 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnO: Unsupervised Occupancy Fields for Perception and Forecasting
Jun 12, 2024Perceiving the world and forecasting its future state is a critical task for self-driving. Supervised approaches leverage annotated object labels to learn a model of the world -- traditionally with object detections and trajectory predictions, or temporal bird's-eye-view (BEV) occupancy fields. However, these annotations are expensive and typically limited to a set of predefined categories that do not cover everything we might encounter on the road. Instead, we learn to perceive and forecast a continuous 4D (spatio-temporal) occupancy field with self-supervision from LiDAR data. This unsupervised world model can be easily and effectively transferred to downstream tasks. We tackle point cloud forecasting by adding a lightweight learned renderer and achieve state-of-the-art performance in Argoverse 2, nuScenes, and KITTI. To further showcase its transferability, we fine-tune our model for BEV semantic occupancy forecasting and show that it outperforms the fully supervised state-of-the-art, especially when labeled data is scarce. Finally, when compared to prior state-of-the-art on spatio-temporal geometric occupancy prediction, our 4D world model achieves a much higher recall of objects from classes relevant to self-driving.
DeTra: A Unified Model for Object Detection and Trajectory Forecasting
Jun 06, 2024The tasks of object detection and trajectory forecasting play a crucial role in understanding the scene for autonomous driving. These tasks are typically executed in a cascading manner, making them prone to compounding errors. Furthermore, there is usually a very thin interface between the two tasks, creating a lossy information bottleneck. To address these challenges, our approach formulates the union of the two tasks as a trajectory refinement problem, where the first pose is the detection (current time), and the subsequent poses are the waypoints of the multiple forecasts (future time). To tackle this unified task, we design a refinement transformer that infers the presence, pose, and multi-modal future behaviors of objects directly from LiDAR point clouds and high-definition maps. We call this model DeTra, short for object Detection and Trajectory forecasting. In our experiments, we observe that \ourmodel{} outperforms the state-of-the-art on Argoverse 2 Sensor and Waymo Open Dataset by a large margin, across a broad range of metrics. Last but not least, we perform extensive ablation studies that show the value of refinement for this task, that every proposed component contributes positively to its performance, and that key design choices were made.
