 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pixels: Leveraging the Language of Soccer to Improve Spatio-Temporal Action Detection in Broadcast Videos
May 14, 2025State-of-the-art spatio-temporal action detection (STAD) methods show promising results for extracting soccer events from broadcast videos. However, when operated in the high-recall, low-precision regime required for exhaustive event coverage in soccer analytics, their lack of contextual understanding becomes apparent: many false positives could be resolved by considering a broader sequence of actions and game-state information. In this work, we address this limitation by reasoning at the game level and improving STAD through the addition of a denoising sequence transduction task. Sequences of noisy, context-free player-centric predictions are processed alongside clean game state information using a Transformer-based encoder-decoder model. By modeling extended temporal context and reasoning jointly over team-level dynamics, our method leverages the "language of soccer" - its tactical regularities and inter-player dependencies - to generate "denoised" sequences of actions. This approach improves both precision and recall in low-confidence regimes, enabling more reliable event extraction from broadcast video and complementing existing pixel-based methods.
Mesoscale Traffic Forecasting for Real-Time Bottleneck and Shockwave Prediction
Feb 08, 2024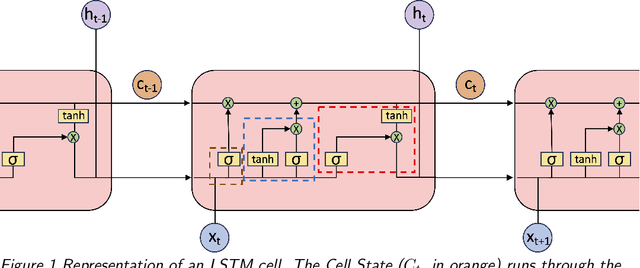
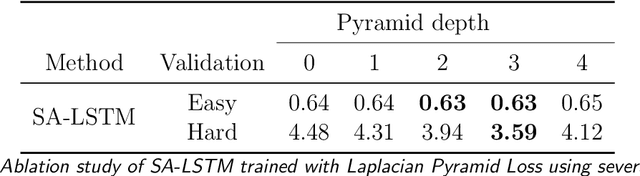
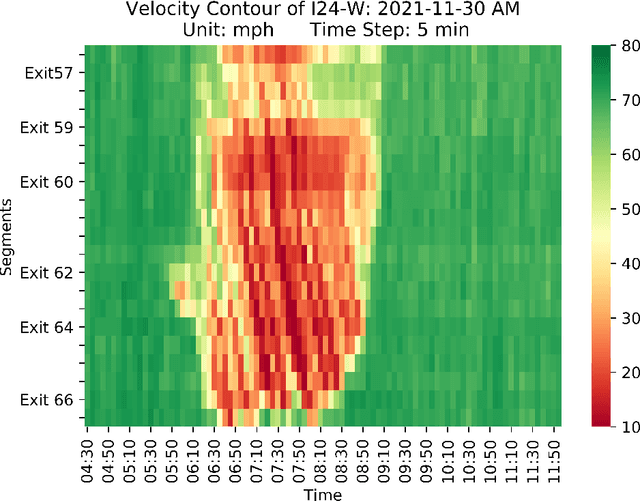
Accurate real-time traffic state forecasting plays a pivotal role in traffic control research. In particular, the CIRCLES consortium project necessitates predictive techniques to mitigate the impact of data source delays. After the success of the MegaVanderTest experiment, this paper aims at overcoming the current system limitations and develop a more suited approach to improve the real-time traffic state estimation for the next iterations of the experiment. In this paper, we introduce the SA-LSTM, a deep forecasting method integrating Self-Attention (SA) on the spatial dimension with Long Short-Term Memory (LSTM) yielding state-of-the-art results in real-time mesoscale traffic forecasting. We extend this approach to multi-step forecasting with the n-step SA-LSTM, which outperforms traditional multi-step forecasting methods in the trade-off between short-term and long-term predictions, all while operating in real-time.
MBAPPE: MCTS-Built-Around Prediction for Planning Explicitly
Sep 15, 2023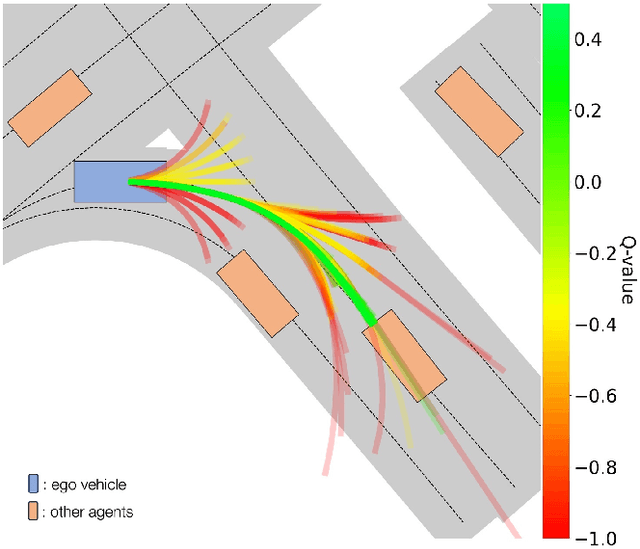
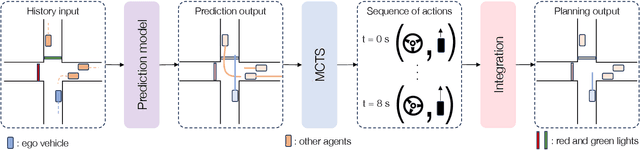
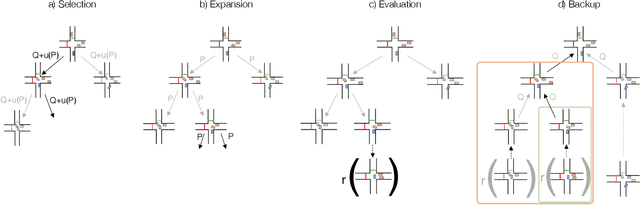
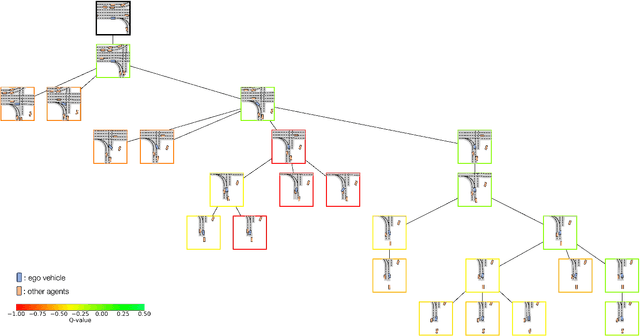
We present MBAPPE, a novel approach to motion planning for autonomous driving combining tree search with a partially-learned model of the environment. Leveraging the inherent explainable exploration and optimization capabilities of the Monte-Carlo Search Tree (MCTS), our method addresses complex decision-making in a dynamic environment. We propose a framework that combines MCTS with supervised learning, enabling the autonomous vehicle to effectively navigate through diverse scenarios. Experimental results demonstrate the effectiveness and adaptability of our approach, showcasing improved real-time decision-making and collision avoidance. This paper contributes to the field by providing a robust solution for motion planning in autonomous driving systems, enhancing their explainability and reliability.
