 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Optimization for Autonomous Driving Datasets using Neural Rendering Models
Apr 22, 2025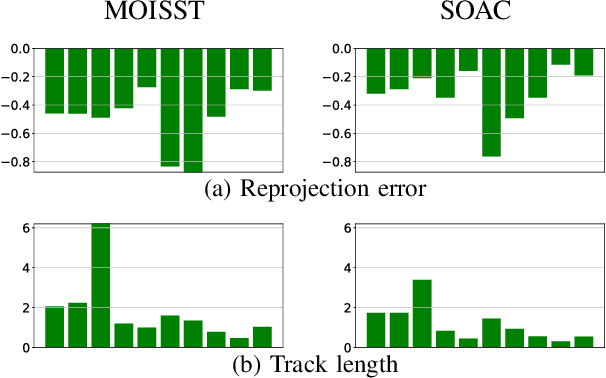
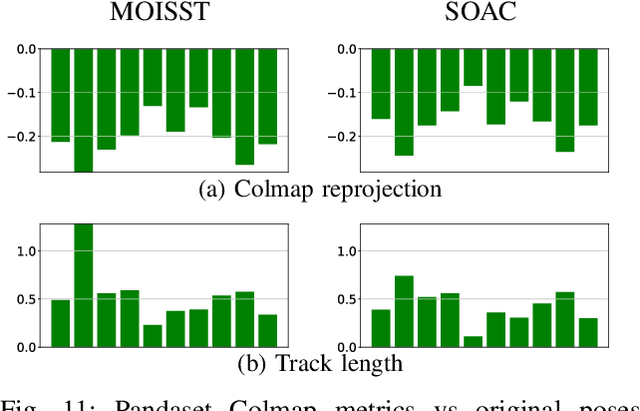
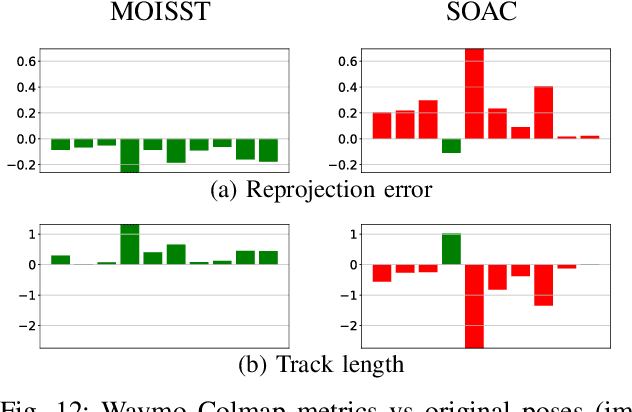
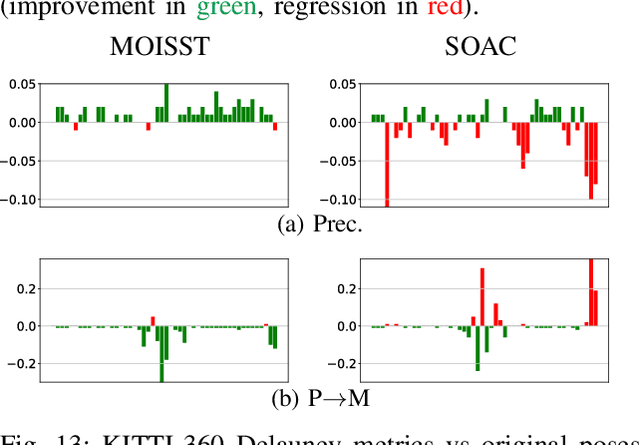
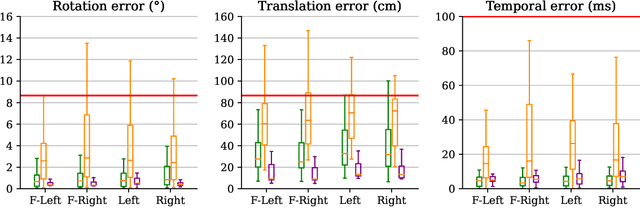
Autonomous driving systems rely on accurate perception and localization of the ego car to ensure safety and reliability in challenging real-world driving scenarios. Public datasets play a vital role in benchmarking and guiding advancement in research by providing standardized resources for model development and evaluation. However, potential inaccuracies in sensor calibration and vehicle poses within these datasets can lead to erroneous evaluations of downstream tasks, adversely impacting the reliability and performance of the autonomous systems. To address this challenge, we propose a robust optimization method based on Neural Radiance Fields (NeRF) to refine sensor poses and calibration parameters, enhancing the integrity of dataset benchmarks. To validate improvement in accuracy of our optimized poses without ground truth, we present a thorough evaluation process, relying on reprojection metrics, Novel View Synthesis rendering quality, and geometric alignment. We demonstrate that our method achieves significant improvements in sensor pose accuracy. By optimizing these critical parameters, our approach not only improves the utility of existing datasets but also paves the way for more reliable autonomous driving models. To foster continued progress in this field, we make the optimized sensor poses publicly available, providing a valuable resource for the research community.
