 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Group Choices from Group Profiles
Aug 06, 2023



Group recommender systems (GRS) identify items to recommend to a group by aggregating group members' individual preferences into a group profile. The preference aggregation strategy used to build the group profile can also be used for predicting the item that a group may decide to choose, i.e., by assuming that the group is applying exactly that strategy. However, predicting the choice of a group is challenging since the RS is not aware of the precise preference aggregation strategy that is going to be used by the group. Hence, the aim of this paper is to validate the research hypothesis that, by using a machine learning approach and a data set of observed group choices, it is possible to predict a group's final choice, better than by using a standard preference aggregation strategy. Inspired by Social Decision Scheme theory, which first tried to address the group choice prediction problem, we search for a group profile definition that, in conjunction with a machine learning model, can be used to accurately predict a group choice. Moreover, to cope with the data scarcity problem, we propose two data augmentation methods, which add synthetic group profiles to the training data, and we hypothesise they can further improve the choice prediction accuracy. We validate our research hypotheses by using a data set containing 282 participants organized in 79 groups. The experiments indicate that the proposed methods outperform baseline aggregation strategies when used for group choice prediction. The proposed method is robust with the presence of missing preference data and achieves a performance superior to what human can achieve on the group choice prediction task. Finally, the proposed data augmentation method can also improve the prediction accuracy. Our approach can be exploited in novel GRSs to identify the items that the group is likely to choose and help the group to make a better choice.
Presenting a Dataset for Collaborator Recommending Systems in Academic Social Network: a Case Study on ReseachGate
Jan 06, 2021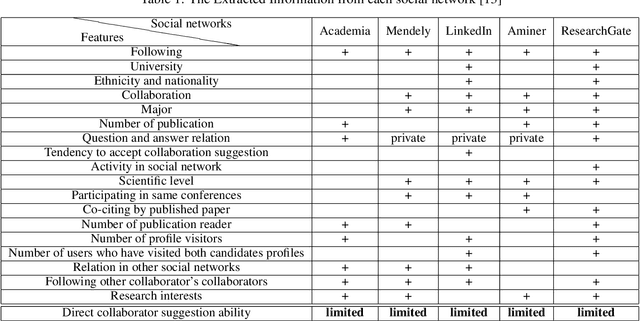
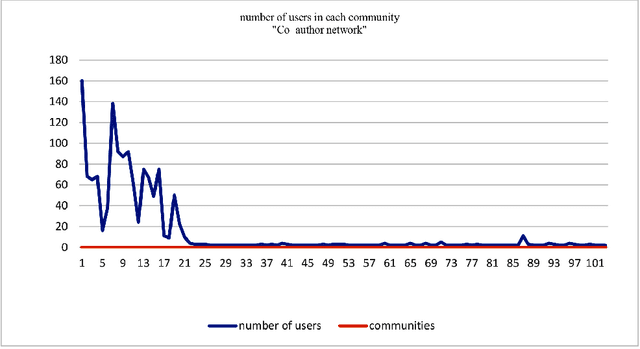
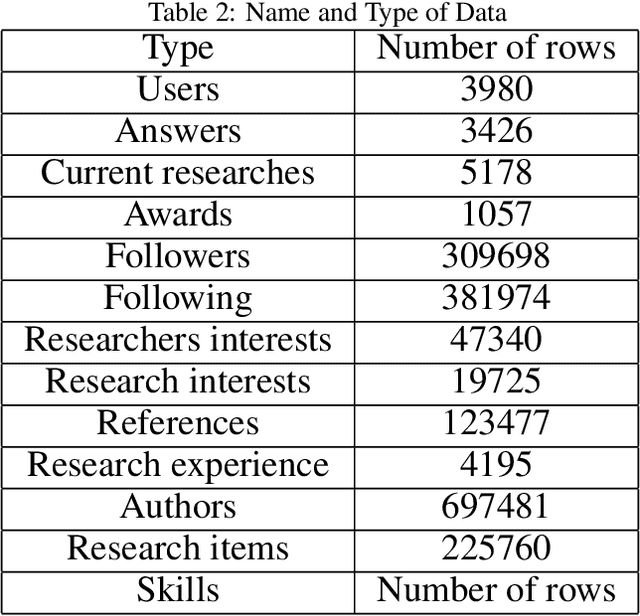
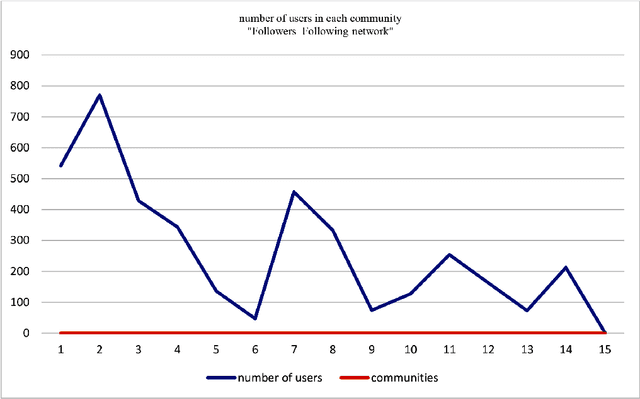
Collaborator finding systems are a special type of expert finding models. There is a long-lasting challenge for research in the collaborator recommending research area, which is the lack of a structured dataset to be used by the researchers. We introduce two datasets to fill this gap. The first dataset is prepared for designing a consistent, collaborator finding system. The next one, called a co-author finding model, models an academic social network as a table that contains different relations between the pair of users. Both of them provide an opportunity for introducing potential collaborators to each other. These two models have been extracted from ResearchGate (RG) data set and are available publicly. RG dataset has been collected from Jan. 2019 to April 2019 and includes raw data of 3980 RG users. The dataset consists of almost complete information about users. In the preprocessing phase, the well-known Elmo was used for analyzing textual data. We call this as \textbf{R}esearch\textbf{G}ate dataset for \textbf{R}commending \textbf{S}ystems (\textbf{RGRS}). For assessing the validity of data, we analyze each layer of data separately, and the results are reported. After preparing data and evaluating the collaborator finding models, we have done some assessments on \textbf{RGRS}. Some of these assessments are co-author, following-follower, and question answering relations. The outcomes indicate that it is the best relation in propagating knowledge in the network. To the best of our knowledge, there is no processed and analyzed dataset with this size.