 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEM-ROVER: Semantic Voxel-Guided Diffusion for Large-Scale Driving Scene Generation
Apr 07, 2026Scalable generation of outdoor driving scenes requires 3D representations that remain consistent across multiple viewpoints and scale to large areas. Existing solutions either rely on image or video generative models distilled to 3D space, harming the geometric coherence and restricting the rendering to training views, or are limited to small-scale 3D scene or object-centric generation. In this work, we propose a 3D generative framework based on $Σ$-Voxfield grid, a discrete representation where each occupied voxel stores a fixed number of colorized surface samples. To generate this representation, we train a semantic-conditioned diffusion model that operates on local voxel neighborhoods and uses 3D positional encodings to capture spatial structure. We scale to large scenes via progressive spatial outpainting over overlapping regions. Finally, we render the generated $Σ$-Voxfield grid with a deferred rendering module to obtain photorealistic images, enabling large-scale multiview-consistent 3D scene generation without per-scene optimization. Extensive experiments show that our approach can generate diverse large-scale urban outdoor scenes, renderable into photorealistic images with various sensor configurations and camera trajectories while maintaining moderate computation cost compared to existing approaches.
LESV: Language Embedded Sparse Voxel Fusion for Open-Vocabulary 3D Scene Understanding
Apr 01, 2026Recent advancements in open-vocabulary 3D scene understanding heavily rely on 3D Gaussian Splatting (3DGS) to register vision-language features into 3D space. However, we identify two critical limitations in these approaches: the spatial ambiguity arising from unstructured, overlapping Gaussians which necessitates probabilistic feature registration, and the multi-level semantic ambiguity caused by pooling features over object-level masks, which dilutes fine-grained details. To address these challenges, we present a novel framework that leverages Sparse Voxel Rasterization (SVRaster) as a structured, disjoint geometry representation. By regularizing SVRaster with monocular depth and normal priors, we establish a stable geometric foundation. This enables a deterministic, confidence-aware feature registration process and suppresses the semantic bleeding artifact common in 3DGS. Furthermore, we resolve multi-level ambiguity by exploiting the emerging dense alignment properties of foundation model AM-RADIO, avoiding the computational overhead of hierarchical training methods. Our approach achieves state-of-the-art performance on Open Vocabulary 3D Object Retrieval and Point Cloud Understanding benchmarks, particularly excelling on fine-grained queries where registration methods typically fail.
SAIL: Self-supervised Albedo Estimation from Real Images with a Latent Diffusion Model
May 26, 2025Intrinsic image decomposition aims at separating an image into its underlying albedo and shading components, isolating the base color from lighting effects to enable downstream applications such as virtual relighting and scene editing. Despite the rise and success of learning-based approaches, intrinsic image decomposition from real-world images remains a significant challenging task due to the scarcity of labeled ground-truth data. Most existing solutions rely on synthetic data as supervised setups, limiting their ability to generalize to real-world scenes. Self-supervised methods, on the other hand, often produce albedo maps that contain reflections and lack consistency under different lighting conditions. To address this, we propose SAIL, an approach designed to estimate albedo-like representations from single-view real-world images. We repurpose the prior knowledge of a latent diffusion model for unconditioned scene relighting as a surrogate objective for albedo estimation. To extract the albedo, we introduce a novel intrinsic image decomposition fully formulated in the latent space. To guide the training of our latent diffusion model, we introduce regularization terms that constrain both the lighting-dependent and independent components of our latent image decomposition. SAIL predicts stable albedo under varying lighting conditions and generalizes to multiple scenes, using only unlabeled multi-illumination data available online.
CoStruction: Conjoint radiance field optimization for urban scene reconStruction with limited image overlap
Jan 07, 2025



Reconstructing the surrounding surface geometry from recorded driving sequences poses a significant challenge due to the limited image overlap and complex topology of urban environments. SoTA neural implicit surface reconstruction methods often struggle in such setting, either failing due to small vision overlap or exhibiting suboptimal performance in accurately reconstructing both the surface and fine structures. To address these limitations, we introduce CoStruction, a novel hybrid implicit surface reconstruction method tailored for large driving sequences with limited camera overlap. CoStruction leverages cross-representation uncertainty estimation to filter out ambiguous geometry caused by limited observations. Our method performs joint optimization of both radiance fields in addition to guided sampling achieving accurate reconstruction of large areas along with fine structures in complex urban scenarios. Extensive evaluation on major driving datasets demonstrates the superiority of our approach in reconstructing large driving sequences with limited image overlap, outperforming concurrent SoTA methods.
Pointmap-Conditioned Diffusion for Consistent Novel View Synthesis
Jan 06, 2025



In this paper, we present PointmapDiffusion, a novel framework for single-image novel view synthesis (NVS) that utilizes pre-trained 2D diffusion models. Our method is the first to leverage pointmaps (i.e. rasterized 3D scene coordinates) as a conditioning signal, capturing geometric prior from the reference images to guide the diffusion process. By embedding reference attention blocks and a ControlNet for pointmap features, our model balances between generative capability and geometric consistency, enabling accurate view synthesis across varying viewpoints. Extensive experiments on diverse real-world datasets demonstrate that PointmapDiffusion achieves high-quality, multi-view consistent results with significantly fewer trainable parameters compared to other baselines for single-image NVS tasks.
SCILLA: SurfaCe Implicit Learning for Large Urban Area, a volumetric hybrid solution
Mar 15, 2024