3DGS-Calib: 3D Gaussian Splatting for Multimodal SpatioTemporal Calibration
Mar 18, 2024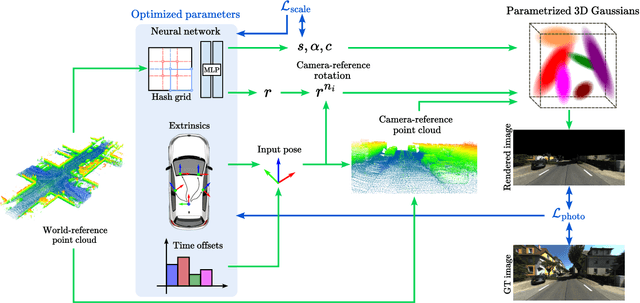
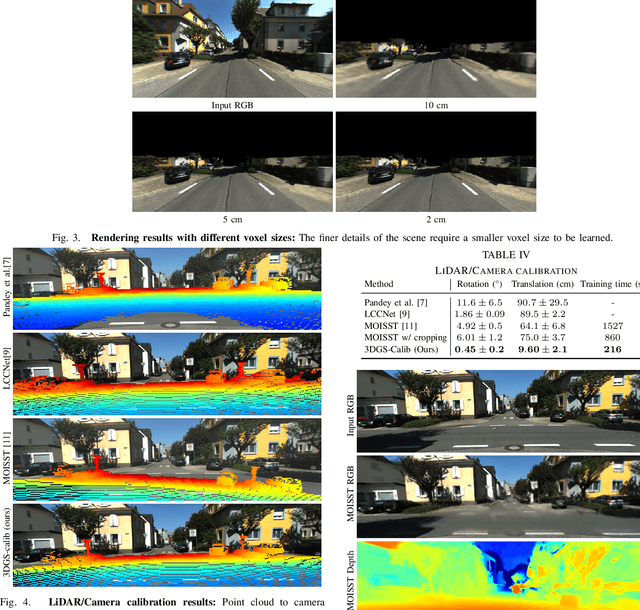
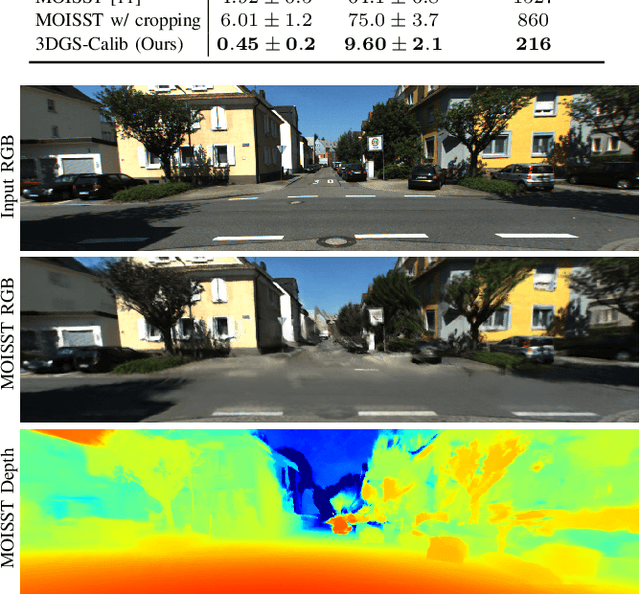
Reliable multimodal sensor fusion algorithms require accurate spatiotemporal calibration. Recently, targetless calibration techniques based on implicit neural representations have proven to provide precise and robust results. Nevertheless, such methods are inherently slow to train given the high computational overhead caused by the large number of sampled points required for volume rendering. With the recent introduction of 3D Gaussian Splatting as a faster alternative to implicit representation methods, we propose to leverage this new rendering approach to achieve faster multi-sensor calibration. We introduce 3DGS-Calib, a new calibration method that relies on the speed and rendering accuracy of 3D Gaussian Splatting to achieve multimodal spatiotemporal calibration that is accurate, robust, and with a substantial speed-up compared to methods relying on implicit neural representations. We demonstrate the superiority of our proposal with experimental results on sequences from KITTI-360, a widely used driving dataset.
