 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidening the Role of Group Recommender Systems with CAJO
Apr 08, 2025Group Recommender Systems (GRSs) have been studied and developed for more than twenty years. However, their application and usage has not grown. They can even be labeled as failures, if compared to the very successful and common recommender systems (RSs) used on all the major ecommerce and social platforms. As a result, the RSs that we all use now, are only targeted for individual users, aiming at choosing an item exclusively for themselves; no choice support is provided to groups trying to select a service, a product, an experience, a person, serving equally well all the group members. In this opinion article we discuss why the success of group recommender systems is lagging and we propose a research program unfolding on the analysis and development of new forms of collaboration between humans and intelligent systems. We define a set of roles, named CAJO, that GRSs should play in order to become more useful tools for group decision making.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Multi-modal Generative Models in Recommendation System
Sep 17, 2024



Many recommendation systems limit user inputs to text strings or behavior signals such as clicks and purchases, and system outputs to a list of products sorted by relevance. With the advent of generative AI, users have come to expect richer levels of interactions. In visual search, for example, a user may provide a picture of their desired product along with a natural language modification of the content of the picture (e.g., a dress like the one shown in the picture but in red color). Moreover, users may want to better understand the recommendations they receive by visualizing how the product fits their use case, e.g., with a representation of how a garment might look on them, or how a furniture item might look in their room. Such advanced levels of interaction require recommendation systems that are able to discover both shared and complementary information about the product across modalities, and visualize the product in a realistic and informative way. However, existing systems often treat multiple modalities independently: text search is usually done by comparing the user query to product titles and descriptions, while visual search is typically done by comparing an image provided by the customer to product images. We argue that future recommendation systems will benefit from a multi-modal understanding of the products that leverages the rich information retailers have about both customers and products to come up with the best recommendations. In this chapter we review recommendation systems that use multiple data modalities simultaneously.
Large Language Model Driven Recommendation
Aug 20, 2024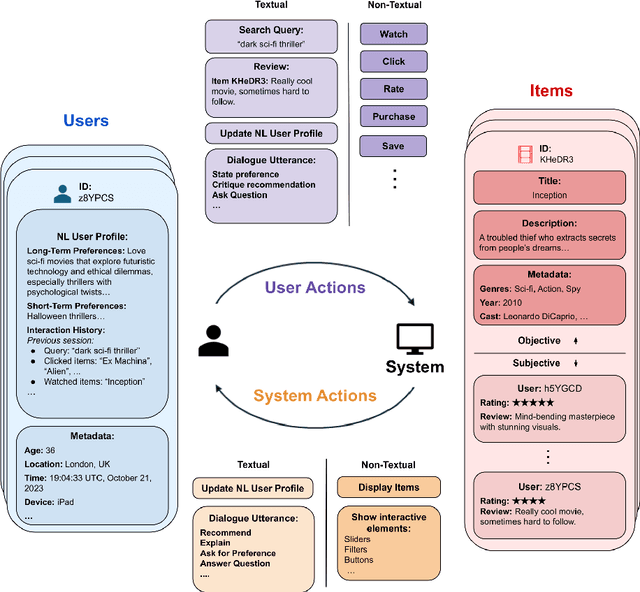
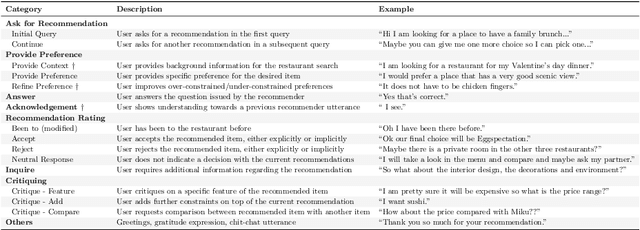
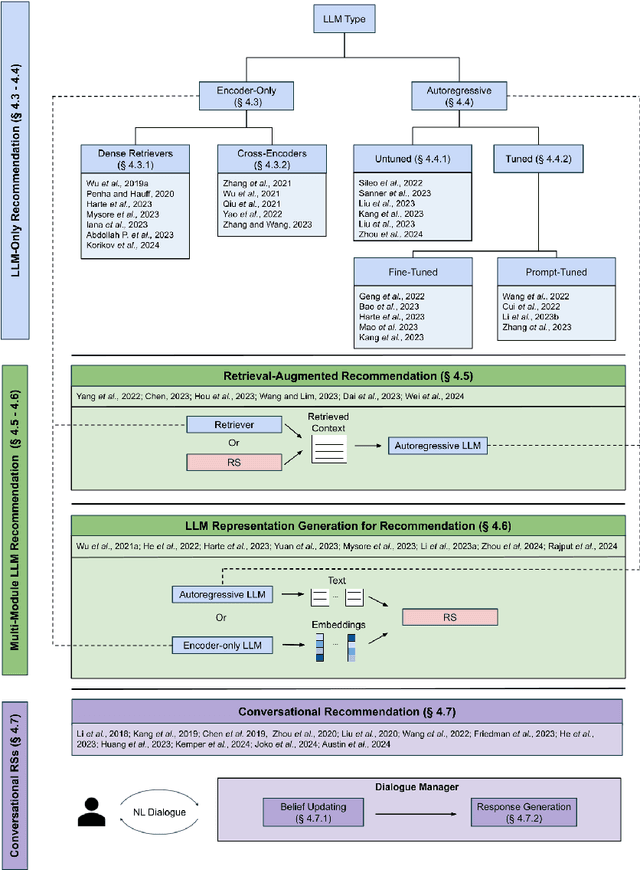

While previous chapters focused on recommendation systems (RSs) based on standardized, non-verbal user feedback such as purchases, views, and clicks -- the advent of LLMs has unlocked the use of natural language (NL) interactions for recommendation. This chapter discusses how LLMs' abilities for general NL reasoning present novel opportunities to build highly personalized RSs -- which can effectively connect nuanced and diverse user preferences to items, potentially via interactive dialogues. To begin this discussion, we first present a taxonomy of the key data sources for language-driven recommendation, covering item descriptions, user-system interactions, and user profiles. We then proceed to fundamental techniques for LLM recommendation, reviewing the use of encoder-only and autoregressive LLM recommendation in both tuned and untuned settings. Afterwards, we move to multi-module recommendation architectures in which LLMs interact with components such as retrievers and RSs in multi-stage pipelines. This brings us to architectures for conversational recommender systems (CRSs), in which LLMs facilitate multi-turn dialogues where each turn presents an opportunity not only to make recommendations, but also to engage with the user in interactive preference elicitation, critiquing, and question-answering.
