Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multi-object Segmentation Using Attention and Soft-argmax
Paper and Code
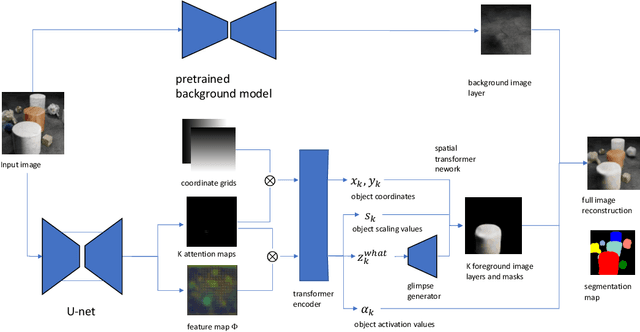
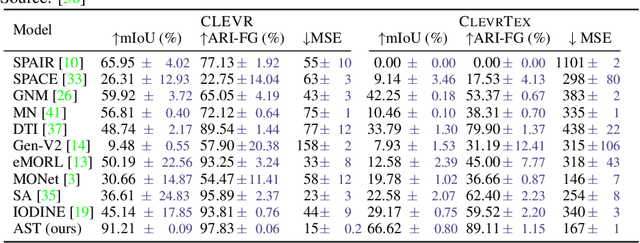


We introduce a new architecture for unsupervised object-centric representation learning and multi-object detection and segmentation, which uses an attention mechanism to associate a feature vector to each object present in the scene and to predict the coordinates of these objects using soft-argmax. A transformer encoder handles occlusions and redundant detections, and a separate pre-trained background model is in charge of background reconstruction. We show that this architecture significantly outperforms the state of the art on complex synthetic benchmarks and provide examples of applications to real-world traffic videos.
View paper on