 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformance Checking of Fuzzy Logs against Declarative Temporal Specifications
Jun 17, 2024Traditional conformance checking tasks assume that event data provide a faithful and complete representation of the actual process executions. This assumption has been recently questioned: more and more often events are not traced explicitly, but are instead indirectly obtained as the result of event recognition pipelines, and thus inherently come with uncertainty. In this work, differently from the typical probabilistic interpretation of uncertainty, we consider the relevant case where uncertainty refers to which activity is actually conducted, under a fuzzy semantics. In this novel setting, we consider the problem of checking whether fuzzy event data conform with declarative temporal rules specified as Declare patterns or, more generally, as formulae of linear temporal logic over finite traces (LTLf). This requires to relax the assumption that at each instant only one activity is executed, and to correspondingly redefine boolean operators of the logic with a fuzzy semantics. Specifically, we provide a threefold contribution. First, we define a fuzzy counterpart of LTLf tailored to our purpose. Second, we cast conformance checking over fuzzy logs as a verification problem in this logic. Third, we provide a proof-of-concept, efficient implementation based on the PyTorch Python library, suited to check conformance of multiple fuzzy traces at once.
Guiding the generation of counterfactual explanations through temporal background knowledge for Predictive Process Monitoring
Mar 18, 2024Counterfactual explanations suggest what should be different in the input instance to change the outcome of an AI system. When dealing with counterfactual explanations in the field of Predictive Process Monitoring, however, control flow relationships among events have to be carefully considered. A counterfactual, indeed, should not violate control flow relationships among activities (temporal background knowledege). Within the field of Explainability in Predictive Process Monitoring, there have been a series of works regarding counterfactual explanations for outcome-based predictions. However, none of them consider the inclusion of temporal background knowledge when generating these counterfactuals. In this work, we adapt state-of-the-art techniques for counterfactual generation in the domain of XAI that are based on genetic algorithms to consider a series of temporal constraints at runtime. We assume that this temporal background knowledge is given, and we adapt the fitness function, as well as the crossover and mutation operators, to maintain the satisfaction of the constraints. The proposed methods are evaluated with respect to state-of-the-art genetic algorithms for counterfactual generation and the results are presented. We showcase that the inclusion of temporal background knowledge allows the generation of counterfactuals more conformant to the temporal background knowledge, without however losing in terms of the counterfactual traditional quality metrics.
Knowledge-Driven Modulation of Neural Networks with Attention Mechanism for Next Activity Prediction
Dec 14, 2023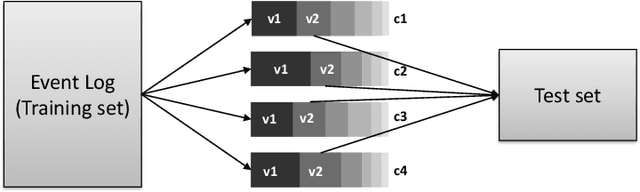
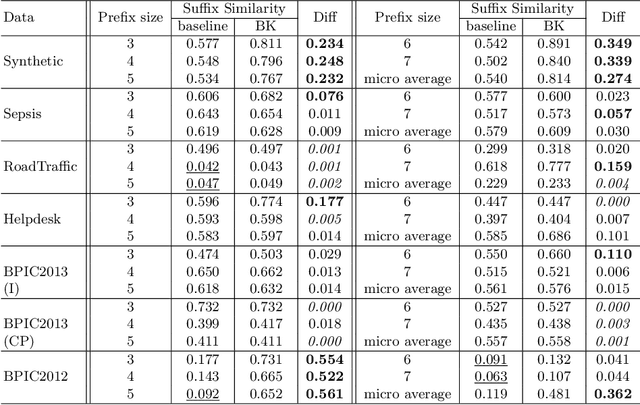
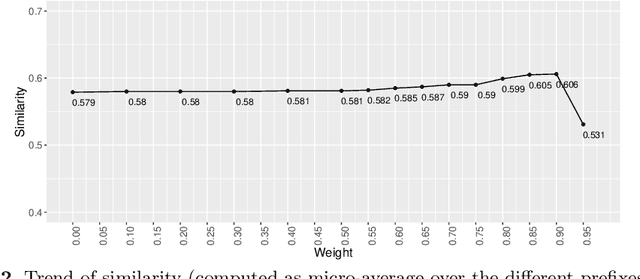
Predictive Process Monitoring (PPM) aims at leveraging historic process execution data to predict how ongoing executions will continue up to their completion. In recent years, PPM techniques for the prediction of the next activities have matured significantly, mainly thanks to the use of Neural Networks (NNs) as a predictor. While their performance is difficult to beat in the general case, there are specific situations where background process knowledge can be helpful. Such knowledge can be leveraged for improving the quality of predictions for exceptional process executions or when the process changes due to a concept drift. In this paper, we present a Symbolic[Neuro] system that leverages background knowledge expressed in terms of a procedural process model to offset the under-sampling in the training data. More specifically, we make predictions using NNs with attention mechanism, an emerging technology in the NN field. The system has been tested on several real-life logs showing an improvement in the performance of the prediction task.