Predicting Group Choices from Group Profiles
Aug 06, 2023



Group recommender systems (GRS) identify items to recommend to a group by aggregating group members' individual preferences into a group profile. The preference aggregation strategy used to build the group profile can also be used for predicting the item that a group may decide to choose, i.e., by assuming that the group is applying exactly that strategy. However, predicting the choice of a group is challenging since the RS is not aware of the precise preference aggregation strategy that is going to be used by the group. Hence, the aim of this paper is to validate the research hypothesis that, by using a machine learning approach and a data set of observed group choices, it is possible to predict a group's final choice, better than by using a standard preference aggregation strategy. Inspired by Social Decision Scheme theory, which first tried to address the group choice prediction problem, we search for a group profile definition that, in conjunction with a machine learning model, can be used to accurately predict a group choice. Moreover, to cope with the data scarcity problem, we propose two data augmentation methods, which add synthetic group profiles to the training data, and we hypothesise they can further improve the choice prediction accuracy. We validate our research hypotheses by using a data set containing 282 participants organized in 79 groups. The experiments indicate that the proposed methods outperform baseline aggregation strategies when used for group choice prediction. The proposed method is robust with the presence of missing preference data and achieves a performance superior to what human can achieve on the group choice prediction task. Finally, the proposed data augmentation method can also improve the prediction accuracy. Our approach can be exploited in novel GRSs to identify the items that the group is likely to choose and help the group to make a better choice.
Outcome-Oriented Prescriptive Process Monitoring Based on Temporal Logic Patterns
Nov 14, 2022



Prescriptive Process Monitoring systems recommend, during the execution of a business process, interventions that, if followed, prevent a negative outcome of the process. Such interventions have to be reliable, that is, they have to guarantee the achievement of the desired outcome or performance, and they have to be flexible, that is, they have to avoid overturning the normal process execution or forcing the execution of a given activity. Most of the existing Prescriptive Process Monitoring solutions, however, while performing well in terms of recommendation reliability, provide the users with very specific (sequences of) activities that have to be executed without caring about the feasibility of these recommendations. In order to face this issue, we propose a new Outcome-Oriented Prescriptive Process Monitoring system recommending temporal relations between activities that have to be guaranteed during the process execution in order to achieve a desired outcome. This softens the mandatory execution of an activity at a given point in time, thus leaving more freedom to the user in deciding the interventions to put in place. Our approach defines these temporal relations with Linear Temporal Logic over finite traces patterns that are used as features to describe the historical process data recorded in an event log by the information systems supporting the execution of the process. Such encoded log is used to train a Machine Learning classifier to learn a mapping between the temporal patterns and the outcome of a process execution. The classifier is then queried at runtime to return as recommendations the most salient temporal patterns to be satisfied to maximize the likelihood of a certain outcome for an input ongoing process execution. The proposed system is assessed using a pool of 22 real-life event logs that have already been used as a benchmark in the Process Mining community.
