 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLESV: Language Embedded Sparse Voxel Fusion for Open-Vocabulary 3D Scene Understanding
Apr 01, 2026Recent advancements in open-vocabulary 3D scene understanding heavily rely on 3D Gaussian Splatting (3DGS) to register vision-language features into 3D space. However, we identify two critical limitations in these approaches: the spatial ambiguity arising from unstructured, overlapping Gaussians which necessitates probabilistic feature registration, and the multi-level semantic ambiguity caused by pooling features over object-level masks, which dilutes fine-grained details. To address these challenges, we present a novel framework that leverages Sparse Voxel Rasterization (SVRaster) as a structured, disjoint geometry representation. By regularizing SVRaster with monocular depth and normal priors, we establish a stable geometric foundation. This enables a deterministic, confidence-aware feature registration process and suppresses the semantic bleeding artifact common in 3DGS. Furthermore, we resolve multi-level ambiguity by exploiting the emerging dense alignment properties of foundation model AM-RADIO, avoiding the computational overhead of hierarchical training methods. Our approach achieves state-of-the-art performance on Open Vocabulary 3D Object Retrieval and Point Cloud Understanding benchmarks, particularly excelling on fine-grained queries where registration methods typically fail.
Future-Interactions-Aware Trajectory Prediction via Braid Theory
Mar 23, 2026To safely operate, an autonomous vehicle must know the future behavior of a potentially high number of interacting agents around it, a task often posed as multi-agent trajectory prediction. Many previous attempts to model social interactions and solve the joint prediction task either add extensive computational requirements or rely on heuristics to label multi-agent behavior types. Braid theory, in contrast, provides a powerful exact descriptor of multi-agent behavior by projecting future trajectories into braids that express how trajectories cross with each other over time; a braid then corresponds to a specific mode of coordination between the multiple agents in the future. In past work, braids have been used lightly to reason about interacting agents and restrict the attention window of predicted agents. We show that leveraging more fully the expressivity of the braid representation and using it to condition the trajectories themselves leads to even further gains in joint prediction performance, with negligible added complexity either in training or at inference time. We do so by proposing a novel auxiliary task, braid prediction, done in parallel with the trajectory prediction task. By classifying edges between agents into their correct crossing types in the braid representation, the braid prediction task is able to imbue the model with improved social awareness, which is reflected in joint predictions that more closely adhere to the actual multi-agent behavior. This simple auxiliary task allowed us to obtain significant improvements in joint metrics on three separate datasets. We show how the braid prediction task infuses the model with future intention awareness, leading to more accurate joint predictions. Code is available at github.com/caiocj1/traj-pred-braid-theory.
LiDAS: Lighting-driven Dynamic Active Sensing for Nighttime Perception
Dec 09, 2025Nighttime environments pose significant challenges for camera-based perception, as existing methods passively rely on the scene lighting. We introduce Lighting-driven Dynamic Active Sensing (LiDAS), a closed-loop active illumination system that combines off-the-shelf visual perception models with high-definition headlights. Rather than uniformly brightening the scene, LiDAS dynamically predicts an optimal illumination field that maximizes downstream perception performance, i.e., decreasing light on empty areas to reallocate it on object regions. LiDAS enables zero-shot nighttime generalization of daytime-trained models through adaptive illumination control. Trained on synthetic data and deployed zero-shot in real-world closed-loop driving scenarios, LiDAS enables +18.7% mAP50 and +5.0% mIoU over standard low-beam at equal power. It maintains performances while reducing energy use by 40%. LiDAS complements domain-generalization methods, further strengthening robustness without retraining. By turning readily available headlights into active vision actuators, LiDAS offers a cost-effective solution to robust nighttime perception.
Improving Consistency in Vehicle Trajectory Prediction Through Preference Optimization
Jul 03, 2025Trajectory prediction is an essential step in the pipeline of an autonomous vehicle. Inaccurate or inconsistent predictions regarding the movement of agents in its surroundings lead to poorly planned maneuvers and potentially dangerous situations for the end-user. Current state-of-the-art deep-learning-based trajectory prediction models can achieve excellent accuracy on public datasets. However, when used in more complex, interactive scenarios, they often fail to capture important interdependencies between agents, leading to inconsistent predictions among agents in the traffic scene. Inspired by the efficacy of incorporating human preference into large language models, this work fine-tunes trajectory prediction models in multi-agent settings using preference optimization. By taking as input automatically calculated preference rankings among predicted futures in the fine-tuning process, our experiments--using state-of-the-art models on three separate datasets--show that we are able to significantly improve scene consistency while minimally sacrificing trajectory prediction accuracy and without adding any excess computational requirements at inference time.