Neural implicit surface representation methods have recently shown impressive 3D reconstruction results. However, existing solutions struggle to reconstruct urban outdoor scenes due to their large, unbounded, and highly detailed nature. Hence, to achieve accurate reconstructions, additional supervision data such as LiDAR, strong geometric priors, and long training times are required. To tackle such issues, we present SCILLA, a new hybrid implicit surface learning method to reconstruct large driving scenes from 2D images. SCILLA's hybrid architecture models two separate implicit fields: one for the volumetric density and another for the signed distance to the surface. To accurately represent urban outdoor scenarios, we introduce a novel volume-rendering strategy that relies on self-supervised probabilistic density estimation to sample points near the surface and transition progressively from volumetric to surface representation. Our solution permits a proper and fast initialization of the signed distance field without relying on any geometric prior on the scene, compared to concurrent methods. By conducting extensive experiments on four outdoor driving datasets, we show that SCILLA can learn an accurate and detailed 3D surface scene representation in various urban scenarios while being two times faster to train compared to previous state-of-the-art solutions.
RoDUS: Robust Decomposition of Static and Dynamic Elements in Urban Scenes
Mar 14, 2024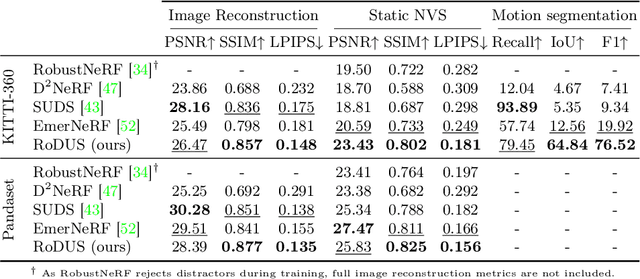
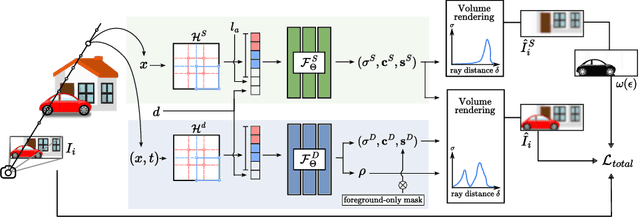
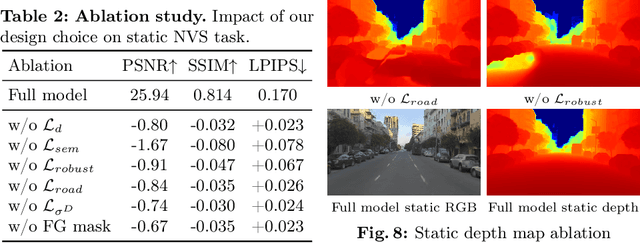
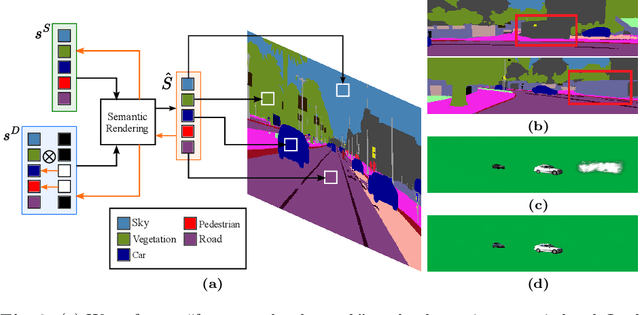
The task of separating dynamic objects from static environments using NeRFs has been widely studied in recent years. However, capturing large-scale scenes still poses a challenge due to their complex geometric structures and unconstrained dynamics. Without the help of 3D motion cues, previous methods often require simplified setups with slow camera motion and only a few/single dynamic actors, leading to suboptimal solutions in most urban setups. To overcome such limitations, we present RoDUS, a pipeline for decomposing static and dynamic elements in urban scenes, with thoughtfully separated NeRF models for moving and non-moving components. Our approach utilizes a robust kernel-based initialization coupled with 4D semantic information to selectively guide the learning process. This strategy enables accurate capturing of the dynamics in the scene, resulting in reduced artifacts caused by NeRF on background reconstruction, all by using self-supervision. Notably, experimental evaluations on KITTI-360 and Pandaset datasets demonstrate the effectiveness of our method in decomposing challenging urban scenes into precise static and dynamic components.
SOAC: Spatio-Temporal Overlap-Aware Multi-Sensor Calibration using Neural Radiance Fields
Nov 27, 2023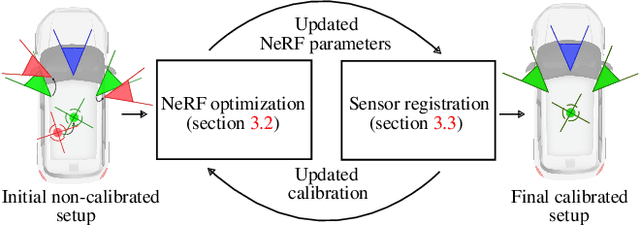

