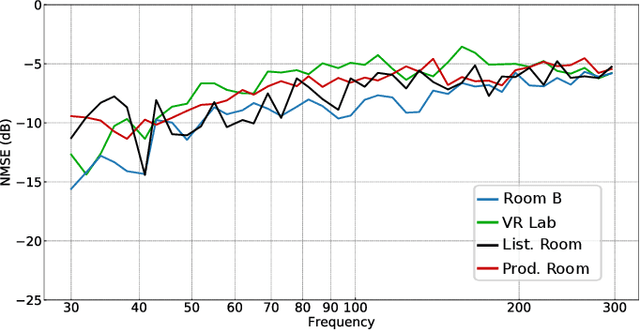
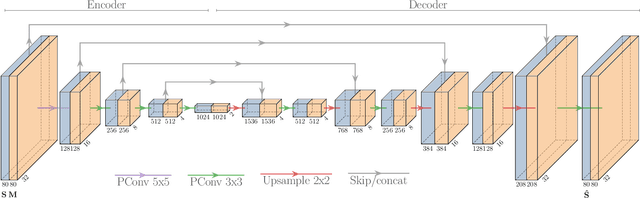
Knowledge of loudspeaker responses are useful in a number of applications, where a sound system is located inside a room that alters the listening experience depending on position within the room. Acquisition of sound fields for sound sources located in reverberant rooms can be achieved through labor intensive measurements of impulse response functions covering the room, or alternatively by means of reconstruction methods which can potentially require significantly fewer measurements. This paper extends evaluations of sound field reconstruction at low frequencies by introducing a dataset with measurements from four real rooms. The ISOBEL Sound Field dataset is publicly available, and aims to bridge the gap between synthetic and real-world sound fields in rectangular rooms. Moreover, the paper advances on a recent deep learning-based method for sound field reconstruction using a very low number of microphones, and proposes an approach for modeling both magnitude and phase response in a U-Net-like neural network architecture. The complex-valued sound field reconstruction demonstrates that the estimated room transfer functions are of high enough accuracy to allow for personalized sound zones with contrast ratios comparable to ideal room transfer functions using 15 microphones below 150 Hz.
Sound field reconstruction in rooms: inpainting meets superresolution
Jan 30, 2020
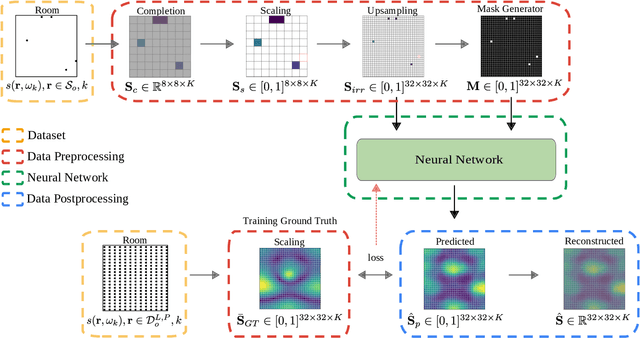
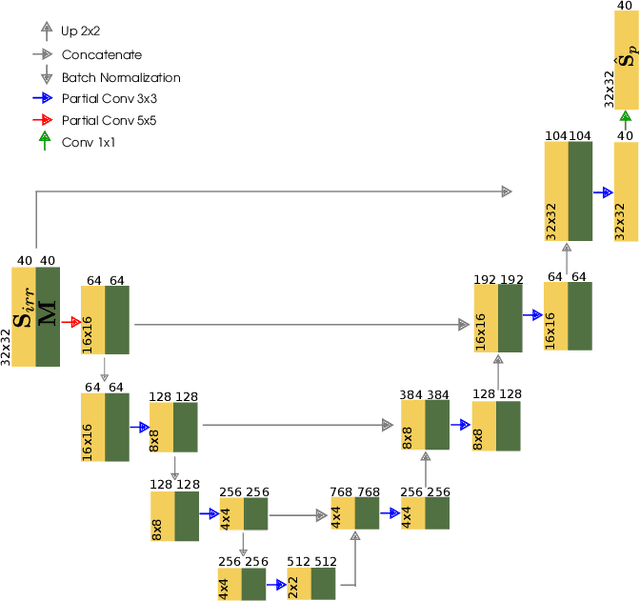
In this paper a deep-learning-based method for sound field reconstruction is proposed. It is shown the possibility to reconstruct the magnitude of the sound pressure in the frequency band 30-300 Hz for an entire room by using a very low number of irregularly distributed microphones arbitrarily arranged. In particular, the presented approach uses a limited number of arbitrary discrete measurements of the magnitude of the sound field pressure in order to extrapolate this field to a higher-resolution grid of discrete points in space with a low