DOC-Depth: A novel approach for dense depth ground truth generation
Feb 04, 2025



Accurate depth information is essential for many computer vision applications. Yet, no available dataset recording method allows for fully dense accurate depth estimation in a large scale dynamic environment. In this paper, we introduce DOC-Depth, a novel, efficient and easy-to-deploy approach for dense depth generation from any LiDAR sensor. After reconstructing consistent dense 3D environment using LiDAR odometry, we address dynamic objects occlusions automatically thanks to DOC, our state-of-the art dynamic object classification method. Additionally, DOC-Depth is fast and scalable, allowing for the creation of unbounded datasets in terms of size and time. We demonstrate the effectiveness of our approach on the KITTI dataset, improving its density from 16.1% to 71.2% and release this new fully dense depth annotation, to facilitate future research in the domain. We also showcase results using various LiDAR sensors and in multiple environments. All software components are publicly available for the research community.
AVS-Net: Audio-Visual Scale Net for Self-supervised Monocular Metric Depth Estimation
Dec 02, 2024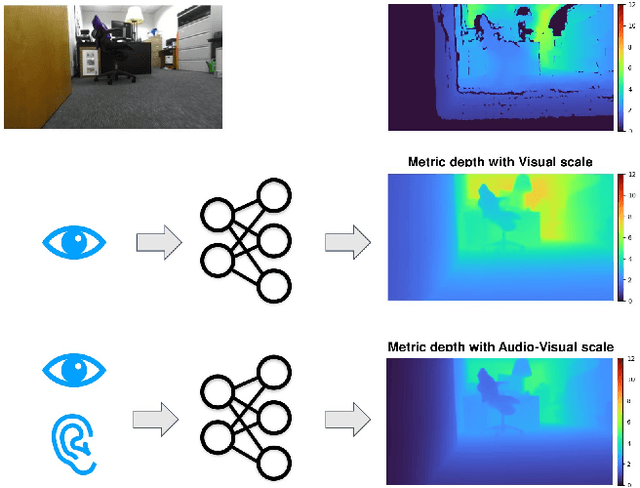

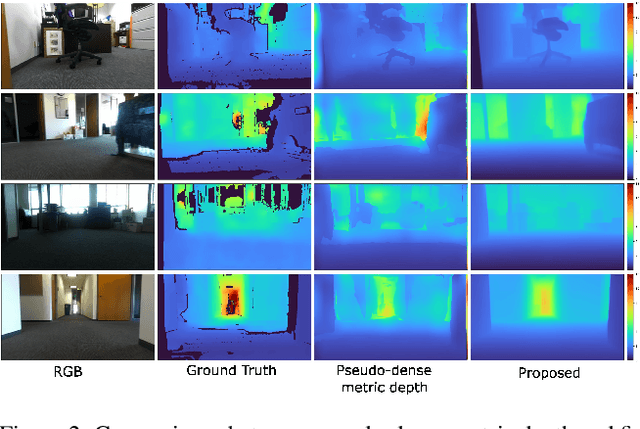
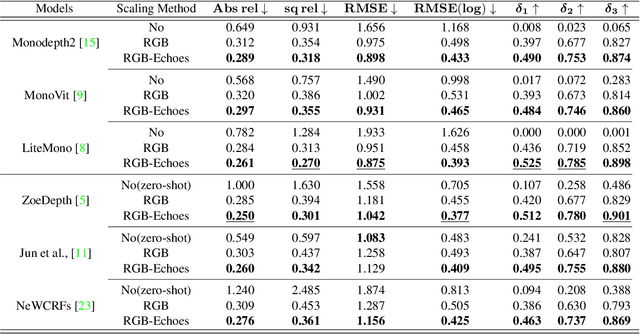
Metric depth prediction from monocular videos suffers from bad generalization between datasets and requires supervised depth data for scale-correct training. Self-supervised training using multi-view reconstruction can benefit from large scale natural videos but not provide correct scale, limiting its benefits. Recently, reflecting audible Echoes off objects is investigated for improved depth prediction and was shown to be sufficient to reconstruct objects at scale even without a visual signal. Because Echoes travel at fixed speed, they have the potential to resolve ambiguities in object scale and appearance. However, predicting depth end-to-end from sound and vision cannot benefit from unsupervised depth prediction approaches, which can process large scale data without sound annotation. In this work we show how Echoes can benefit depth prediction in two ways: When learning metric depth learned from supervised data and as supervisory signal for scale-correct self-supervised training. We show how we can improve the predictions of several state-of-the-art approaches and how the method can scale-correct a self-supervised depth approach.
LED: Light Enhanced Depth Estimation at Night
Sep 12, 2024



Nighttime camera-based depth estimation is a highly challenging task, especially for autonomous driving applications, where accurate depth perception is essential for ensuring safe navigation. We aim to improve the reliability of perception systems at night time, where models trained on daytime data often fail in the absence of precise but costly LiDAR sensors. In this work, we introduce Light Enhanced Depth (LED), a novel cost-effective approach that significantly improves depth estimation in low-light environments by harnessing a pattern projected by high definition headlights available in modern vehicles. LED leads to significant performance boosts across multiple depth-estimation architectures (encoder-decoder, Adabins, DepthFormer) both on synthetic and real datasets. Furthermore, increased performances beyond illuminated areas reveal a holistic enhancement in scene understanding. Finally, we release the Nighttime Synthetic Drive Dataset, a new synthetic and photo-realistic nighttime dataset, which comprises 49,990 comprehensively annotated images.