Explain, Adapt and Retrain: How to improve the accuracy of a PPM classifier through different explanation styles
Mar 27, 2023


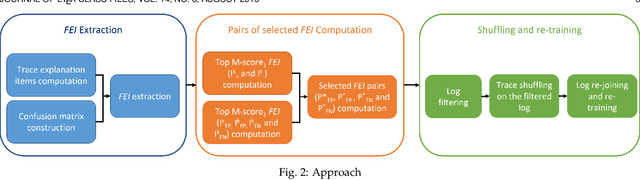
Recent papers have introduced a novel approach to explain why a Predictive Process Monitoring (PPM) model for outcome-oriented predictions provides wrong predictions. Moreover, they have shown how to exploit the explanations, obtained using state-of-the art post-hoc explainers, to identify the most common features that induce a predictor to make mistakes in a semi-automated way, and, in turn, to reduce the impact of those features and increase the accuracy of the predictive model. This work starts from the assumption that frequent control flow patterns in event logs may represent important features that characterize, and therefore explain, a certain prediction. Therefore, in this paper, we (i) employ a novel encoding able to leverage DECLARE constraints in Predictive Process Monitoring and compare the effectiveness of this encoding with Predictive Process Monitoring state-of-the art encodings, in particular for the task of outcome-oriented predictions; (ii) introduce a completely automated pipeline for the identification of the most common features inducing a predictor to make mistakes; and (iii) show the effectiveness of the proposed pipeline in increasing the accuracy of the predictive model by validating it on different real-life datasets.
Outcome-Oriented Prescriptive Process Monitoring Based on Temporal Logic Patterns
Nov 14, 2022



Prescriptive Process Monitoring systems recommend, during the execution of a business process, interventions that, if followed, prevent a negative outcome of the process. Such interventions have to be reliable, that is, they have to guarantee the achievement of the desired outcome or performance, and they have to be flexible, that is, they have to avoid overturning the normal process execution or forcing the execution of a given activity. Most of the existing Prescriptive Process Monitoring solutions, however, while performing well in terms of recommendation reliability, provide the users with very specific (sequences of) activities that have to be executed without caring about the feasibility of these recommendations. In order to face this issue, we propose a new Outcome-Oriented Prescriptive Process Monitoring system recommending temporal relations between activities that have to be guaranteed during the process execution in order to achieve a desired outcome. This softens the mandatory execution of an activity at a given point in time, thus leaving more freedom to the user in deciding the interventions to put in place. Our approach defines these temporal relations with Linear Temporal Logic over finite traces patterns that are used as features to describe the historical process data recorded in an event log by the information systems supporting the execution of the process. Such encoded log is used to train a Machine Learning classifier to learn a mapping between the temporal patterns and the outcome of a process execution. The classifier is then queried at runtime to return as recommendations the most salient temporal patterns to be satisfied to maximize the likelihood of a certain outcome for an input ongoing process execution. The proposed system is assessed using a pool of 22 real-life event logs that have already been used as a benchmark in the Process Mining community.
