 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Validity in Observers: When to Increase the Complexity of Your Model?
Feb 08, 2025



Model validity is key to the accurate and safe behavior of autonomous vehicles. Using invalid vehicle models in the different plan and control vehicle frameworks puts the stability of the vehicle, and thus its safety at stake. In this work, we analyze the validity of several popular vehicle models used in the literature with respect to a real vehicle and we prove that serious accuracy issues are encountered beyond a specific lateral acceleration point. We set a clear lateral acceleration domain in which the used models are an accurate representation of the behavior of the vehicle. We then target the necessity of using learned methods to model the vehicle's behavior. The effects of model validity on state observers are investigated. The performance of model-based observers is compared to learning-based ones. Overall, the presented work emphasizes the validity of vehicle models and presents clear operational domains in which models could be used safely.
The Hybrid Extended Bicycle: A Simple Model for High Dynamic Vehicle Trajectory Planning
Jun 08, 2023



While highly automated driving relies most of the time on a smooth driving assumption, the possibility of a vehicle performing harsh maneuvers with high dynamic driving to face unexpected events is very likely. The modeling of the behavior of the vehicle in these events is crucial to proper planning and controlling; the used model should present accurate and computationally efficient properties. In this article, we propose an LSTM-based hybrid extended bicycle model able to present an accurate description of the state of the vehicle for both normal and aggressive situations. The introduced model is used in an MPPI framework for planning trajectories in high-dynamic scenarios where other simple models fail.
A Robust Hybrid Observer for Side-slip Angle Estimation
Jun 07, 2023
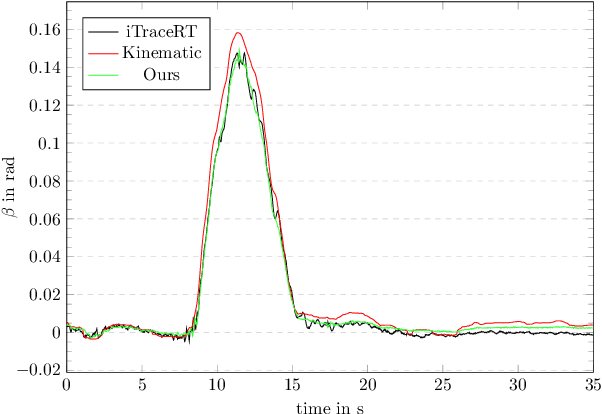
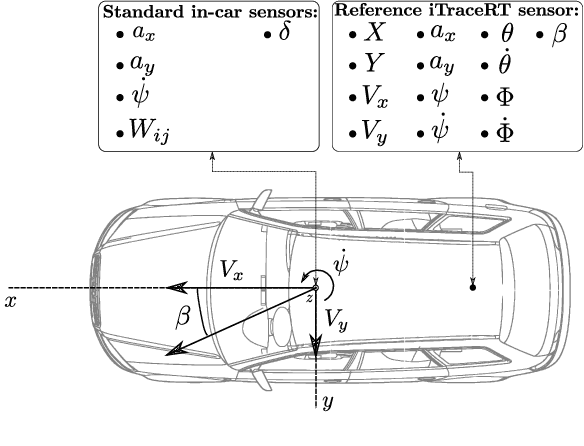
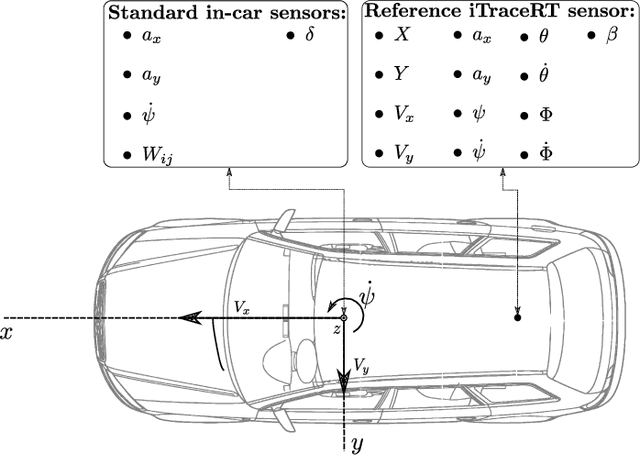
For autonomous driving or advanced driving assistance, it is key to monitor the vehicle dynamics behavior. Accurate models of this behavior include acceleration, but also the side-slip angle, that eventually results from the complex interaction between the tires and the road. Though it is an essential quantity (e.g. for stability assessment), as opposed to accelerations, it is not measurable through conventional off-the-shelf sensors. Therefore, accurate side-slip angle observers are necessary for the proper planning and control of vehicles. In this paper, we introduce a novel approach that combines model-based side-slip angle estimation with neural networks. We apply our approach to real vehicle data. We prove that the proposed method is able to outperform state-of-the-art methods for normal driving maneuvers, and for near-limits maneuvers where providing accurate estimations becomes challenging.
