 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointmap-Conditioned Diffusion for Consistent Novel View Synthesis
Jan 06, 2025



In this paper, we present PointmapDiffusion, a novel framework for single-image novel view synthesis (NVS) that utilizes pre-trained 2D diffusion models. Our method is the first to leverage pointmaps (i.e. rasterized 3D scene coordinates) as a conditioning signal, capturing geometric prior from the reference images to guide the diffusion process. By embedding reference attention blocks and a ControlNet for pointmap features, our model balances between generative capability and geometric consistency, enabling accurate view synthesis across varying viewpoints. Extensive experiments on diverse real-world datasets demonstrate that PointmapDiffusion achieves high-quality, multi-view consistent results with significantly fewer trainable parameters compared to other baselines for single-image NVS tasks.
A New Real-World Video Dataset for the Comparison of Defogging Algorithms
Oct 02, 2023
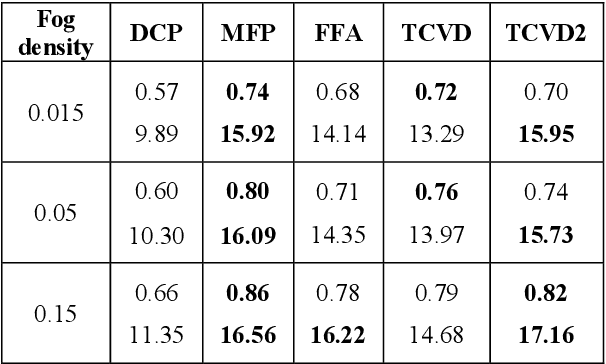

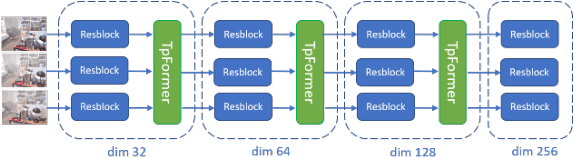
Video restoration for noise removal, deblurring or super-resolution is attracting more and more attention in the fields of image processing and computer vision. Works on video restoration with data-driven approaches for fog removal are rare however, due to the lack of datasets containing videos in both clear and foggy conditions which are required for deep learning and benchmarking. A new dataset, called REVIDE, was recently proposed for just that purpose. In this paper, we implement the same approach by proposing a new REal-world VIdeo dataset for the comparison of Defogging Algorithms (VIREDA), with various fog densities and ground truths without fog. This small database can serve as a test base for defogging algorithms. A video defogging algorithm is also mentioned (still under development), with the key idea of using temporal redundancy to minimize artefacts and exposure variations between frames. Inspired by the success of Transformers architecture in deep learning for various applications, we select this kind of architecture in a neural network to show the relevance of the proposed dataset.