 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DLabelProp: Geometric-Driven Domain Generalization for LiDAR Semantic Segmentation in Autonomous Driving
Jan 24, 2025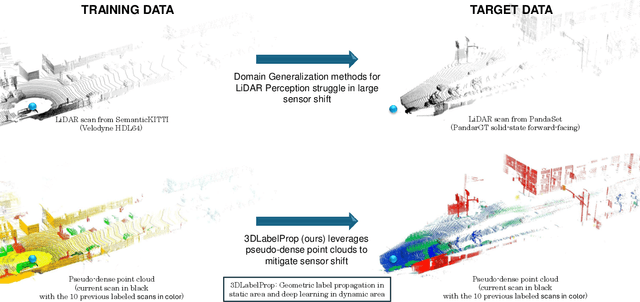

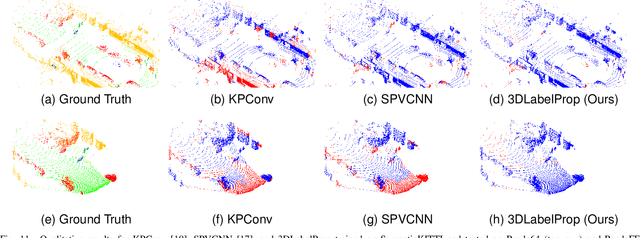

Domain generalization aims to find ways for deep learning models to maintain their performance despite significant domain shifts between training and inference datasets. This is particularly important for models that need to be robust or are costly to train. LiDAR perception in autonomous driving is impacted by both of these concerns, leading to the emergence of various approaches. This work addresses the challenge by proposing a geometry-based approach, leveraging the sequential structure of LiDAR sensors, which sets it apart from the learning-based methods commonly found in the literature. The proposed method, called 3DLabelProp, is applied on the task of LiDAR Semantic Segmentation (LSS). Through extensive experimentation on seven datasets, it is demonstrated to be a state-of-the-art approach, outperforming both naive and other domain generalization methods.
COLA: COarse-LAbel multi-source LiDAR semantic segmentation for autonomous driving
Nov 06, 2023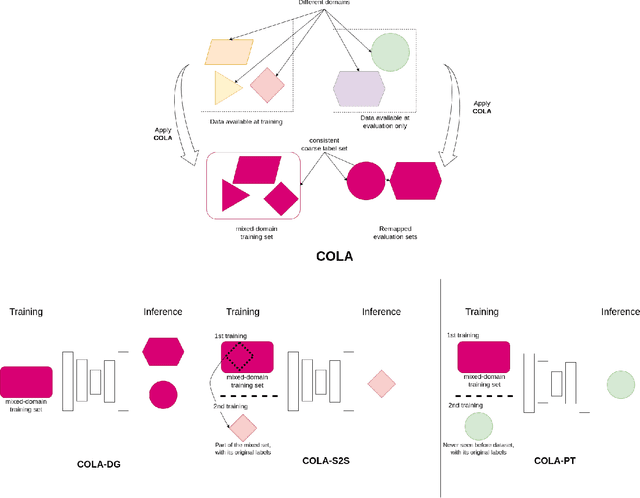
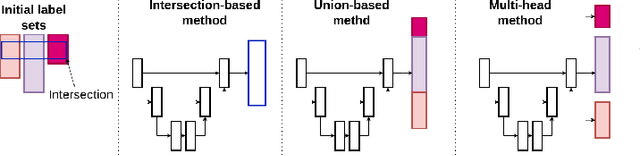
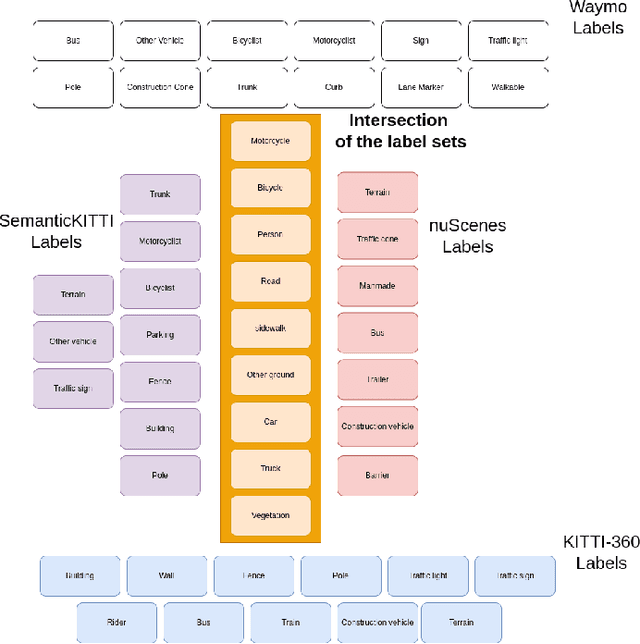
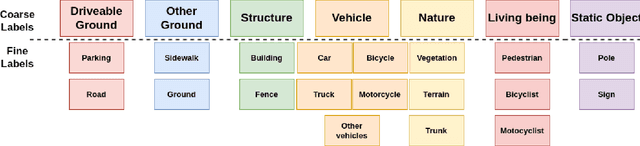
LiDAR semantic segmentation for autonomous driving has been a growing field of interest in the past few years. Datasets and methods have appeared and expanded very quickly, but methods have not been updated to exploit this new availability of data and continue to rely on the same classical datasets. Different ways of performing LIDAR semantic segmentation training and inference can be divided into several subfields, which include the following: domain generalization, the ability to segment data coming from unseen domains ; source-to-source segmentation, the ability to segment data coming from the training domain; and pre-training, the ability to create re-usable geometric primitives. In this work, we aim to improve results in all of these subfields with the novel approach of multi-source training. Multi-source training relies on the availability of various datasets at training time and uses them together rather than relying on only one dataset. To overcome the common obstacles found for multi-source training, we introduce the coarse labels and call the newly created multi-source dataset COLA. We propose three applications of this new dataset that display systematic improvement over single-source strategies: COLA-DG for domain generalization (up to +10%), COLA-S2S for source-to-source segmentation (up to +5.3%), and COLA-PT for pre-training (up to +12%).
ParisLuco3D: A high-quality target dataset for domain generalization of LiDAR perception
Oct 25, 2023
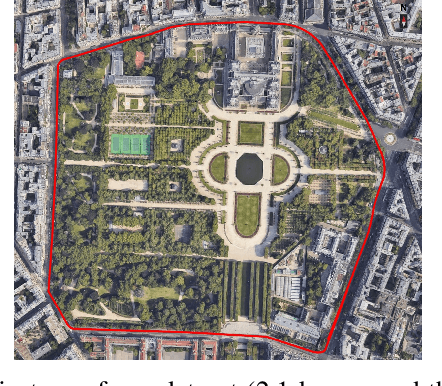