Robust LSTM-based Vehicle Velocity Observer for Regular and Near-limits Applications
Mar 31, 2023
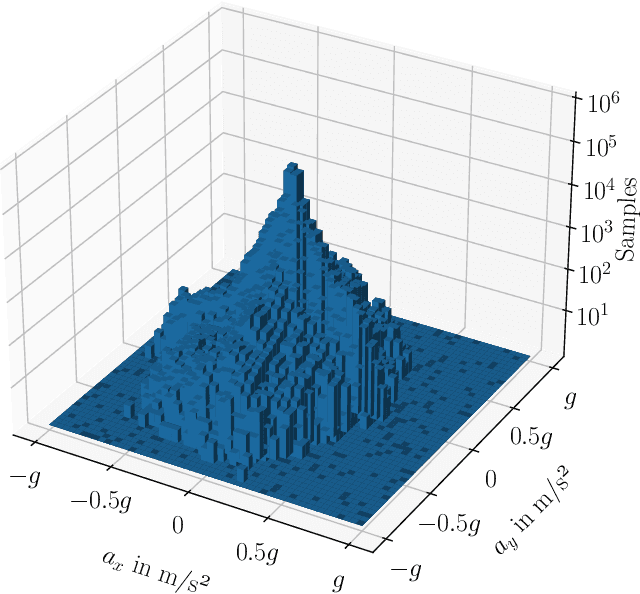
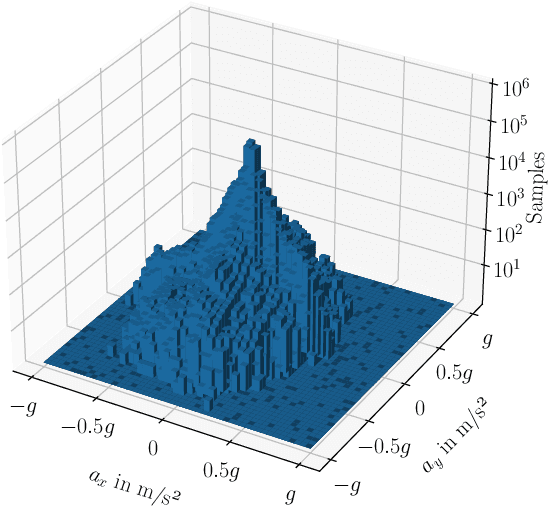
Accurate velocity estimation is key to vehicle control. While the literature describes how model-based and learning-based observers are able to estimate a vehicle's velocity in normal driving conditions, the challenge remains to estimate the velocity in near-limits maneuvers while using only conventional in-car sensors. In this paper, we introduce a novel neural network architecture based on Long Short-Term Memory (LSTM) networks to accurately estimate the vehicle's velocity in different driving conditions, including maneuvers at the limits of handling. The approach has been tested on real vehicle data and it provides more accurate estimations than state-of-the-art model-based and learning-based methods, for both regular and near-limits driving scenarios. Our approach is robust since the performance of the state-of-the-art observers deteriorates with higher dynamics, while our method adapts to different maneuvers, providing accurate estimations even at the vehicle's limits of handling.
Learning-based Observer Evaluated on the Kinematic Bicycle Model
Mar 31, 2023The knowledge of the states of a vehicle is a necessity to perform proper planning and control. These quantities are usually accessible through measurements. Control theory brings extremely useful methods -- observers -- to deal with quantities that cannot be directly measured or with noisy measurements. Classical observers are mathematically derived from models. In spite of their success, such as the Kalman filter, they show their limits when systems display high non-linearities, modeling errors, high uncertainties or difficult interactions with the environment (e.g. road contact). In this work, we present a method to build a learning-based observer able to outperform classical observing methods. We compare several neural network architectures and define the data generation procedure used to train them. The method is evaluated on a kinematic bicycle model which allows to easily generate data for training and testing. This model is also used in an Extended Kalman Filter (EKF) for comparison of the learning-based observer with a state of the art model-based observer. The results prove the interest of our approach and pave the way for future improvements of the technique.
