 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformance Checking of Fuzzy Logs against Declarative Temporal Specifications
Jun 17, 2024Traditional conformance checking tasks assume that event data provide a faithful and complete representation of the actual process executions. This assumption has been recently questioned: more and more often events are not traced explicitly, but are instead indirectly obtained as the result of event recognition pipelines, and thus inherently come with uncertainty. In this work, differently from the typical probabilistic interpretation of uncertainty, we consider the relevant case where uncertainty refers to which activity is actually conducted, under a fuzzy semantics. In this novel setting, we consider the problem of checking whether fuzzy event data conform with declarative temporal rules specified as Declare patterns or, more generally, as formulae of linear temporal logic over finite traces (LTLf). This requires to relax the assumption that at each instant only one activity is executed, and to correspondingly redefine boolean operators of the logic with a fuzzy semantics. Specifically, we provide a threefold contribution. First, we define a fuzzy counterpart of LTLf tailored to our purpose. Second, we cast conformance checking over fuzzy logs as a verification problem in this logic. Third, we provide a proof-of-concept, efficient implementation based on the PyTorch Python library, suited to check conformance of multiple fuzzy traces at once.
Guiding the generation of counterfactual explanations through temporal background knowledge for Predictive Process Monitoring
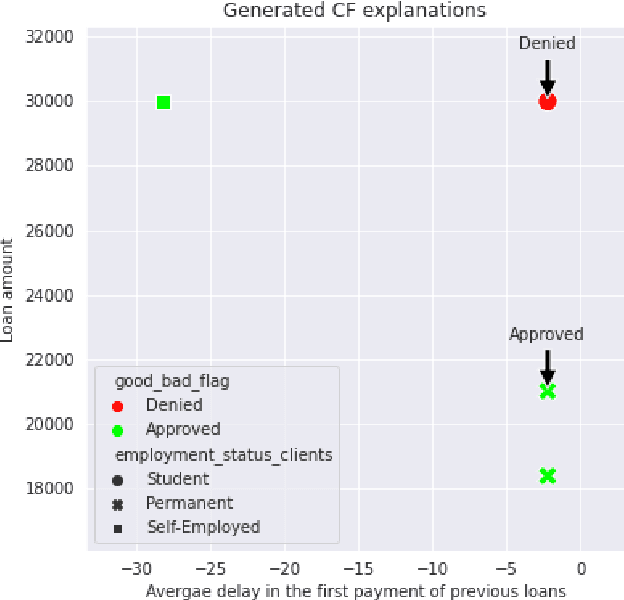
Mar 18, 2024Counterfactual explanations suggest what should be different in the input instance to change the outcome of an AI system. When dealing with counterfactual explanations in the field of Predictive Process Monitoring, however, control flow relationships among events have to be carefully considered. A counterfactual, indeed, should not violate control flow relationships among activities (temporal background knowledege). Within the field of Explainability in Predictive Process Monitoring, there have been a series of works regarding counterfactual explanations for outcome-based predictions. However, none of them consider the inclusion of temporal background knowledge when generating these counterfactuals. In this work, we adapt state-of-the-art techniques for counterfactual generation in the domain of XAI that are based on genetic algorithms to consider a series of temporal constraints at runtime. We assume that this temporal background knowledge is given, and we adapt the fitness function, as well as the crossover and mutation operators, to maintain the satisfaction of the constraints. The proposed methods are evaluated with respect to state-of-the-art genetic algorithms for counterfactual generation and the results are presented. We showcase that the inclusion of temporal background knowledge allows the generation of counterfactuals more conformant to the temporal background knowledge, without however losing in terms of the counterfactual traditional quality metrics.