NeRAF: 3D Scene Infused Neural Radiance and Acoustic Fields
May 28, 2024Sound plays a major role in human perception, providing essential scene information alongside vision for understanding our environment. Despite progress in neural implicit representations, learning acoustics that match a visual scene is still challenging. We propose NeRAF, a method that jointly learns acoustic and radiance fields. NeRAF is designed as a Nerfstudio module for convenient access to realistic audio-visual generation. It synthesizes both novel views and spatialized audio at new positions, leveraging radiance field capabilities to condition the acoustic field with 3D scene information. At inference, each modality can be rendered independently and at spatially separated positions, providing greater versatility. We demonstrate the advantages of our method on the SoundSpaces dataset. NeRAF achieves substantial performance improvements over previous works while being more data-efficient. Furthermore, NeRAF enhances novel view synthesis of complex scenes trained with sparse data through cross-modal learning.
Mesoscale Traffic Forecasting for Real-Time Bottleneck and Shockwave Prediction
Feb 08, 2024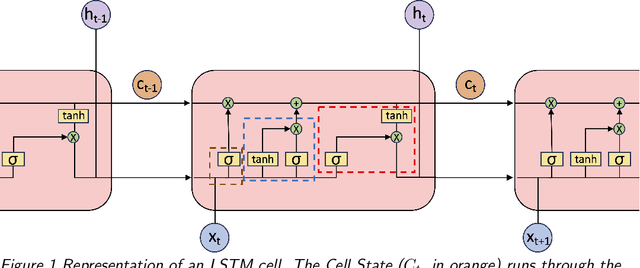
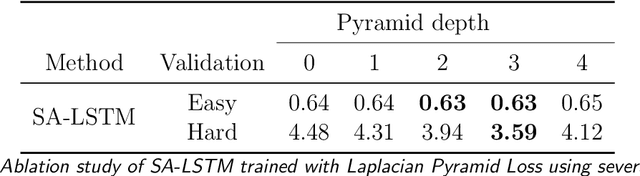
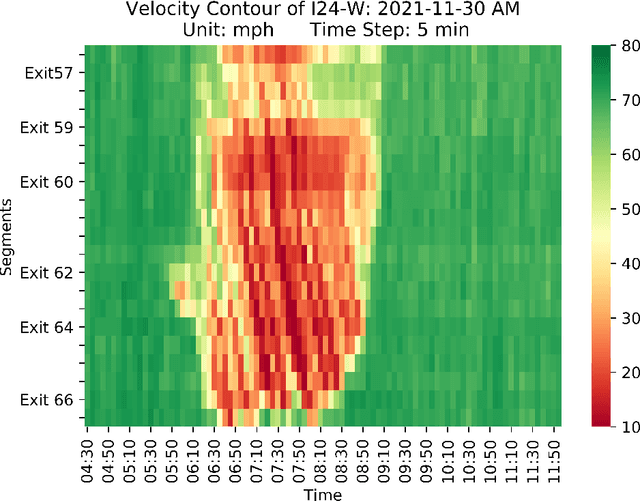
Accurate real-time traffic state forecasting plays a pivotal role in traffic control research. In particular, the CIRCLES consortium project necessitates predictive techniques to mitigate the impact of data source delays. After the success of the MegaVanderTest experiment, this paper aims at overcoming the current system limitations and develop a more suited approach to improve the real-time traffic state estimation for the next iterations of the experiment. In this paper, we introduce the SA-LSTM, a deep forecasting method integrating Self-Attention (SA) on the spatial dimension with Long Short-Term Memory (LSTM) yielding state-of-the-art results in real-time mesoscale traffic forecasting. We extend this approach to multi-step forecasting with the n-step SA-LSTM, which outperforms traditional multi-step forecasting methods in the trade-off between short-term and long-term predictions, all while operating in real-time.
HiER: Highlight Experience Replay and Easy2Hard Curriculum Learning for Boosting Off-Policy Reinforcement Learning Agents
Dec 14, 2023



Even though reinforcement-learning-based algorithms achieved superhuman performance in many domains, the field of robotics poses significant challenges as the state and action spaces are continuous, and the reward function is predominantly sparse. In this work, we propose: 1) HiER: highlight experience replay that creates a secondary replay buffer for the most relevant experiences, 2) E2H-ISE: an easy2hard data collection curriculum-learning method based on controlling the entropy of the initial state-goal distribution and with it, indirectly, the task difficulty, and 3) HiER+: the combination of HiER and E2H-ISE. They can be applied with or without the techniques of hindsight experience replay (HER) and prioritized experience replay (PER). While both HiER and E2H-ISE surpass the baselines, HiER+ further improves the results and significantly outperforms the state-of-the-art on the push, slide, and pick-and-place robotic manipulation tasks. Our implementation and further media materials are available on the project site.