CROSSFIRE: Camera Relocalization On Self-Supervised Features from an Implicit Representation
Mar 08, 2023
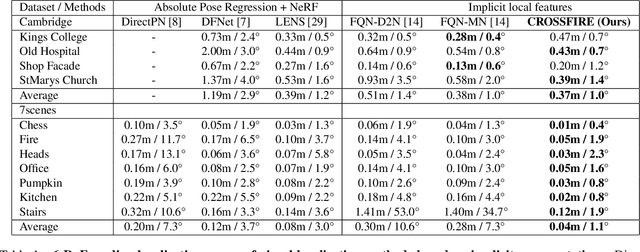
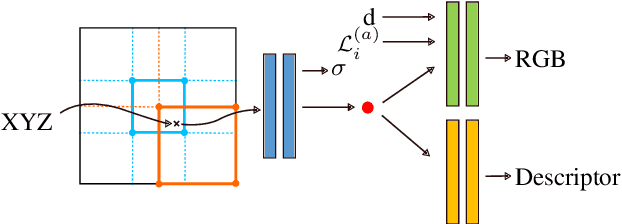
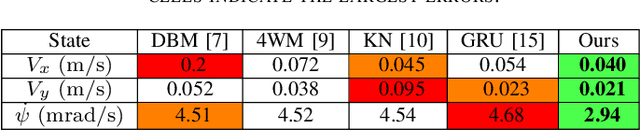
Beyond novel view synthesis, Neural Radiance Fields are useful for applications that interact with the real world. In this paper, we use them as an implicit map of a given scene and propose a camera relocalization algorithm tailored for this representation. The proposed method enables to compute in real-time the precise position of a device using a single RGB camera, during its navigation. In contrast with previous work, we do not rely on pose regression or photometric alignment but rather use dense local features obtained through volumetric rendering which are specialized on the scene with a self-supervised objective. As a result, our algorithm is more accurate than competitors, able to operate in dynamic outdoor environments with changing lightning conditions and can be readily integrated in any volumetric neural renderer.
Unsupervised Multi-object Segmentation Using Attention and Soft-argmax
May 26, 2022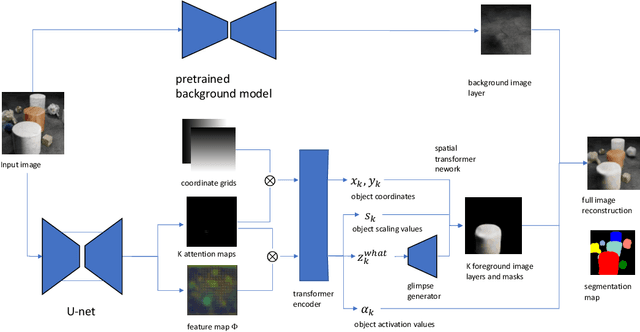
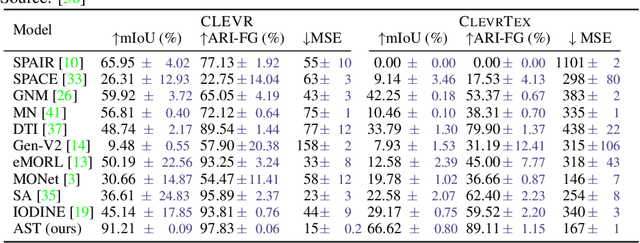


We introduce a new architecture for unsupervised object-centric representation learning and multi-object detection and segmentation, which uses an attention mechanism to associate a feature vector to each object present in the scene and to predict the coordinates of these objects using soft-argmax. A transformer encoder handles occlusions and redundant detections, and a separate pre-trained background model is in charge of background reconstruction. We show that this architecture significantly outperforms the state of the art on complex synthetic benchmarks and provide examples of applications to real-world traffic videos.
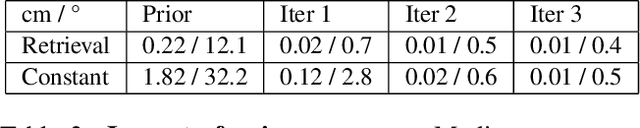
ImPosIng: Implicit Pose Encoding for Efficient Camera Pose Estimation
May 05, 2022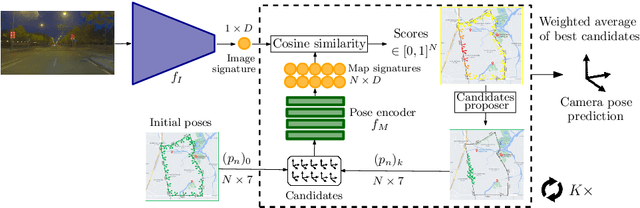
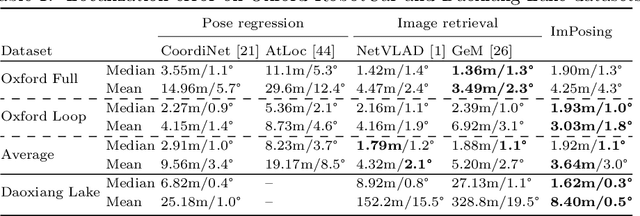


We propose a novel learning-based formulation for camera pose estimation that can perform relocalization accurately and in real-time in city-scale environments. Camera pose estimation algorithms determine the position and orientation from which an image has been captured, using a set of geo-referenced images or 3D scene representation. Our new localization paradigm, named Implicit Pose Encoding (ImPosing), embeds images and camera poses into a common latent representation with 2 separate neural networks, such that we can compute a similarity score for each image-pose pair. By evaluating candidates through the latent space in a hierarchical manner, the camera position and orientation are not directly regressed but incrementally refined. Compared to the representation used in structure-based relocalization methods, our implicit map is memory bounded and can be properly explored to improve localization performances against learning-based regression approaches. In this paper, we describe how to effectively optimize our learned modules, how to combine them to achieve real-time localization, and demonstrate results on diverse large scale scenarios that significantly outperform prior work in accuracy and computational efficiency.