Knowledge-Driven Modulation of Neural Networks with Attention Mechanism for Next Activity Prediction
Dec 14, 2023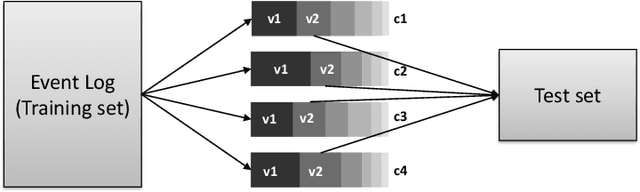
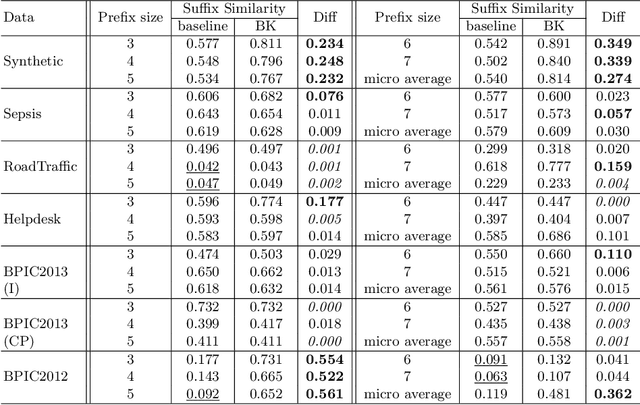
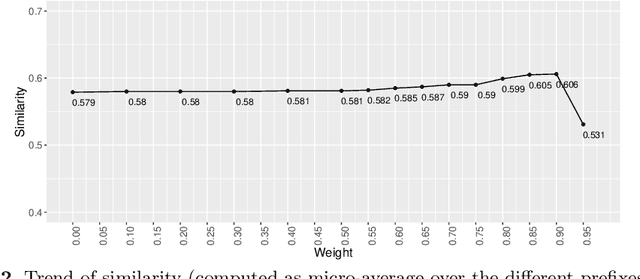
Predictive Process Monitoring (PPM) aims at leveraging historic process execution data to predict how ongoing executions will continue up to their completion. In recent years, PPM techniques for the prediction of the next activities have matured significantly, mainly thanks to the use of Neural Networks (NNs) as a predictor. While their performance is difficult to beat in the general case, there are specific situations where background process knowledge can be helpful. Such knowledge can be leveraged for improving the quality of predictions for exceptional process executions or when the process changes due to a concept drift. In this paper, we present a Symbolic[Neuro] system that leverages background knowledge expressed in terms of a procedural process model to offset the under-sampling in the training data. More specifically, we make predictions using NNs with attention mechanism, an emerging technology in the NN field. The system has been tested on several real-life logs showing an improvement in the performance of the prediction task.
Outcome-Oriented Prescriptive Process Monitoring Based on Temporal Logic Patterns
Nov 14, 2022



Prescriptive Process Monitoring systems recommend, during the execution of a business process, interventions that, if followed, prevent a negative outcome of the process. Such interventions have to be reliable, that is, they have to guarantee the achievement of the desired outcome or performance, and they have to be flexible, that is, they have to avoid overturning the normal process execution or forcing the execution of a given activity. Most of the existing Prescriptive Process Monitoring solutions, however, while performing well in terms of recommendation reliability, provide the users with very specific (sequences of) activities that have to be executed without caring about the feasibility of these recommendations. In order to face this issue, we propose a new Outcome-Oriented Prescriptive Process Monitoring system recommending temporal relations between activities that have to be guaranteed during the process execution in order to achieve a desired outcome. This softens the mandatory execution of an activity at a given point in time, thus leaving more freedom to the user in deciding the interventions to put in place. Our approach defines these temporal relations with Linear Temporal Logic over finite traces patterns that are used as features to describe the historical process data recorded in an event log by the information systems supporting the execution of the process. Such encoded log is used to train a Machine Learning classifier to learn a mapping between the temporal patterns and the outcome of a process execution. The classifier is then queried at runtime to return as recommendations the most salient temporal patterns to be satisfied to maximize the likelihood of a certain outcome for an input ongoing process execution. The proposed system is assessed using a pool of 22 real-life event logs that have already been used as a benchmark in the Process Mining community.