RMP: A Random Mask Pretrain Framework for Motion Prediction
Sep 16, 2023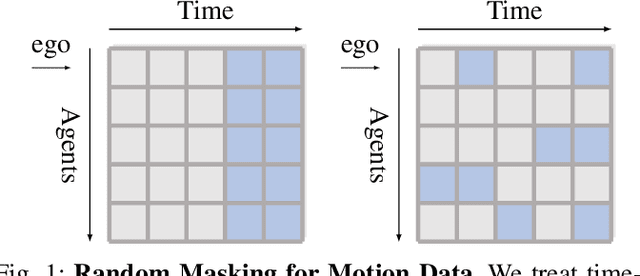
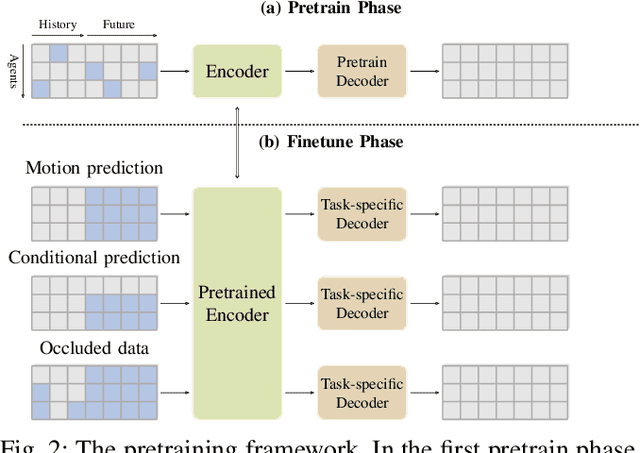
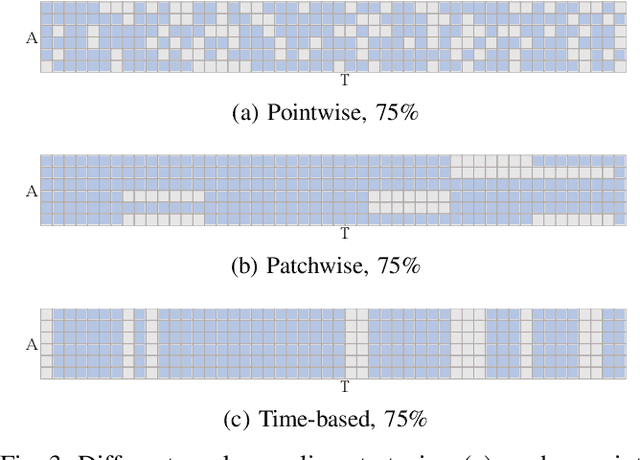
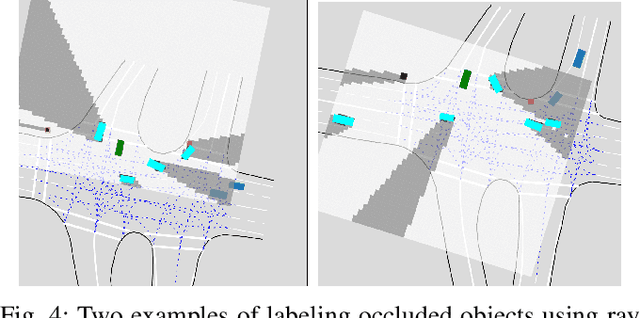
As the pretraining technique is growing in popularity, little work has been done on pretrained learning-based motion prediction methods in autonomous driving. In this paper, we propose a framework to formalize the pretraining task for trajectory prediction of traffic participants. Within our framework, inspired by the random masked model in natural language processing (NLP) and computer vision (CV), objects' positions at random timesteps are masked and then filled in by the learned neural network (NN). By changing the mask profile, our framework can easily switch among a range of motion-related tasks. We show that our proposed pretraining framework is able to deal with noisy inputs and improves the motion prediction accuracy and miss rate, especially for objects occluded over time by evaluating it on Argoverse and NuScenes datasets.
MBAPPE: MCTS-Built-Around Prediction for Planning Explicitly
Sep 15, 2023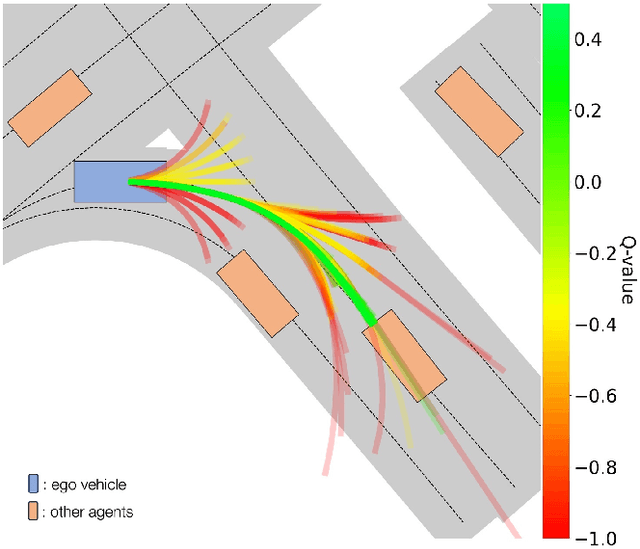
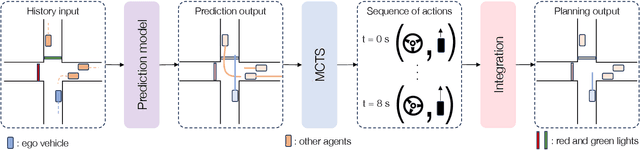
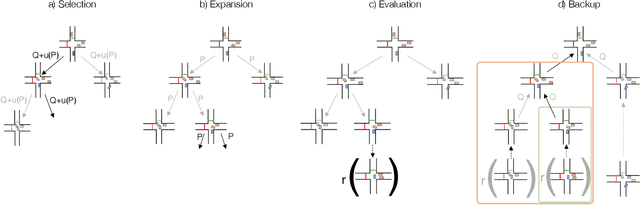
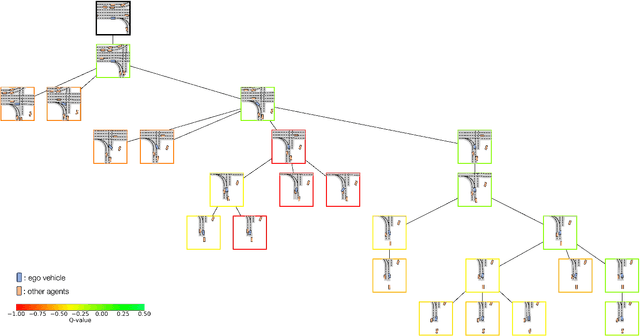
We present MBAPPE, a novel approach to motion planning for autonomous driving combining tree search with a partially-learned model of the environment. Leveraging the inherent explainable exploration and optimization capabilities of the Monte-Carlo Search Tree (MCTS), our method addresses complex decision-making in a dynamic environment. We propose a framework that combines MCTS with supervised learning, enabling the autonomous vehicle to effectively navigate through diverse scenarios. Experimental results demonstrate the effectiveness and adaptability of our approach, showcasing improved real-time decision-making and collision avoidance. This paper contributes to the field by providing a robust solution for motion planning in autonomous driving systems, enhancing their explainability and reliability.
