 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRVS: a Generalizable and Recurrent Approach to Monocular Dynamic View Synthesis
Mar 31, 2026Synthesizing novel views from monocular videos of dynamic scenes remains a challenging problem. Scene-specific methods that optimize 4D representations with explicit motion priors often break down in highly dynamic regions where multi-view information is hard to exploit. Diffusion-based approaches that integrate camera control into large pre-trained models can produce visually plausible videos but frequently suffer from geometric inconsistencies across both static and dynamic areas. Both families of methods also require substantial computational resources. Building on the success of generalizable models for static novel view synthesis, we adapt the framework to dynamic inputs and propose a new model with two key components: (1) a recurrent loop that enables unbounded and asynchronous mapping between input and target videos and (2) an efficient use of plane sweeps over dynamic inputs to disentangle camera and scene motion, and achieve fine-grained, six-degrees-of-freedom camera controls. We train and evaluate our model on the UCSD dataset and on Kubric-4D-dyn, a new monocular dynamic dataset featuring longer, higher resolution sequences with more complex scene dynamics than existing alternatives. Our model outperforms four Gaussian Splatting-based scene-specific approaches, as well as two diffusion-based approaches in reconstructing fine-grained geometric details across both static and dynamic regions.
ICo3D: An Interactive Conversational 3D Virtual Human
Jan 19, 2026This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others. Project page: https://ico3d.github.io/
Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
Dec 17, 2025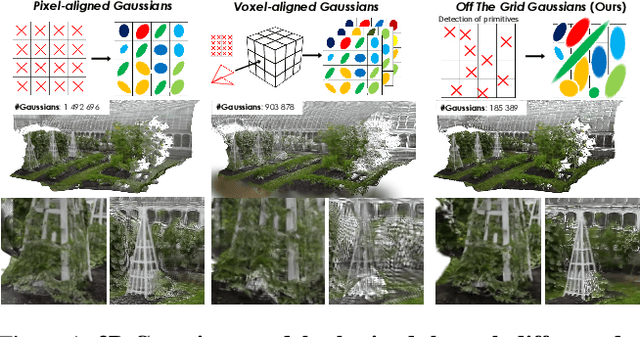
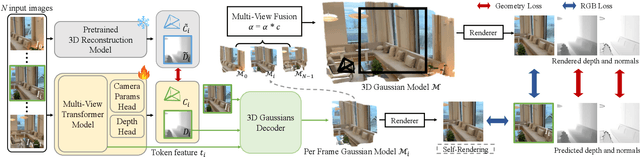


Feed-forward 3D Gaussian Splatting (3DGS) models enable real-time scene generation but are hindered by suboptimal pixel-aligned primitive placement, which relies on a dense, rigid grid and limits both quality and efficiency. We introduce a new feed-forward architecture that detects 3D Gaussian primitives at a sub-pixel level, replacing the pixel grid with an adaptive, "Off The Grid" distribution. Inspired by keypoint detection, our multi-resolution decoder learns to distribute primitives across image patches. This module is trained end-to-end with a 3D reconstruction backbone using self-supervised learning. Our resulting pose-free model generates photorealistic scenes in seconds, achieving state-of-the-art novel view synthesis for feed-forward models. It outperforms competitors while using far fewer primitives, demonstrating a more accurate and efficient allocation that captures fine details and reduces artifacts. Moreover, we observe that by learning to render 3D Gaussians, our 3D reconstruction backbone improves camera pose estimation, suggesting opportunities to train these foundational models without labels.
Charge: A Comprehensive Novel View Synthesis Benchmark and Dataset to Bind Them All
Dec 15, 2025This paper presents a new dataset for Novel View Synthesis, generated from a high-quality, animated film with stunning realism and intricate detail. Our dataset captures a variety of dynamic scenes, complete with detailed textures, lighting, and motion, making it ideal for training and evaluating cutting-edge 4D scene reconstruction and novel view generation models. In addition to high-fidelity RGB images, we provide multiple complementary modalities, including depth, surface normals, object segmentation and optical flow, enabling a deeper understanding of scene geometry and motion. The dataset is organised into three distinct benchmarking scenarios: a dense multi-view camera setup, a sparse camera arrangement, and monocular video sequences, enabling a wide range of experimentation and comparison across varying levels of data sparsity. With its combination of visual richness, high-quality annotations, and diverse experimental setups, this dataset offers a unique resource for pushing the boundaries of view synthesis and 3D vision.