Machine Learning for Utility Prediction in Argument-Based Computational Persuasion
Dec 15, 2021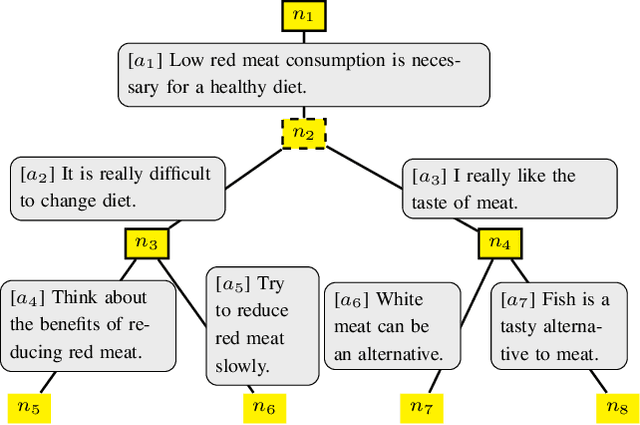
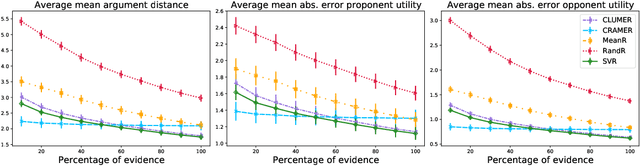
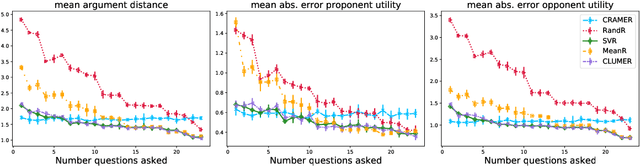
Automated persuasion systems (APS) aim to persuade a user to believe something by entering into a dialogue in which arguments and counterarguments are exchanged. To maximize the probability that an APS is successful in persuading a user, it can identify a global policy that will allow it to select the best arguments it presents at each stage of the dialogue whatever arguments the user presents. However, in real applications, such as for healthcare, it is unlikely the utility of the outcome of the dialogue will be the same, or the exact opposite, for the APS and user. In order to deal with this situation, games in extended form have been harnessed for argumentation in Bi-party Decision Theory. This opens new problems that we address in this paper: (1) How can we use Machine Learning (ML) methods to predict utility functions for different subpopulations of users? and (2) How can we identify for a new user the best utility function from amongst those that we have learned? To this extent, we develop two ML methods, EAI and EDS, that leverage information coming from the users to predict their utilities. EAI is restricted to a fixed amount of information, whereas EDS can choose the information that best detects the subpopulations of a user. We evaluate EAI and EDS in a simulation setting and in a realistic case study concerning healthy eating habits. Results are promising in both cases, but EDS is more effective at predicting useful utility functions.
A Practical Tutorial on Explainable AI Techniques
Nov 13, 2021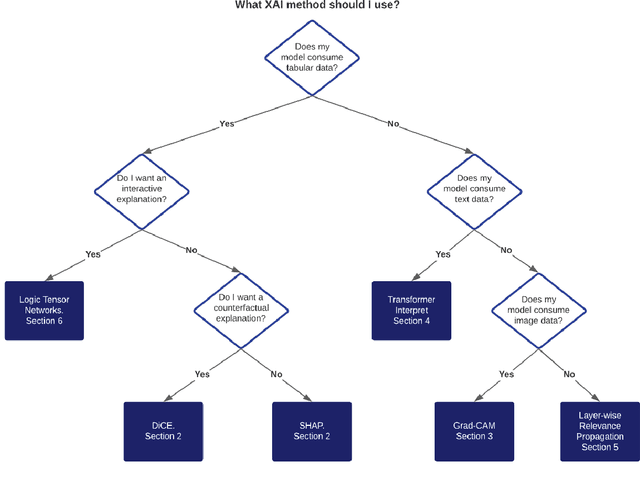
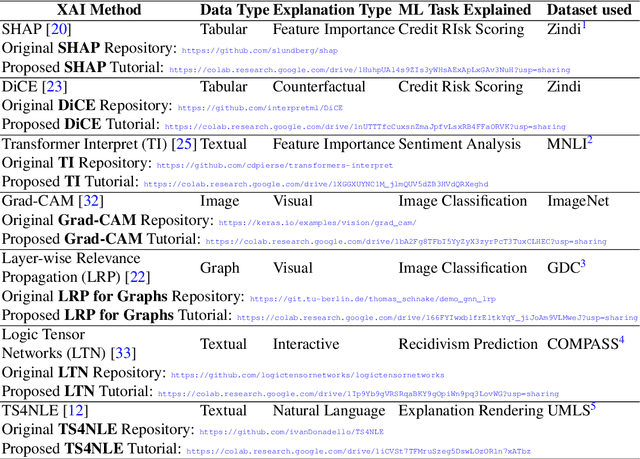
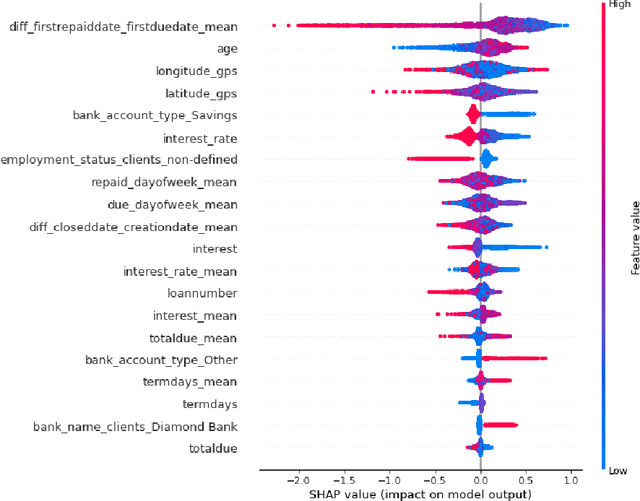
Last years have been characterized by an upsurge of opaque automatic decision support systems, such as Deep Neural Networks (DNNs). Although they have great generalization and prediction skills, their functioning does not allow obtaining detailed explanations of their behaviour. As opaque machine learning models are increasingly being employed to make important predictions in critical environments, the danger is to create and use decisions that are not justifiable or legitimate. Therefore, there is a general agreement on the importance of endowing machine learning models with explainability. The reason is that EXplainable Artificial Intelligence (XAI) techniques can serve to verify and certify model outputs and enhance them with desirable notions such as trustworthiness, accountability, transparency and fairness. This tutorial is meant to be the go-to handbook for any audience with a computer science background aiming at getting intuitive insights of machine learning