Nirdizati: an Advanced Predictive Process Monitoring Toolkit
Oct 18, 2022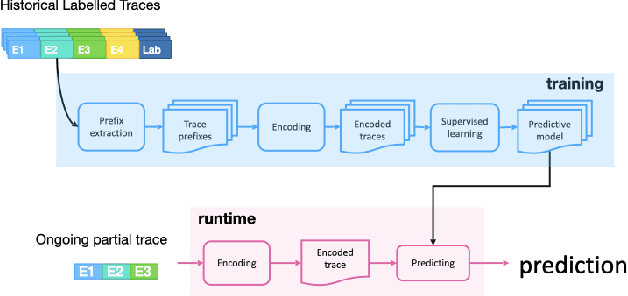

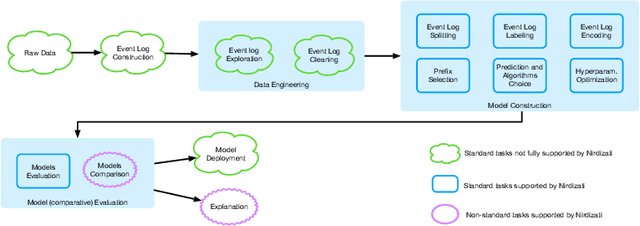
Predictive Process Monitoring is a field of Process Mining that aims at predicting how an ongoing execution of a business process will develop in the future using past process executions recorded in event logs. The recent stream of publications in this field shows the need for tools able to support researchers and users in analyzing, comparing and selecting the techniques that are the most suitable for them. Nirdizati is a dedicated tool for supporting users in building, comparing, analyzing, and explaining predictive models that can then be used to perform predictions on the future of an ongoing case. By providing a rich set of different state-of-the-art approaches, Nirdizati offers BPM researchers and practitioners a useful and flexible instrument for investigating and comparing Predictive Process Monitoring techniques. In this paper, we present the current version of Nirdizati, together with its architecture which has been developed to improve its modularity and scalability. The features of Nirdizati enrich its capability to support researchers and practitioners within the entire pipeline for constructing reliable Predictive Process Monitoring models.
ASP-Based Declarative Process Mining
May 04, 2022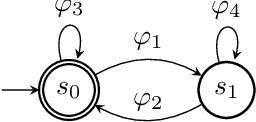
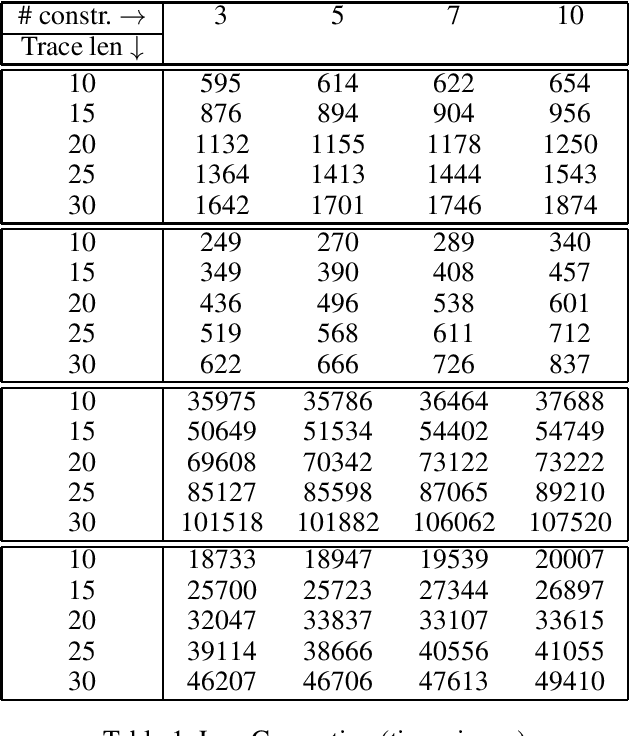
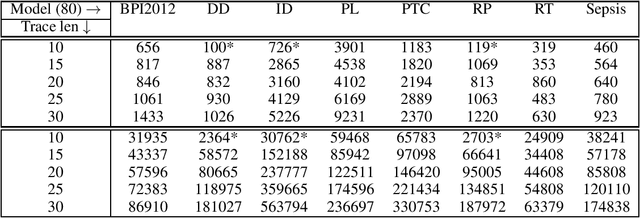
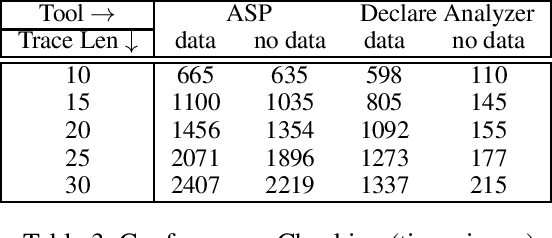
We put forward Answer Set Programming (ASP) as a solution approach for three classical problems in Declarative Process Mining: Log Generation, Query Checking, and Conformance Checking. These problems correspond to different ways of analyzing business processes under execution, starting from sequences of recorded events, a.k.a. event logs. We tackle them in their data-aware variant, i.e., by considering events that carry a payload (set of attribute-value pairs), in addition to the performed activity, specifying processes declaratively with an extension of linear-time temporal logic over finite traces (LTLf). The data-aware setting is significantly more challenging than the control-flow one: Query Checking is still open, while the existing approaches for the other two problems do not scale well. The contributions of the work include an ASP encoding schema for the three problems, their solution, and experiments showing the feasibility of the approach.