TSGN: Temporal Scene Graph Neural Networks with Projected Vectorized Representation for Multi-Agent Motion Prediction
May 14, 2023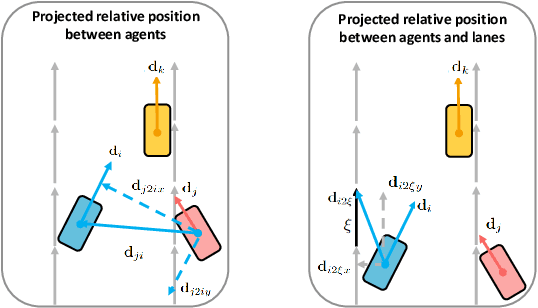
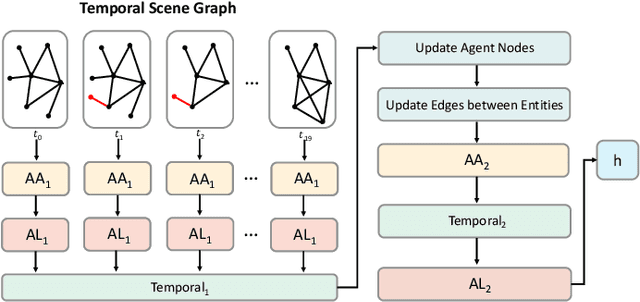
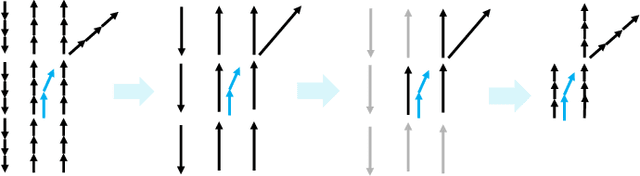
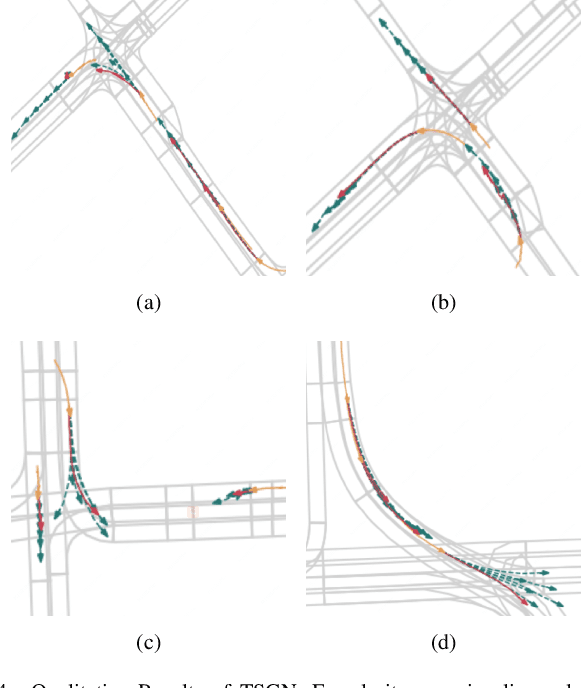
Predicting future motions of nearby agents is essential for an autonomous vehicle to take safe and effective actions. In this paper, we propose TSGN, a framework using Temporal Scene Graph Neural Networks with projected vectorized representations for multi-agent trajectory prediction. Projected vectorized representation models the traffic scene as a graph which is constructed by a set of vectors. These vectors represent agents, road network, and their spatial relative relationships. All relative features under this representation are both translationand rotation-invariant. Based on this representation, TSGN captures the spatial-temporal features across agents, road network, interactions among them, and temporal dependencies of temporal traffic scenes. TSGN can predict multimodal future trajectories for all agents simultaneously, plausibly, and accurately. Meanwhile, we propose a Hierarchical Lane Transformer for capturing interactions between agents and road network, which filters the surrounding road network and only keeps the most probable lane segments which could have an impact on the future behavior of the target agent. Without sacrificing the prediction performance, this greatly reduces the computational burden. Experiments show TSGN achieves state-of-the-art performance on the Argoverse motion forecasting benchmar.