Trustworthy Recommender Systems
Aug 10, 2022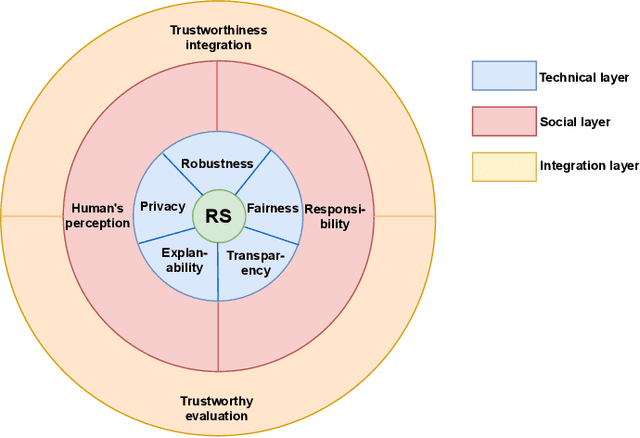
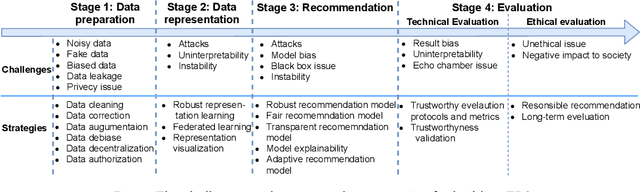
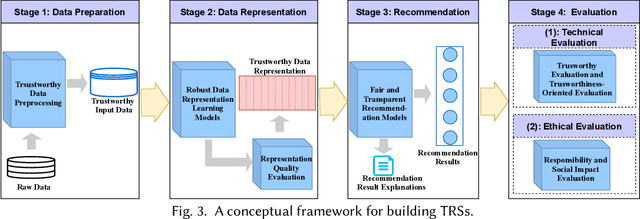
Recommender systems (RSs) aim to help users to effectively retrieve items of their interests from a large catalogue. For a quite long period of time, researchers and practitioners have been focusing on developing accurate RSs. Recent years have witnessed an increasing number of threats to RSs, coming from attacks, system and user generated noise, system bias. As a result, it has become clear that a strict focus on RS accuracy is limited and the research must consider other important factors, e.g., trustworthiness. For end users, a trustworthy RS (TRS) should not only be accurate, but also transparent, unbiased and fair as well as robust to noise or attacks. These observations actually led to a paradigm shift of the research on RSs: from accuracy-oriented RSs to TRSs. However, researchers lack a systematic overview and discussion of the literature in this novel and fast developing field of TRSs. To this end, in this paper, we provide an overview of TRSs, including a discussion of the motivation and basic concepts of TRSs, a presentation of the challenges in building TRSs, and a perspective on the future directions in this area. We also provide a novel conceptual framework to support the construction of TRSs.