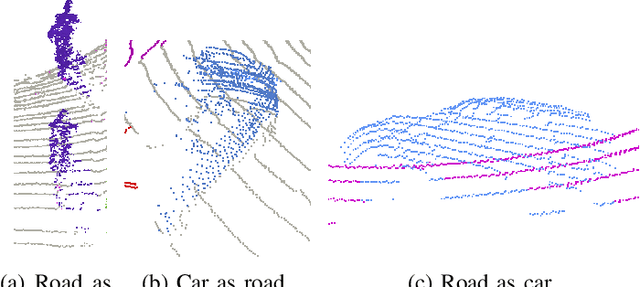
LiDAR is a sensor system that supports autonomous driving by gathering precise geometric information about the scene. Exploiting this information for perception is interesting as the amount of available data increases. As the quantitative performance of various perception tasks has improved, the focus has shifted from source-to-source perception to domain adaptation and domain generalization for perception. These new goals require access to a large variety of domains for evaluation. Unfortunately, the various annotation strategies of data providers complicate the computation of cross-domain performance based on the available data This paper provides a novel dataset, specifically designed for cross-domain evaluation to make it easier to evaluate the performance of various source datasets. Alongside the dataset, a flexible online benchmark is provided to ensure a fair comparison across methods.
Domain generalization of 3D semantic segmentation in autonomous driving
Dec 07, 2022



3D autonomous driving semantic segmentation using deep learning has become, a well-studied subject, providing methods that can reach very high performance. Nonetheless, because of the limited size of the training datasets, these models cannot see every type of object and scenes found in real-world applications. The ability to be reliable in these various unknown environments is called domain generalization. Despite its importance, domain generalization is relatively unexplored in the case of 3D autonomous driving semantic segmentation. To fill this gap, this paper presents the first benchmark for this application by testing state-of-the-art methods and discussing the difficulty of tackling LiDAR domain shifts. We also propose the first method designed to address this domain generalization, which we call 3DLabelProp. This method relies on leveraging the geometry and sequentiality of the LiDAR data to enhance its generalization performances by working on partially accumulated point clouds. It reaches a mIoU of 52.6% on SemanticPOSS while being trained only on SemanticKITTI, making it state-of-the-art method for generalization (+7.4% better than the second best method). The code for this method will be available on Github.
COLA: COarse LAbel pre-training for 3D semantic segmentation of sparse LiDAR datasets
Feb 14, 2022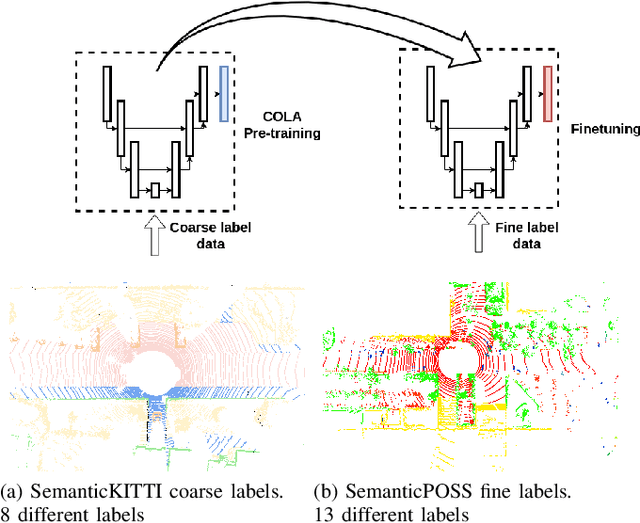