Exploiting map information for self-supervised learning in motion forecasting
Oct 10, 2022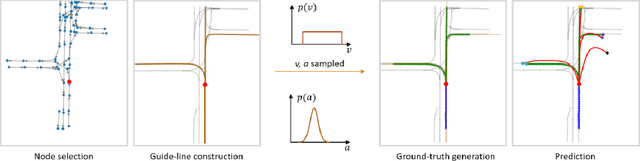
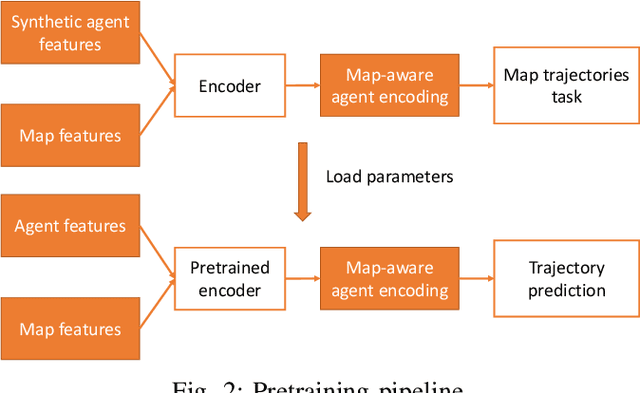
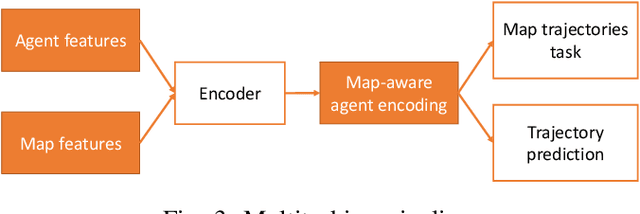
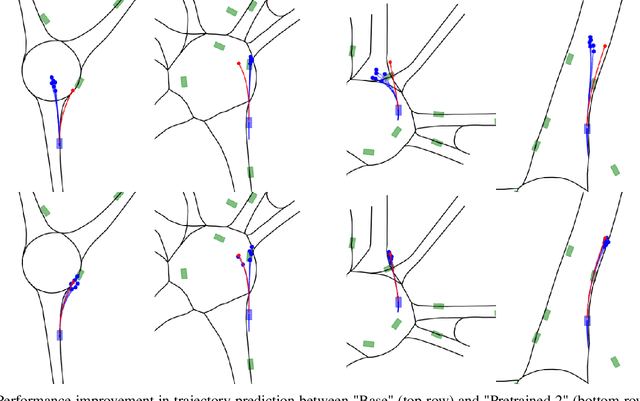
Inspired by recent developments regarding the application of self-supervised learning (SSL), we devise an auxiliary task for trajectory prediction that takes advantage of map-only information such as graph connectivity with the intent of improving map comprehension and generalization. We apply this auxiliary task through two frameworks - multitasking and pretraining. In either framework we observe significant improvement of our baseline in metrics such as $\mathrm{minFDE}_6$ (as much as 20.3%) and $\mathrm{MissRate}_6$ (as much as 33.3%), as well as a richer comprehension of map features demonstrated by different training configurations. The results obtained were consistent in all three data sets used for experiments: Argoverse, Interaction and NuScenes. We also submit our new pretrained model's results to the Interaction challenge and achieve $\textit{1st}$ place with respect to $\mathrm{minFDE}_6$ and $\mathrm{minADE}_6$.
