 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEM-ROVER: Semantic Voxel-Guided Diffusion for Large-Scale Driving Scene Generation
Apr 07, 2026Scalable generation of outdoor driving scenes requires 3D representations that remain consistent across multiple viewpoints and scale to large areas. Existing solutions either rely on image or video generative models distilled to 3D space, harming the geometric coherence and restricting the rendering to training views, or are limited to small-scale 3D scene or object-centric generation. In this work, we propose a 3D generative framework based on $Σ$-Voxfield grid, a discrete representation where each occupied voxel stores a fixed number of colorized surface samples. To generate this representation, we train a semantic-conditioned diffusion model that operates on local voxel neighborhoods and uses 3D positional encodings to capture spatial structure. We scale to large scenes via progressive spatial outpainting over overlapping regions. Finally, we render the generated $Σ$-Voxfield grid with a deferred rendering module to obtain photorealistic images, enabling large-scale multiview-consistent 3D scene generation without per-scene optimization. Extensive experiments show that our approach can generate diverse large-scale urban outdoor scenes, renderable into photorealistic images with various sensor configurations and camera trajectories while maintaining moderate computation cost compared to existing approaches.
Pointmap-Conditioned Diffusion for Consistent Novel View Synthesis
Jan 06, 2025



In this paper, we present PointmapDiffusion, a novel framework for single-image novel view synthesis (NVS) that utilizes pre-trained 2D diffusion models. Our method is the first to leverage pointmaps (i.e. rasterized 3D scene coordinates) as a conditioning signal, capturing geometric prior from the reference images to guide the diffusion process. By embedding reference attention blocks and a ControlNet for pointmap features, our model balances between generative capability and geometric consistency, enabling accurate view synthesis across varying viewpoints. Extensive experiments on diverse real-world datasets demonstrate that PointmapDiffusion achieves high-quality, multi-view consistent results with significantly fewer trainable parameters compared to other baselines for single-image NVS tasks.
A New Real-World Video Dataset for the Comparison of Defogging Algorithms
Oct 02, 2023
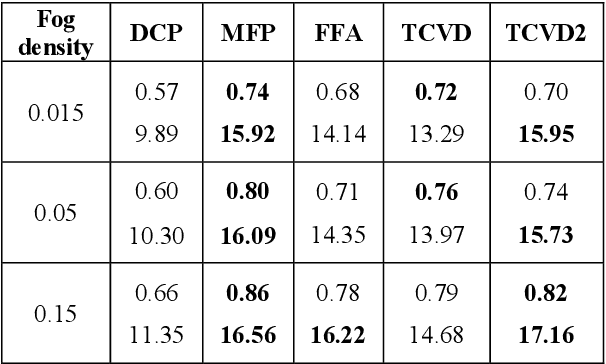

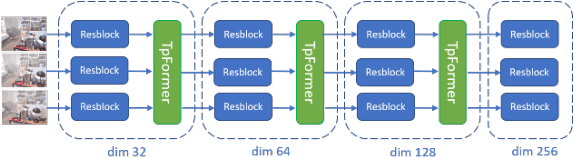
Video restoration for noise removal, deblurring or super-resolution is attracting more and more attention in the fields of image processing and computer vision. Works on video restoration with data-driven approaches for fog removal are rare however, due to the lack of datasets containing videos in both clear and foggy conditions which are required for deep learning and benchmarking. A new dataset, called REVIDE, was recently proposed for just that purpose. In this paper, we implement the same approach by proposing a new REal-world VIdeo dataset for the comparison of Defogging Algorithms (VIREDA), with various fog densities and ground truths without fog. This small database can serve as a test base for defogging algorithms. A video defogging algorithm is also mentioned (still under development), with the key idea of using temporal redundancy to minimize artefacts and exposure variations between frames. Inspired by the success of Transformers architecture in deep learning for various applications, we select this kind of architecture in a neural network to show the relevance of the proposed dataset.
On the Diagnostic of Road Pathway Visibility
Jan 21, 2016
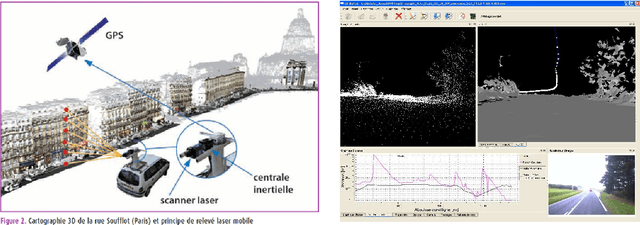

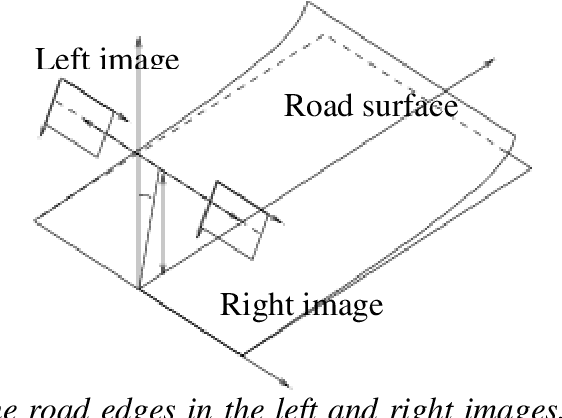
Visibility distance on the road pathway plays a significant role in road safety and in particular, has a clear impact on the choice of speed limits. Visibility distance is thus of importance for road engineers and authorities. While visibility distance criteria are routinely taken into account in road design, only a few systems exist for estimating it on existing road networks. Most existing systems comprise a target vehicle followed at a constant distance by an observer vehicle, which only allows to check if a given, fixed visibility distance is available. We propose two new approaches that allow estimating the maximum available visibility distance, involving only one vehicle and based on different sensor technologies, namely binocular stereovision and 3D range sensing (LIDAR). The first approach is based on the processing of two views taken by digital cameras onboard the diagnostic vehicle. The main stages of the process are: road segmentation, edge registration between the two views, road profile 3D reconstruction and finally, maximal road visibility distance estimation. The second approach involves the use of a Terrestrial LIDAR Mobile Mapping System. The triangulated 3D model of the road and its surroundings provided by the system is used to simulate targets at different distances, which allows estimating the maximum geometric visibility distance along the pathway. These approaches were developed in the context of the SARI-VIZIR PREDIT project. Both approaches are described, evaluated and compared. Their pros and cons with respect to vehicle following systems are also discussed.