GRI: General Reinforced Imitation and its Application to Vision-Based Autonomous Driving
Nov 16, 2021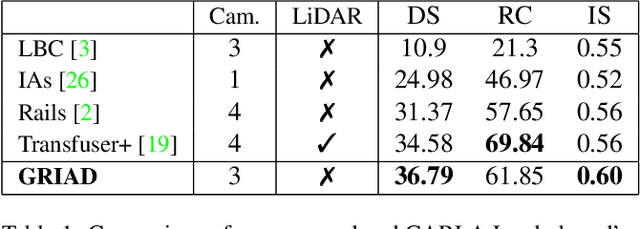
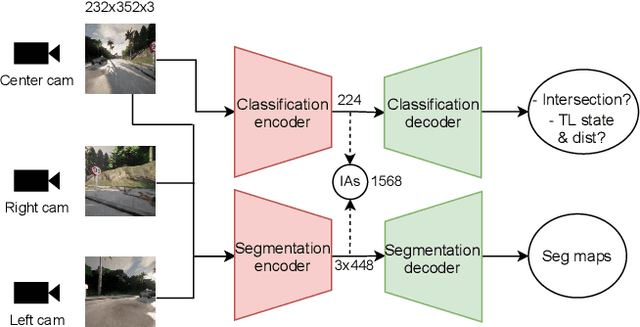
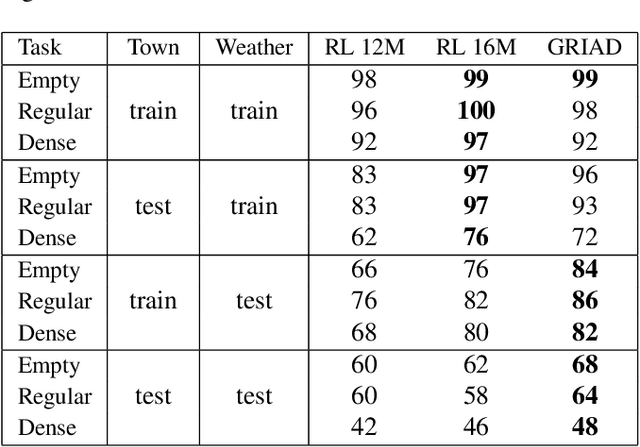
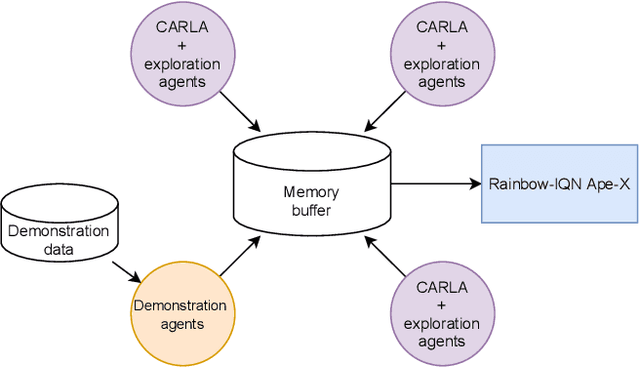
Deep reinforcement learning (DRL) has been demonstrated to be effective for several complex decision-making applications such as autonomous driving and robotics. However, DRL is notoriously limited by its high sample complexity and its lack of stability. Prior knowledge, e.g. as expert demonstrations, is often available but challenging to leverage to mitigate these issues. In this paper, we propose General Reinforced Imitation (GRI), a novel method which combines benefits from exploration and expert data and is straightforward to implement over any off-policy RL algorithm. We make one simplifying hypothesis: expert demonstrations can be seen as perfect data whose underlying policy gets a constant high reward. Based on this assumption, GRI introduces the notion of offline demonstration agents. This agent sends expert data which are processed both concurrently and indistinguishably with the experiences coming from the online RL exploration agent. We show that our approach enables major improvements on vision-based autonomous driving in urban environments. We further validate the GRI method on Mujoco continuous control tasks with different off-policy RL algorithms. Our method ranked first on the CARLA Leaderboard and outperforms World on Rails, the previous state-of-the-art, by 17%.