computational complexity. The method is based on a U-net-like neural network with partial convolutions trained solely on simulated data, i.e. the dataset is constructed from numerical simulations of the Green's function across thousands of common rectangular rooms. Although extensible to three dimensions, the method focuses on reconstructing a two-dimensional plane of the room from measurements of the three-dimensional sound field. Experiments using simulated data together with an experimental validation in a real listening room are shown. The results suggest a performance---in terms of mean squared error and structural similarity---which may exceed conventional reconstruction techniques for a low number of microphones and computational requirements.
Multiview Based 3D Scene Understanding On Partial Point Sets
Nov 30, 2018
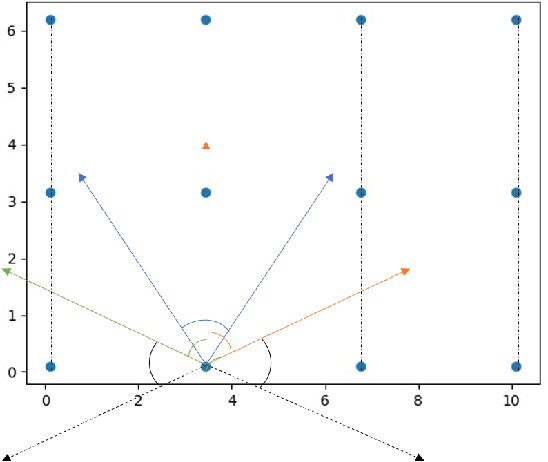

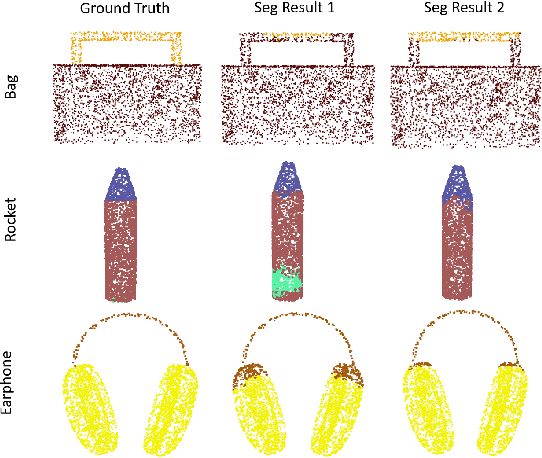
Deep learning within the context of point clouds has gained much research interest in recent years mostly due to the promising results that have been achieved on a number of challenging benchmarks, such as 3D shape recognition and scene semantic segmentation. In many realistic settings however, snapshots of the environment are often taken from a single view, which only contains a partial set of the scene due to the field of view restriction of commodity cameras. 3D scene semantic understanding on partial point clouds is considered as a challenging task. In this work, we propose a processing approach for 3D point cloud data based on a multiview representation of the existing 360{\deg} point clouds. By fusing the original 360{\deg} point clouds and their corresponding 3D multiview representations as input data, a neural network is able to recognize partial point sets while improving the general performance on complete point sets, resulting in an overall increase of 31.9% and 4.3% in segmentation accuracy for partial and complete scene semantic understanding, respectively. This method can also be applied in a wider 3D recognition context such as 3D part segmentation.