SOAC: Spatio-Temporal Overlap-Aware Multi-Sensor Calibration using Neural Radiance Fields
Nov 27, 2023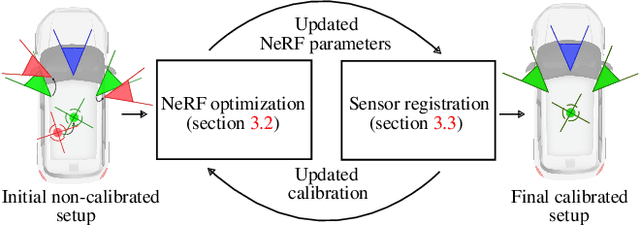

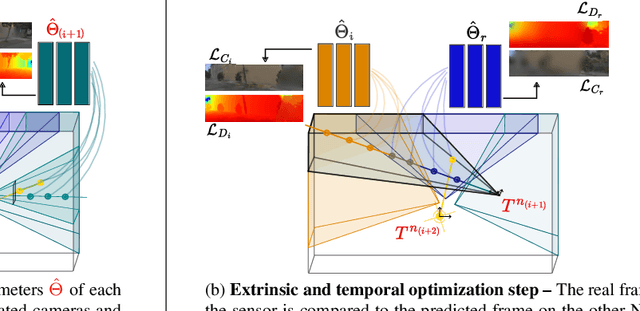

In rapidly-evolving domains such as autonomous driving, the use of multiple sensors with different modalities is crucial to ensure high operational precision and stability. To correctly exploit the provided information by each sensor in a single common frame, it is essential for these sensors to be accurately calibrated. In this paper, we leverage the ability of Neural Radiance Fields (NeRF) to represent different sensors modalities in a common volumetric representation to achieve robust and accurate spatio-temporal sensor calibration. By designing a partitioning approach based on the visible part of the scene for each sensor, we formulate the calibration problem using only the overlapping areas. This strategy results in a more robust and accurate calibration that is less prone to failure. We demonstrate that our approach works on outdoor urban scenes by validating it on multiple established driving datasets. Results show that our method is able to get better accuracy and robustness compared to existing methods.
MOISST: Multi-modal Optimization of Implicit Scene for SpatioTemporal calibration
Mar 07, 2023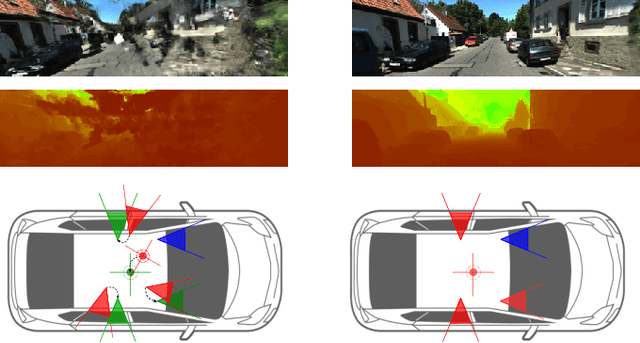
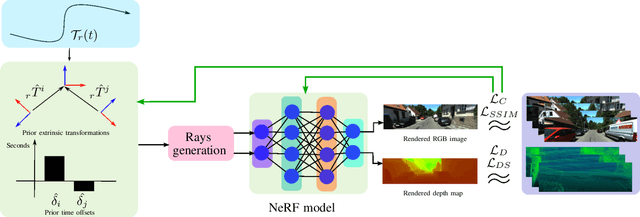

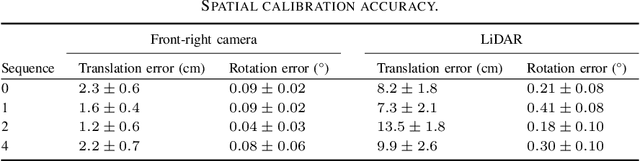
With the recent advances in autonomous driving and the decreasing cost of LiDARs, the use of multi-modal sensor systems is on the rise. However, in order to make use of the information provided by a variety of complimentary sensors, it is necessary to accurately calibrate them. We take advantage of recent advances in computer graphics and implicit volumetric scene representation to tackle the problem of multi-sensor spatial and temporal calibration. Thanks to a new formulation of the implicit model optimization, we are able to jointly optimize calibration parameters along with scene representation based on radiometric and geometric measurements. Our method enables accurate and robust calibration from data captured in uncontrolled and unstructured urban environments, making our solution more scalable than existing calibration solutions. We demonstrate the accuracy and robustness of our method in urban scenes typically encountered in autonomous driving scenarios.