Better Together: Unified Motion Capture and 3D Avatar Reconstruction
Mar 12, 2025We present Better Together, a method that simultaneously solves the human pose estimation problem while reconstructing a photorealistic 3D human avatar from multi-view videos. While prior art usually solves these problems separately, we argue that joint optimization of skeletal motion with a 3D renderable body model brings synergistic effects, i.e. yields more precise motion capture and improved visual quality of real-time rendering of avatars. To achieve this, we introduce a novel animatable avatar with 3D Gaussians rigged on a personalized mesh and propose to optimize the motion sequence with time-dependent MLPs that provide accurate and temporally consistent pose estimates. We first evaluate our method on highly challenging yoga poses and demonstrate state-of-the-art accuracy on multi-view human pose estimation, reducing error by 35% on body joints and 45% on hand joints compared to keypoint-based methods. At the same time, our method significantly boosts the visual quality of animatable avatars (+2dB PSNR on novel view synthesis) on diverse challenging subjects.
GASPACHO: Gaussian Splatting for Controllable Humans and Objects
Mar 12, 2025We present GASPACHO: a method for generating photorealistic controllable renderings of human-object interactions. Given a set of multi-view RGB images of human-object interactions, our method reconstructs animatable templates of the human and object as separate sets of Gaussians simultaneously. Different from existing work, which focuses on human reconstruction and ignores objects as background, our method explicitly reconstructs both humans and objects, thereby allowing for controllable renderings of novel human object interactions in different poses from novel-camera viewpoints. During reconstruction, we constrain the Gaussians that generate rendered images to be a linear function of a set of canonical Gaussians. By simply changing the parameters of the linear deformation functions after training, our method can generate renderings of novel human-object interaction in novel poses from novel camera viewpoints. We learn the 3D Gaussian properties of the canonical Gaussians on the underlying 2D manifold of the canonical human and object templates. This in turns requires a canonical object template with a fixed UV unwrapping. To define such an object template, we use a feature based representation to track the object across the multi-view sequence. We further propose an occlusion aware photometric loss that allows for reconstructions under significant occlusions. Several experiments on two human-object datasets - BEHAVE and DNA-Rendering - demonstrate that our method allows for high-quality reconstruction of human and object templates under significant occlusion and the synthesis of controllable renderings of novel human-object interactions in novel human poses from novel camera views.
SCRREAM : SCan, Register, REnder And Map:A Framework for Annotating Accurate and Dense 3D Indoor Scenes with a Benchmark
Oct 30, 2024



Traditionally, 3d indoor datasets have generally prioritized scale over ground-truth accuracy in order to obtain improved generalization. However, using these datasets to evaluate dense geometry tasks, such as depth rendering, can be problematic as the meshes of the dataset are often incomplete and may produce wrong ground truth to evaluate the details. In this paper, we propose SCRREAM, a dataset annotation framework that allows annotation of fully dense meshes of objects in the scene and registers camera poses on the real image sequence, which can produce accurate ground truth for both sparse 3D as well as dense 3D tasks. We show the details of the dataset annotation pipeline and showcase four possible variants of datasets that can be obtained from our framework with example scenes, such as indoor reconstruction and SLAM, scene editing & object removal, human reconstruction and 6d pose estimation. Recent pipelines for indoor reconstruction and SLAM serve as new benchmarks. In contrast to previous indoor dataset, our design allows to evaluate dense geometry tasks on eleven sample scenes against accurately rendered ground truth depth maps.