Autoencoder-based background reconstruction and foreground segmentation with background noise estimation
Dec 15, 2021

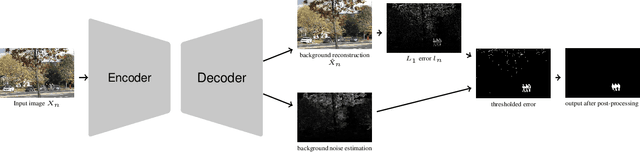
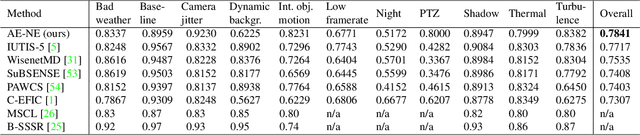
Even after decades of research, dynamic scene background reconstruction and foreground object segmentation are still considered as open problems due various challenges such as illumination changes, camera movements, or background noise caused by air turbulence or moving trees. We propose in this paper to model the background of a video sequence as a low dimensional manifold using an autoencoder and to compare the reconstructed background provided by this autoencoder with the original image to compute the foreground/background segmentation masks. The main novelty of the proposed model is that the autoencoder is also trained to predict the background noise, which allows to compute for each frame a pixel-dependent threshold to perform the background/foreground segmentation. Although the proposed model does not use any temporal or motion information, it exceeds the state of the art for unsupervised background subtraction on the CDnet 2014 and LASIESTA datasets, with a significant improvement on videos where the camera is moving.
LENS: Localization enhanced by NeRF synthesis
Oct 13, 2021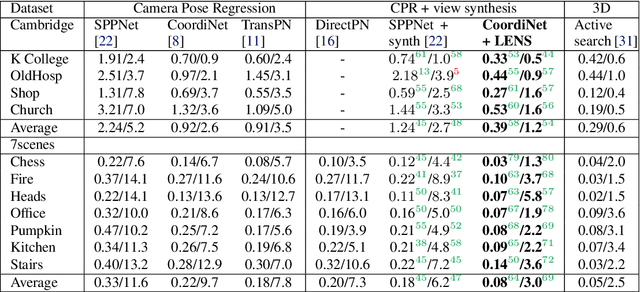
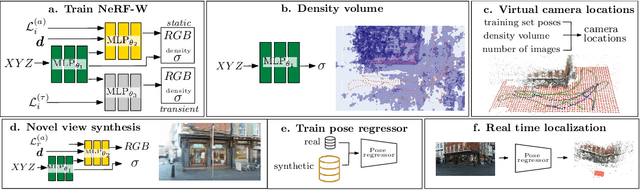

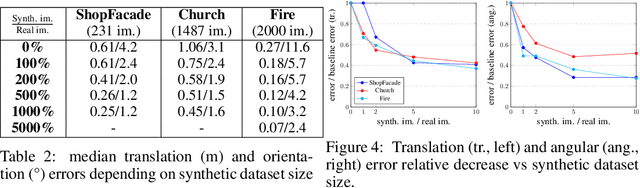
Neural Radiance Fields (NeRF) have recently demonstrated photo-realistic results for the task of novel view synthesis. In this paper, we propose to apply novel view synthesis to the robot relocalization problem: we demonstrate improvement of camera pose regression thanks to an additional synthetic dataset rendered by the NeRF class of algorithm. To avoid spawning novel views in irrelevant places we selected virtual camera locations from NeRF internal representation of the 3D geometry of the scene. We further improved localization accuracy of pose regressors using synthesized realistic and geometry consistent images as data augmentation during training. At the time of publication, our approach improved state of the art with a 60% lower error on Cambridge Landmarks and 7-scenes datasets. Hence, the resulting accuracy becomes comparable to structure-based methods, without any architecture modification or domain adaptation constraints. Since our method allows almost infinite generation of training data, we investigated limitations of camera pose regression depending on size and distribution of data used for training on public benchmarks. We concluded that pose regression accuracy is mostly bounded by relatively small and biased datasets rather than capacity of the pose regression model to solve the localization task.