models, accompanied with straight, fast, and intuitive explanations out of the box. We believe that these methods provide a valuable contribution for applying XAI techniques in their particular day-to-day models, datasets and use-cases. Figure \ref{fig:Flowchart} acts as a flowchart/map for the reader and should help him to find the ideal method to use according to his type of data. The reader will find a description of the proposed method as well as an example of use and a Python notebook that he can easily modify as he pleases in order to apply it to his own case of application.
EXplainable Neural-Symbolic Learning (X-NeSyL) methodology to fuse deep learning representations with expert knowledge graphs: the MonuMAI cultural heritage use case
Apr 24, 2021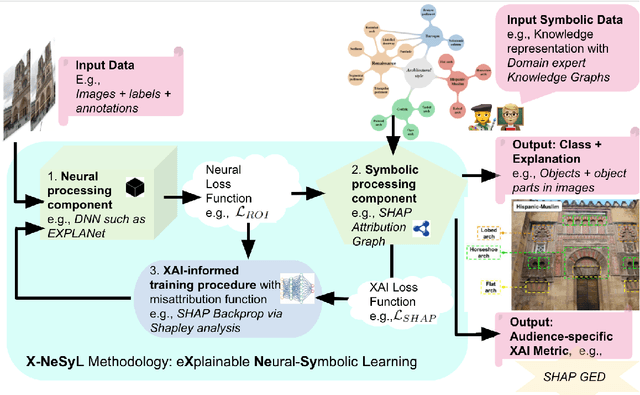
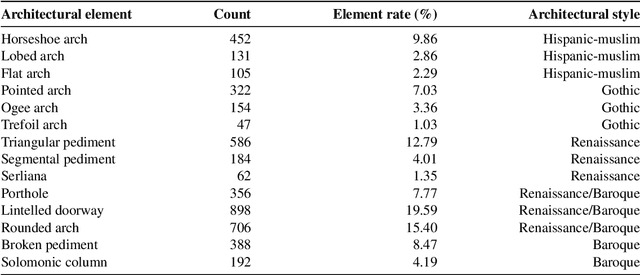


The latest Deep Learning (DL) models for detection and classification have achieved an unprecedented performance over classical machine learning algorithms. However, DL models are black-box methods hard to debug, interpret, and certify. DL alone cannot provide explanations that can be validated by a non technical audience. In contrast, symbolic AI systems that convert concepts into rules or symbols -- such as knowledge graphs -- are easier to explain. However, they present lower generalisation and scaling capabilities. A very important challenge is to fuse DL representations with expert knowledge. One way to address this challenge, as well as the performance-explainability trade-off is by leveraging the best of both streams without obviating domain expert knowledge. We tackle such problem by considering the symbolic knowledge is expressed in form of a domain expert knowledge graph. We present the eXplainable Neural-symbolic learning (X-NeSyL) methodology, designed to learn both symbolic and deep representations, together with an explainability metric to assess the level of alignment of machine and human expert explanations. The ultimate objective is to fuse DL representations with expert domain knowledge during the learning process to serve as a sound basis for explainability. X-NeSyL methodology involves the concrete use of two notions of explanation at inference and training time respectively: 1) EXPLANet: Expert-aligned eXplainable Part-based cLAssifier NETwork Architecture, a compositional CNN that makes use of symbolic representations, and 2) SHAP-Backprop, an explainable AI-informed training procedure that guides the DL process to align with such symbolic representations in form of knowledge graphs. We showcase X-NeSyL methodology using MonuMAI dataset for monument facade image classification, and demonstrate that our approach improves explainability and performance.
Compensating Supervision Incompleteness with Prior Knowledge in Semantic Image Interpretation