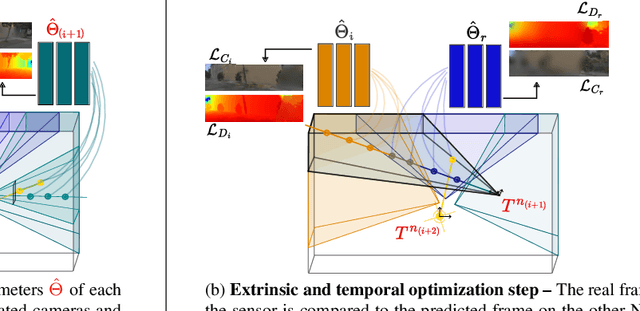

In rapidly-evolving domains such as autonomous driving, the use of multiple sensors with different modalities is crucial to ensure high operational precision and stability. To correctly exploit the provided information by each sensor in a single common frame, it is essential for these sensors to be accurately calibrated. In this paper, we leverage the ability of Neural Radiance Fields (NeRF) to represent different sensors modalities in a common volumetric representation to achieve robust and accurate spatio-temporal sensor calibration. By designing a partitioning approach based on the visible part of the scene for each sensor, we formulate the calibration problem using only the overlapping areas. This strategy results in a more robust and accurate calibration that is less prone to failure. We demonstrate that our approach works on outdoor urban scenes by validating it on multiple established driving datasets. Results show that our method is able to get better accuracy and robustness compared to existing methods.
PlaNeRF: SVD Unsupervised 3D Plane Regularization for NeRF Large-Scale Scene Reconstruction
Jun 06, 2023



Neural Radiance Fields (NeRF) enable 3D scene reconstruction from 2D images and camera poses for Novel View Synthesis (NVS). Although NeRF can produce photorealistic results, it often suffers from overfitting to training views, leading to poor geometry reconstruction, especially in low-texture areas. This limitation restricts many important applications which require accurate geometry, such as extrapolated NVS, HD mapping and scene editing. To address this limitation, we propose a new method to improve NeRF's 3D structure using only RGB images and semantic maps. Our approach introduces a novel plane regularization based on Singular Value Decomposition (SVD), that does not rely on any geometric prior. In addition, we leverage the Structural Similarity Index Measure (SSIM) in our loss design to properly initialize the volumetric representation of NeRF. Quantitative and qualitative results show that our method outperforms popular regularization approaches in accurate geometry reconstruction for large-scale outdoor scenes and achieves SoTA rendering quality on the KITTI-360 NVS benchmark.
MOISST: Multi-modal Optimization of Implicit Scene for SpatioTemporal calibration
Mar 07, 2023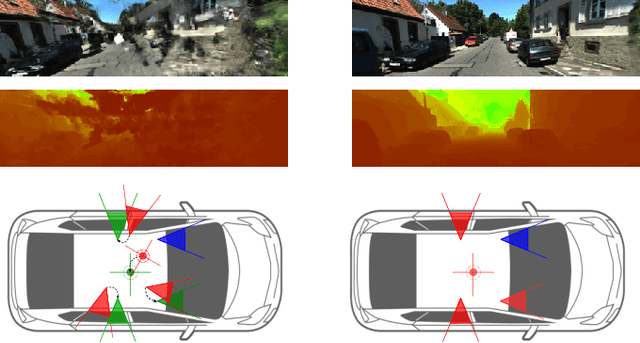
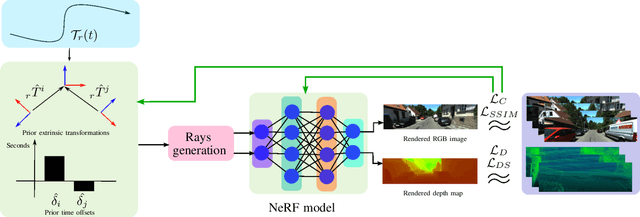

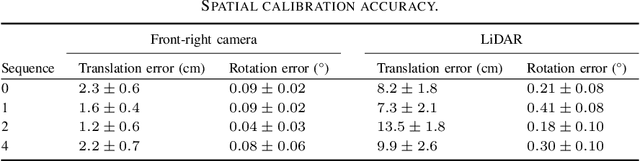
With the recent advances in autonomous driving and the decreasing cost of LiDARs, the use of multi-modal sensor systems is on the rise. However, in order to make use of the information provided by a variety of complimentary sensors, it is necessary to accurately calibrate them. We take advantage of recent advances in computer graphics and implicit volumetric scene representation to tackle the problem of multi-sensor spatial and temporal calibration. Thanks to a new formulation of the implicit model optimization, we are able to jointly optimize calibration parameters along with scene representation based on radiometric and geometric measurements. Our method enables accurate and robust calibration from data captured in uncontrolled and unstructured urban environments, making our solution more scalable than existing calibration solutions. We demonstrate the accuracy and robustness of our method in urban scenes typically encountered in autonomous driving scenarios.