Uncertainty estimation for Cross-dataset performance in Trajectory prediction
May 15, 2022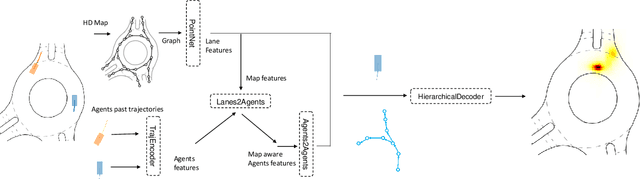
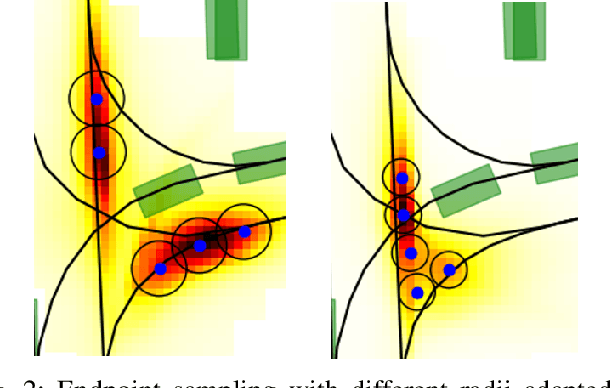
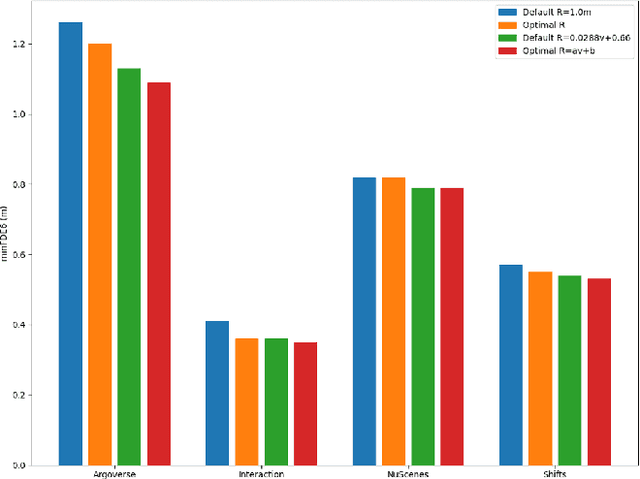
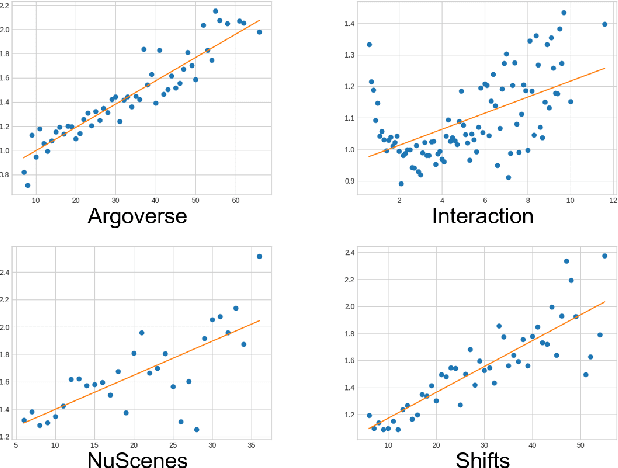
While a lot of work has been done on developing trajectory prediction methods, and various datasets have been proposed for benchmarking this task, little study has been done so far on the generalizability and the transferability of these methods across dataset. In this paper, we study the performance of a state-of-the-art trajectory prediction method across four different datasets (Argoverse, NuScenes, Interaction, Shifts). We first check how a similar method can be applied and trained on all these datasets with similar hyperparameters. Then we highlight which datasets work best on others, and study how uncertainty estimation allows for a better transferable performance; proposing a novel way to estimate uncertainty and to directly use it in prediction.