Oct 01, 2019

Semantic Image Interpretation is the task of extracting a structured semantic description from images. This requires the detection of visual relationships: triples (subject,relation,object) describing a semantic relation between a subject and an object. A pure supervised approach to visual relationship detection requires a complete and balanced training set for all the possible combinations of (subject, relation, object). However, such training sets are not available and would require a prohibitive human effort. This implies the ability of predicting triples which do not appear in the training set. This problem is called zero-shot learning. State-of-the-art approaches to zero-shot learning exploit similarities among relationships in the training set or external linguistic knowledge. In this paper, we perform zero-shot learning by using Logic Tensor Networks, a novel Statistical Relational Learning framework that exploits both the similarities with other seen relationships and background knowledge, expressed with logical constraints between subjects, relations and objects. The experiments on the Visual Relationship Dataset show that the use of logical constraints outperforms the current methods. This implies that background knowledge can be used to alleviate the incompleteness of training sets.
Logic Tensor Networks for Semantic Image Interpretation
May 24, 2017

Semantic Image Interpretation (SII) is the task of extracting structured semantic descriptions from images. It is widely agreed that the combined use of visual data and background knowledge is of great importance for SII. Recently, Statistical Relational Learning (SRL) approaches have been developed for reasoning under uncertainty and learning in the presence of data and rich knowledge. Logic Tensor Networks (LTNs) are an SRL framework which integrates neural networks with first-order fuzzy logic to allow (i) efficient learning from noisy data in the presence of logical constraints, and (ii) reasoning with logical formulas describing general properties of the data. In this paper, we develop and apply LTNs to two of the main tasks of SII, namely, the classification of an image's bounding boxes and the detection of the relevant part-of relations between objects. To the best of our knowledge, this is the first successful application of SRL to such SII tasks. The proposed approach is evaluated on a standard image processing benchmark. Experiments show that the use of background knowledge in the form of logical constraints can improve the performance of purely data-driven approaches, including the state-of-the-art Fast Region-based Convolutional Neural Networks (Fast R-CNN). Moreover, we show that the use of logical background knowledge adds robustness to the learning system when errors are present in the labels of the training data.