3DGS-Calib: 3D Gaussian Splatting for Multimodal SpatioTemporal Calibration
Mar 18, 2024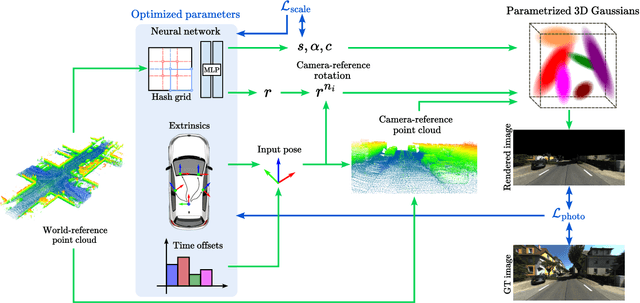
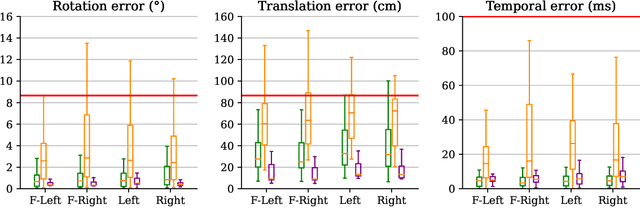
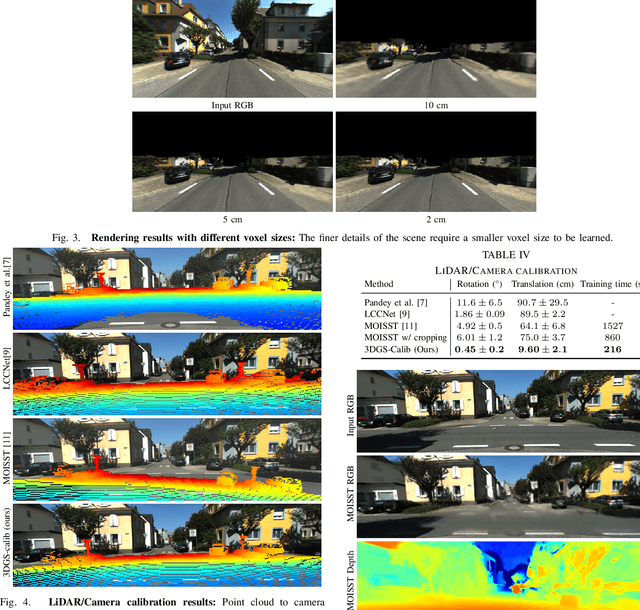
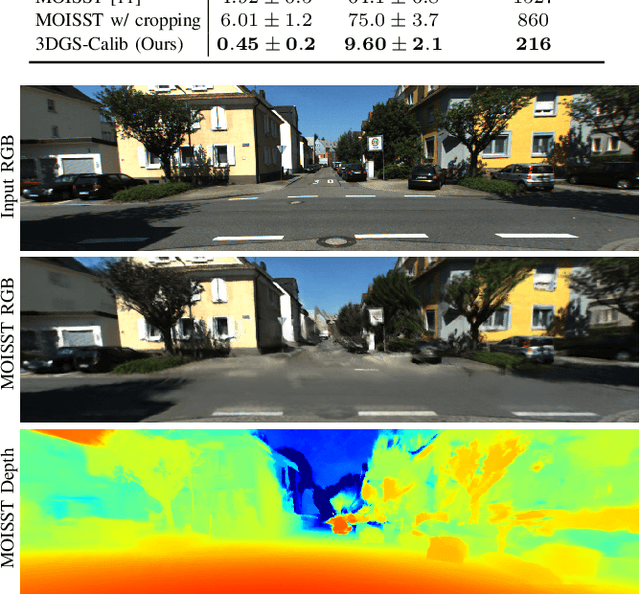
Reliable multimodal sensor fusion algorithms require accurate spatiotemporal calibration. Recently, targetless calibration techniques based on implicit neural representations have proven to provide precise and robust results. Nevertheless, such methods are inherently slow to train given the high computational overhead caused by the large number of sampled points required for volume rendering. With the recent introduction of 3D Gaussian Splatting as a faster alternative to implicit representation methods, we propose to leverage this new rendering approach to achieve faster multi-sensor calibration. We introduce 3DGS-Calib, a new calibration method that relies on the speed and rendering accuracy of 3D Gaussian Splatting to achieve multimodal spatiotemporal calibration that is accurate, robust, and with a substantial speed-up compared to methods relying on implicit neural representations. We demonstrate the superiority of our proposal with experimental results on sequences from KITTI-360, a widely used driving dataset.