ImPosIng: Implicit Pose Encoding for Efficient Camera Pose Estimation
May 05, 2022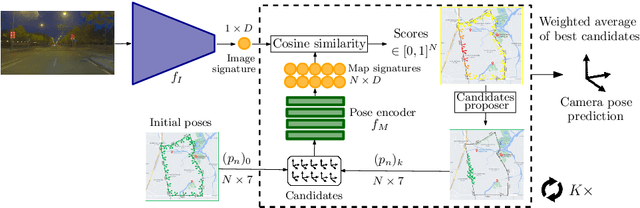
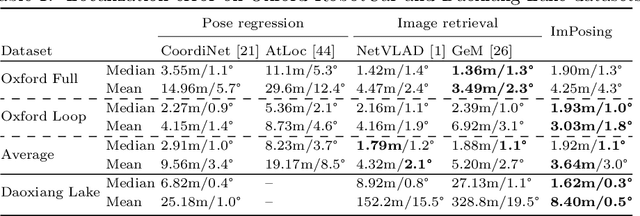


We propose a novel learning-based formulation for camera pose estimation that can perform relocalization accurately and in real-time in city-scale environments. Camera pose estimation algorithms determine the position and orientation from which an image has been captured, using a set of geo-referenced images or 3D scene representation. Our new localization paradigm, named Implicit Pose Encoding (ImPosing), embeds images and camera poses into a common latent representation with 2 separate neural networks, such that we can compute a similarity score for each image-pose pair. By evaluating candidates through the latent space in a hierarchical manner, the camera position and orientation are not directly regressed but incrementally refined. Compared to the representation used in structure-based relocalization methods, our implicit map is memory bounded and can be properly explored to improve localization performances against learning-based regression approaches. In this paper, we describe how to effectively optimize our learned modules, how to combine them to achieve real-time localization, and demonstrate results on diverse large scale scenarios that significantly outperform prior work in accuracy and computational efficiency.
Information Extraction from Visually Rich Documents with Font Style Embeddings
Nov 07, 2021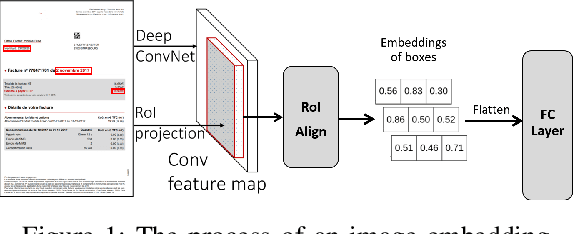
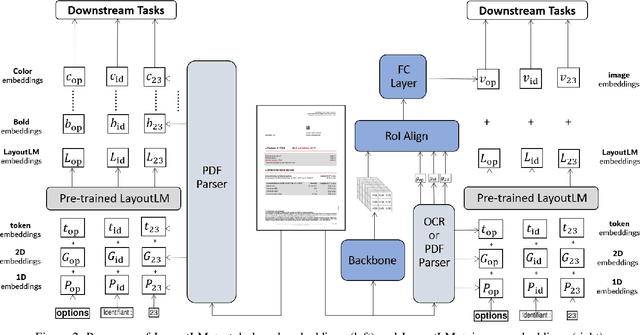


Information extraction (IE) from documents is an intensive area of research with a large set of industrial applications. Current state-of-the-art methods focus on scanned documents with approaches combining computer vision, natural language processing and layout representation. We propose to challenge the usage of computer vision in the case where both token style and visual representation are available (i.e native PDF documents). Our experiments on three real-world complex datasets demonstrate that using token style attributes based embedding instead of a raw visual embedding in LayoutLM model is beneficial. Depending on the dataset, such an embedding yields an improvement of 0.18% to 2.29% in the weighted F1-score with a decrease of 30.7% in the final number of trainable parameters of the model, leading to an improvement in both efficiency and effectiveness.
THOMAS: Trajectory Heatmap Output with learned Multi-Agent Sampling
Oct 17, 2021

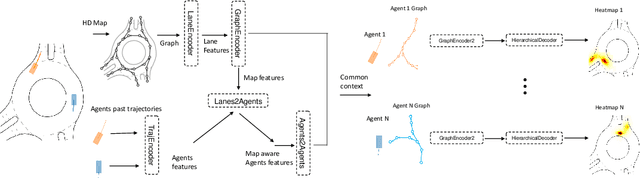

In this paper, we propose THOMAS, a joint multi-agent trajectory prediction framework allowing for efficient and consistent prediction of multi-agent multi-modal trajectories. We present a unified model architecture for fast and simultaneous agent future heatmap estimation leveraging hierarchical and sparse image generation. We demonstrate that heatmap output enables a higher level of control on the predicted trajectories compared to vanilla multi-modal trajectory regression, allowing to incorporate additional constraints for tighter sampling or collision-free predictions in a deterministic way. However, we also highlight that generating scene-consistent predictions goes beyond the mere generation of collision-free trajectories. We therefore propose a learnable trajectory recombination model that takes as input a set of predicted trajectories for each agent and outputs its consistent reordered recombination. We report our results on the Interaction multi-agent prediction challenge and rank $1^{st}$ on the online test leaderboard.