 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParisLuco3D: A high-quality target dataset for domain generalization of LiDAR perception
Oct 25, 2023

LiDAR is a sensor system that supports autonomous driving by gathering precise geometric information about the scene. Exploiting this information for perception is interesting as the amount of available data increases. As the quantitative performance of various perception tasks has improved, the focus has shifted from source-to-source perception to domain adaptation and domain generalization for perception. These new goals require access to a large variety of domains for evaluation. Unfortunately, the various annotation strategies of data providers complicate the computation of cross-domain performance based on the available data This paper provides a novel dataset, specifically designed for cross-domain evaluation to make it easier to evaluate the performance of various source datasets. Alongside the dataset, a flexible online benchmark is provided to ensure a fair comparison across methods.
Domain generalization of 3D semantic segmentation in autonomous driving
Dec 07, 2022



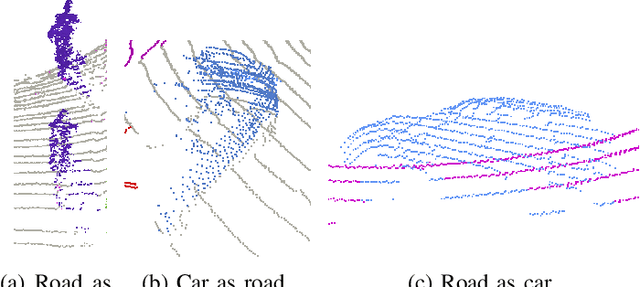
3D autonomous driving semantic segmentation using deep learning has become, a well-studied subject, providing methods that can reach very high performance. Nonetheless, because of the limited size of the training datasets, these models cannot see every type of object and scenes found in real-world applications. The ability to be reliable in these various unknown environments is called domain generalization. Despite its importance, domain generalization is relatively unexplored in the case of 3D autonomous driving semantic segmentation. To fill this gap, this paper presents the first benchmark for this application by testing state-of-the-art methods and discussing the difficulty of tackling LiDAR domain shifts. We also propose the first method designed to address this domain generalization, which we call 3DLabelProp. This method relies on leveraging the geometry and sequentiality of the LiDAR data to enhance its generalization performances by working on partially accumulated point clouds. It reaches a mIoU of 52.6% on SemanticPOSS while being trained only on SemanticKITTI, making it state-of-the-art method for generalization (+7.4% better than the second best method). The code for this method will be available on Github.
On the Diagnostic of Road Pathway Visibility
Jan 21, 2016
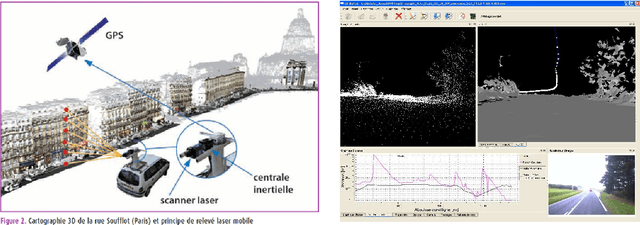

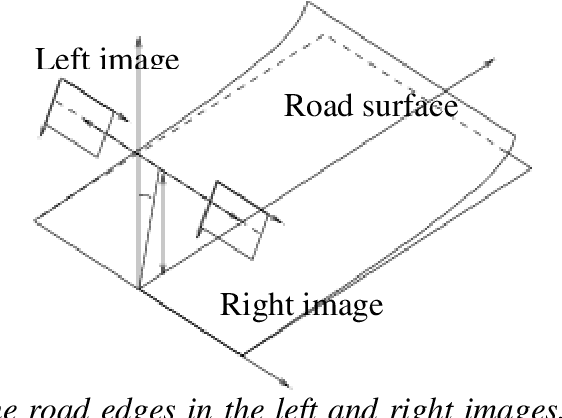
Visibility distance on the road pathway plays a significant role in road safety and in particular, has a clear impact on the choice of speed limits. Visibility distance is thus of importance for road engineers and authorities. While visibility distance criteria are routinely taken into account in road design, only a few systems exist for estimating it on existing road networks. Most existing systems comprise a target vehicle followed at a constant distance by an observer vehicle, which only allows to check if a given, fixed visibility distance is available. We propose two new approaches that allow estimating the maximum available visibility distance, involving only one vehicle and based on different sensor technologies, namely binocular stereovision and 3D range sensing (LIDAR). The first approach is based on the processing of two views taken by digital cameras onboard the diagnostic vehicle. The main stages of the process are: road segmentation, edge registration between the two views, road profile 3D reconstruction and finally, maximal road visibility distance estimation. The second approach involves the use of a Terrestrial LIDAR Mobile Mapping System. The triangulated 3D model of the road and its surroundings provided by the system is used to simulate targets at different distances, which allows estimating the maximum geometric visibility distance along the pathway. These approaches were developed in the context of the SARI-VIZIR PREDIT project. Both approaches are described, evaluated and compared. Their pros and cons with respect to vehicle following systems are also discussed.