SWAGS: Sampling Windows Adaptively for Dynamic 3D Gaussian Splatting
Dec 20, 2023Novel view synthesis has shown rapid progress recently, with methods capable of producing evermore photo-realistic results. 3D Gaussian Splatting has emerged as a particularly promising method, producing high-quality renderings of static scenes and enabling interactive viewing at real-time frame rates. However, it is currently limited to static scenes only. In this work, we extend 3D Gaussian Splatting to reconstruct dynamic scenes. We model the dynamics of a scene using a tunable MLP, which learns the deformation field from a canonical space to a set of 3D Gaussians per frame. To disentangle the static and dynamic parts of the scene, we learn a tuneable parameter for each Gaussian, which weighs the respective MLP parameters to focus attention on the dynamic parts. This improves the model's ability to capture dynamics in scenes with an imbalance of static to dynamic regions. To handle scenes of arbitrary length whilst maintaining high rendering quality, we introduce an adaptive window sampling strategy to partition the sequence into windows based on the amount of movement in the sequence. We train a separate dynamic Gaussian Splatting model for each window, allowing the canonical representation to change, thus enabling the reconstruction of scenes with significant geometric or topological changes. Temporal consistency is enforced using a fine-tuning step with self-supervising consistency loss on randomly sampled novel views. As a result, our method produces high-quality renderings of general dynamic scenes with competitive quantitative performance, which can be viewed in real-time with our dynamic interactive viewer.
HeadGaS: Real-Time Animatable Head Avatars via 3D Gaussian Splatting
Dec 05, 2023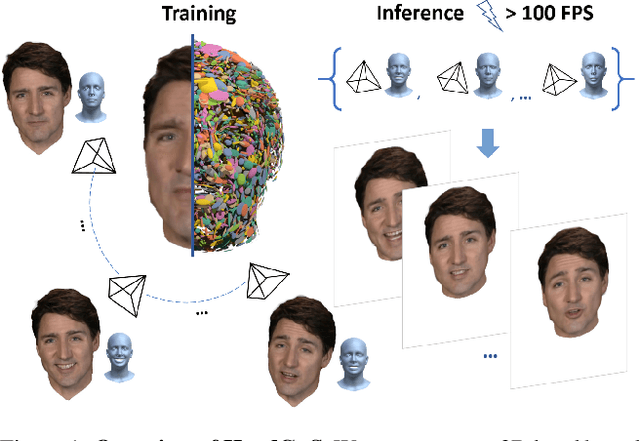
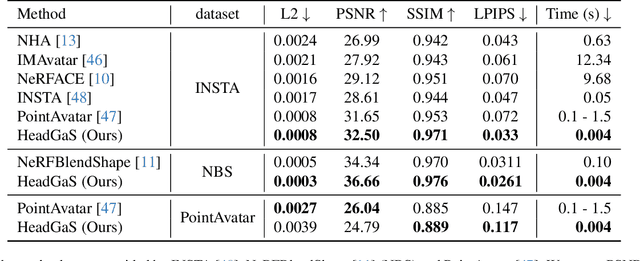
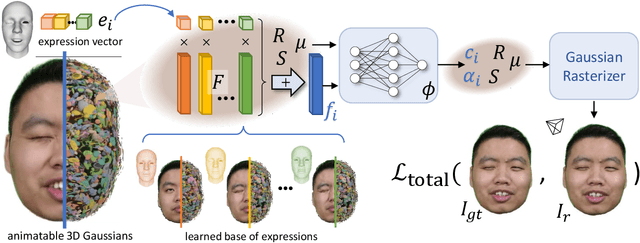
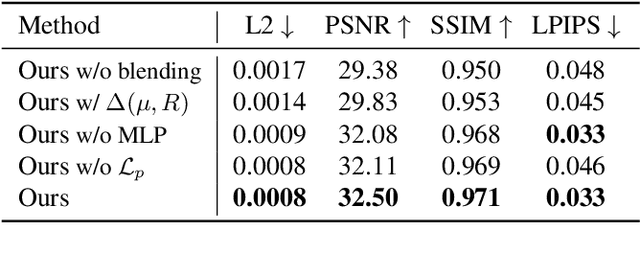
3D head animation has seen major quality and runtime improvements over the last few years, particularly empowered by the advances in differentiable rendering and neural radiance fields. Real-time rendering is a highly desirable goal for real-world applications. We propose HeadGaS, the first model to use 3D Gaussian Splats (3DGS) for 3D head reconstruction and animation. In this paper we introduce a hybrid model that extends the explicit representation from 3DGS with a base of learnable latent features, which can be linearly blended with low-dimensional parameters from parametric head models to obtain expression-dependent final color and opacity values. We demonstrate that HeadGaS delivers state-of-the-art results in real-time inference frame rates, which surpasses baselines by up to ~2dB, while accelerating rendering speed by over x10.