Explainable Predictive Process Monitoring: A User Evaluation
Feb 15, 2022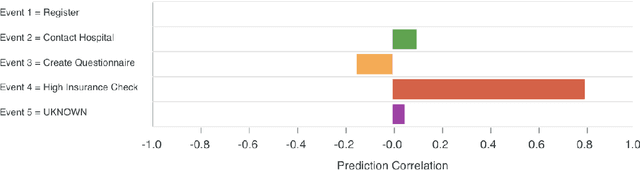
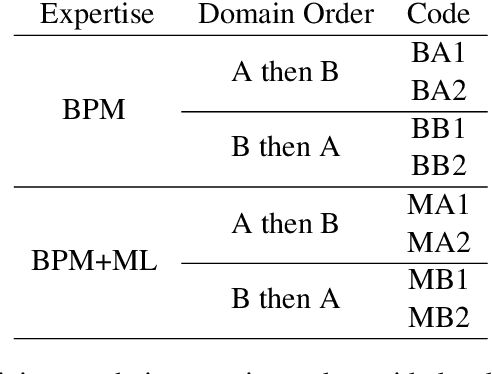
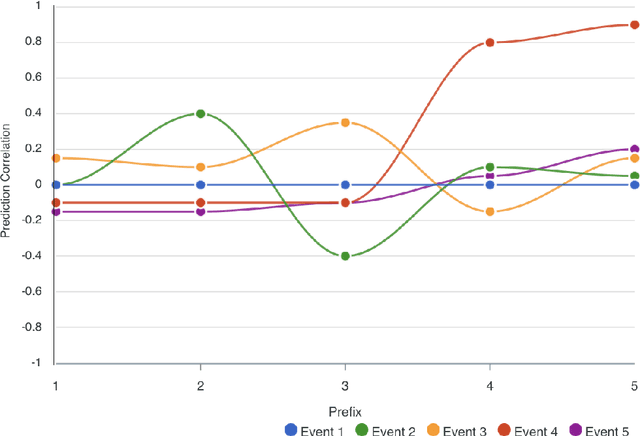
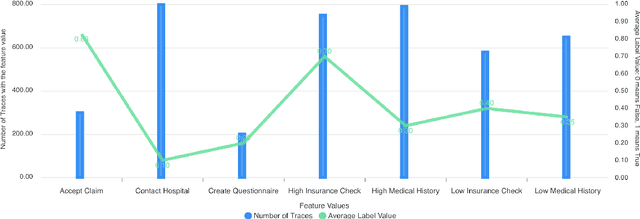
Explainability is motivated by the lack of transparency of black-box Machine Learning approaches, which do not foster trust and acceptance of Machine Learning algorithms. This also happens in the Predictive Process Monitoring field, where predictions, obtained by applying Machine Learning techniques, need to be explained to users, so as to gain their trust and acceptance. In this work, we carry on a user evaluation on explanation approaches for Predictive Process Monitoring aiming at investigating whether and how the explanations provided (i) are understandable; (ii) are useful in decision making tasks;(iii) can be further improved for process analysts, with different Machine Learning expertise levels. The results of the user evaluation show that, although explanation plots are overall understandable and useful for decision making tasks for Business Process Management users -- with and without experience in Machine Learning -- differences exist in the comprehension and usage of different plots, as well as in the way users with different Machine Learning expertise understand and use them.