Learning to act: a Reinforcement Learning approach to recommend the best next activities
Mar 29, 2022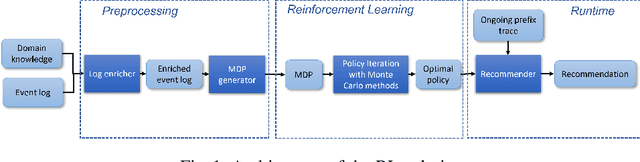

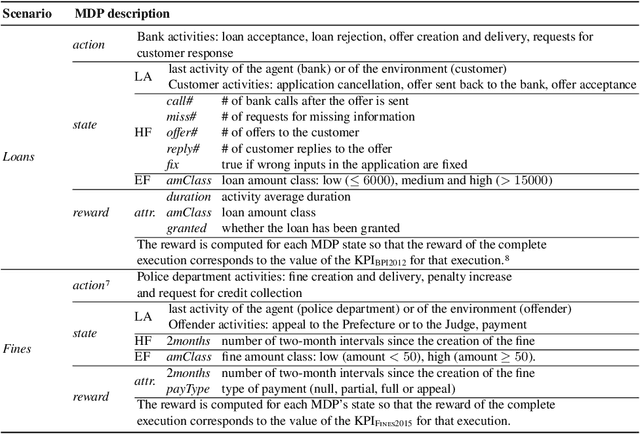
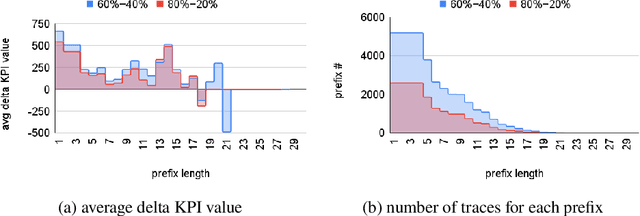
The rise of process data availability has led in the last decade to the development of several data-driven learning approaches. However, most of these approaches limit themselves to use the learned model to predict the future of ongoing process executions. The goal of this paper is moving a step forward and leveraging data with the purpose of learning to act by supporting users with recommendations for the best strategy to follow, in order to optimize a measure of performance. In this paper, we take the (optimization) perspective of one process actor and we recommend the best activities to execute next, in response to what happens in a complex external environment, where there is no control on exogenous factors. To this aim, we investigate an approach that learns, by means of Reinforcement Learning, an optimal policy from the observation of past executions and recommends the best activities to carry on for optimizing a Key Performance Indicator of interest. The potentiality of the approach has been demonstrated on two scenarios taken from real-life data.
Graph Learning based Recommender Systems: A Review
May 13, 2021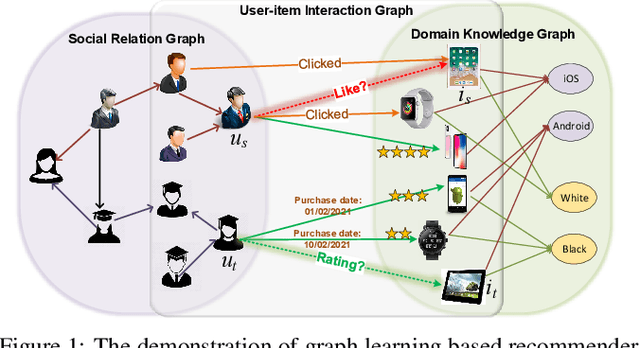

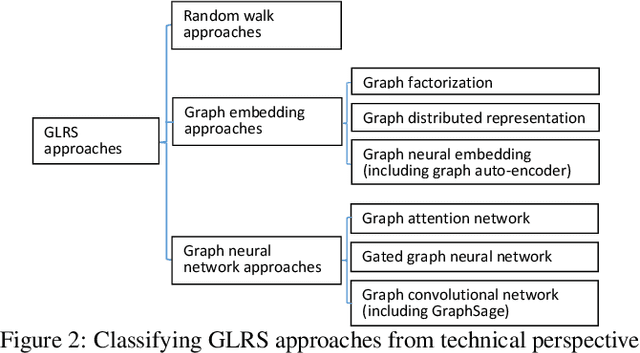
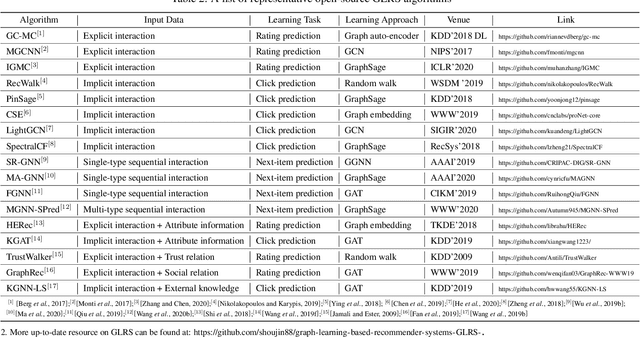
Recent years have witnessed the fast development of the emerging topic of Graph Learning based Recommender Systems (GLRS). GLRS employ advanced graph learning approaches to model users' preferences and intentions as well as items' characteristics for recommendations. Differently from other RS approaches, including content-based filtering and collaborative filtering, GLRS are built on graphs where the important objects, e.g., users, items, and attributes, are either explicitly or implicitly connected. With the rapid development of graph learning techniques, exploring and exploiting homogeneous or heterogeneous relations in graphs are a promising direction for building more effective RS. In this paper, we provide a systematic review of GLRS, by discussing how they extract important knowledge from graph-based representations to improve the accuracy, reliability and explainability of the recommendations. First, we characterize and formalize GLRS, and then summarize and categorize the key challenges and main progress in this novel research area. Finally, we share some new research directions in this vibrant area.