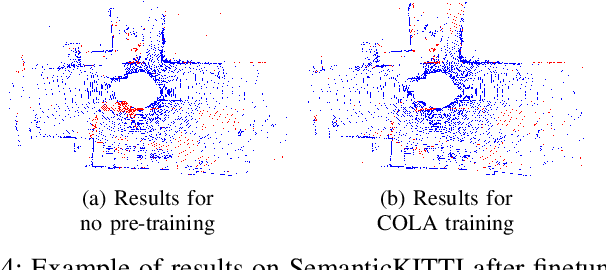
Transfer learning is a proven technique in 2D computer vision to leverage the large amount of data available and achieve high performance with datasets limited in size due to the cost of acquisition or annotation. In 3D, annotation is known to be a costly task; nevertheless, transfer learning methods have only recently been investigated. Unsupervised pre-training has been heavily favored as no very large annotated dataset are available. In this work, we tackle the case of real-time 3D semantic segmentation of sparse outdoor LiDAR scans. Such datasets have been on the rise, but with different label sets even for the same task. In this work, we propose here an intermediate-level label set called the coarse labels, which allows all the data available to be leveraged without any manual labelization. This way, we have access to a larger dataset, alongside a simpler task of semantic segmentation. With it, we introduce a new pre-training task: the coarse label pre-training, also called COLA. We thoroughly analyze the impact of COLA on various datasets and architectures and show that it yields a noticeable performance improvement, especially when the finetuning task has access only to a small dataset.
EXplainable Neural-Symbolic Learning (X-NeSyL) methodology to fuse deep learning representations with expert knowledge graphs: the MonuMAI cultural heritage use case
Apr 24, 2021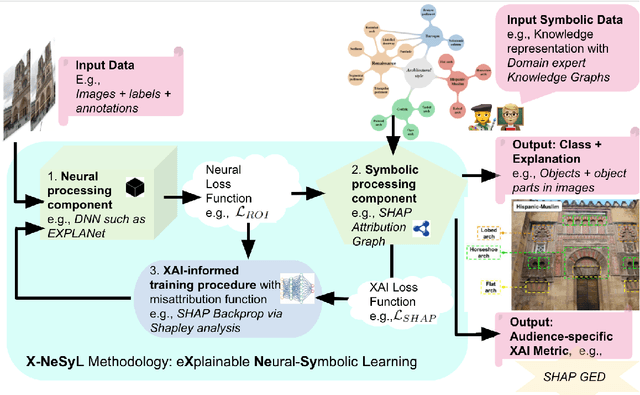
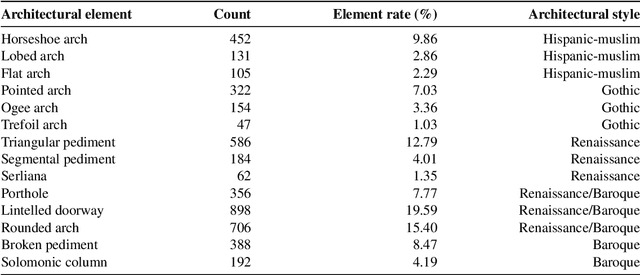


The latest Deep Learning (DL) models for detection and classification have achieved an unprecedented performance over classical machine learning algorithms. However, DL models are black-box methods hard to debug, interpret, and certify. DL alone cannot provide explanations that can be validated by a non technical audience. In contrast, symbolic AI systems that convert concepts into rules or symbols -- such as knowledge graphs -- are easier to explain. However, they present lower generalisation and scaling capabilities. A very important challenge is to fuse DL representations with expert knowledge. One way to address this challenge, as well as the performance-explainability trade-off is by leveraging the best of both streams without obviating domain expert knowledge. We tackle such problem by considering the symbolic knowledge is expressed in form of a domain expert knowledge graph. We present the eXplainable Neural-symbolic learning (X-NeSyL) methodology, designed to learn both symbolic and deep representations, together with an explainability metric to assess the level of alignment of machine and human expert explanations. The ultimate objective is to fuse DL representations with expert domain knowledge during the learning process to serve as a sound basis for explainability. X-NeSyL methodology involves the concrete use of two notions of explanation at inference and training time respectively: 1) EXPLANet: Expert-aligned eXplainable Part-based cLAssifier NETwork Architecture, a compositional CNN that makes use of symbolic representations, and 2) SHAP-Backprop, an explainable AI-informed training procedure that guides the DL process to align with such symbolic representations in form of knowledge graphs. We showcase X-NeSyL methodology using MonuMAI dataset for monument facade image classification, and demonstrate that our approach improves explainability and performance.