Monitoring Hybrid Process Specifications with Conflict Management: The Automata-theoretic Approach
Nov 25, 2021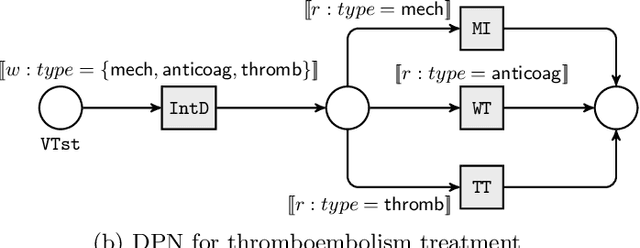
Business process monitoring approaches have thus far mainly focused on monitoring the execution of a process with respect to a single process model. However, in some cases it is necessary to consider multiple process specifications simultaneously. In addition, these specifications can be procedural, declarative, or a combination of both. For example, in the medical domain, a clinical guideline describing the treatment of a specific disease cannot account for all possible co-factors that can coexist for a specific patient and therefore additional constraints may need to be considered. In some cases, these constraints may be incompatible with clinical guidelines, therefore requiring the violation of either the guidelines or the constraints. In this paper, we propose a solution for monitoring the interplay of hybrid process specifications expressed as a combination of (data-aware) Petri nets and temporal logic rules. During the process execution, if these specifications are in conflict with each other, it is possible to violate some of them. The monitoring system is equipped with a violation cost model according to which the system can recommend the next course of actions in a way that would either avoid possible violations or minimize the total cost of violations.
Exploring Business Process Deviance with Sequential and Declarative Patterns
Nov 24, 2021
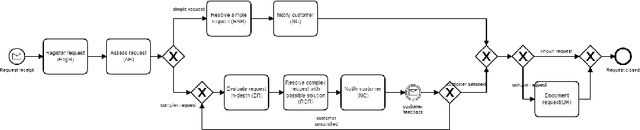

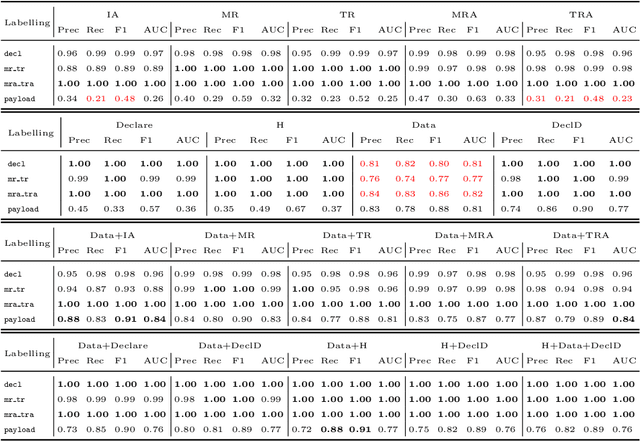
Business process deviance refers to the phenomenon whereby a subset of the executions of a business process deviate, in a negative or positive way, with respect to {their} expected or desirable outcomes. Deviant executions of a business process include those that violate compliance rules, or executions that undershoot or exceed performance targets. Deviance mining is concerned with uncovering the reasons for deviant executions by analyzing event logs stored by the systems supporting the execution of a business process. In this paper, the problem of explaining deviations in business processes is first investigated by using features based on sequential and declarative patterns, and a combination of them. Then, the explanations are further improved by leveraging the data attributes of events and traces in event logs through features based on pure data attribute values and data-aware declarative rules. The explanations characterizing the deviances are then extracted by direct and indirect methods for rule induction. Using real-life logs from multiple domains, a range of feature types and different forms of decision rules are evaluated in terms of their ability to accurately discriminate between non-deviant and deviant executions of a process as well as in terms of understandability of the final outcome returned to the users.