 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Generative Models in Recommendation System
Sep 17, 2024



Many recommendation systems limit user inputs to text strings or behavior signals such as clicks and purchases, and system outputs to a list of products sorted by relevance. With the advent of generative AI, users have come to expect richer levels of interactions. In visual search, for example, a user may provide a picture of their desired product along with a natural language modification of the content of the picture (e.g., a dress like the one shown in the picture but in red color). Moreover, users may want to better understand the recommendations they receive by visualizing how the product fits their use case, e.g., with a representation of how a garment might look on them, or how a furniture item might look in their room. Such advanced levels of interaction require recommendation systems that are able to discover both shared and complementary information about the product across modalities, and visualize the product in a realistic and informative way. However, existing systems often treat multiple modalities independently: text search is usually done by comparing the user query to product titles and descriptions, while visual search is typically done by comparing an image provided by the customer to product images. We argue that future recommendation systems will benefit from a multi-modal understanding of the products that leverages the rich information retailers have about both customers and products to come up with the best recommendations. In this chapter we review recommendation systems that use multiple data modalities simultaneously.
Large Language Model Driven Recommendation
Aug 20, 2024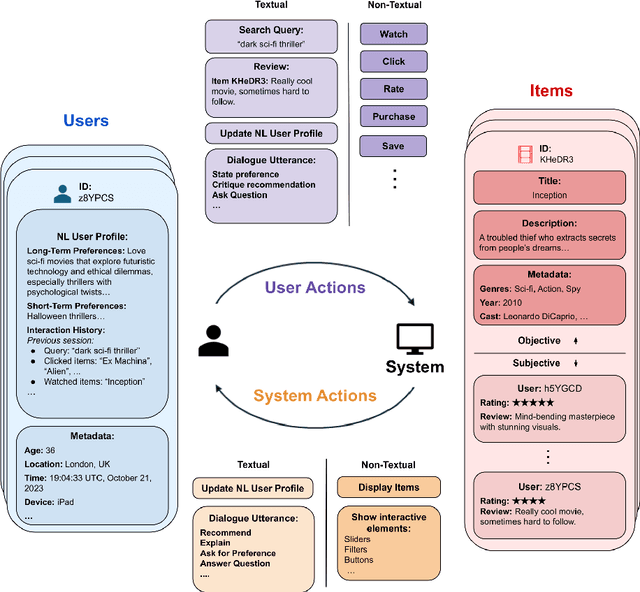
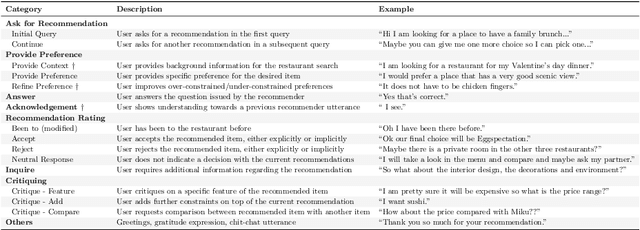
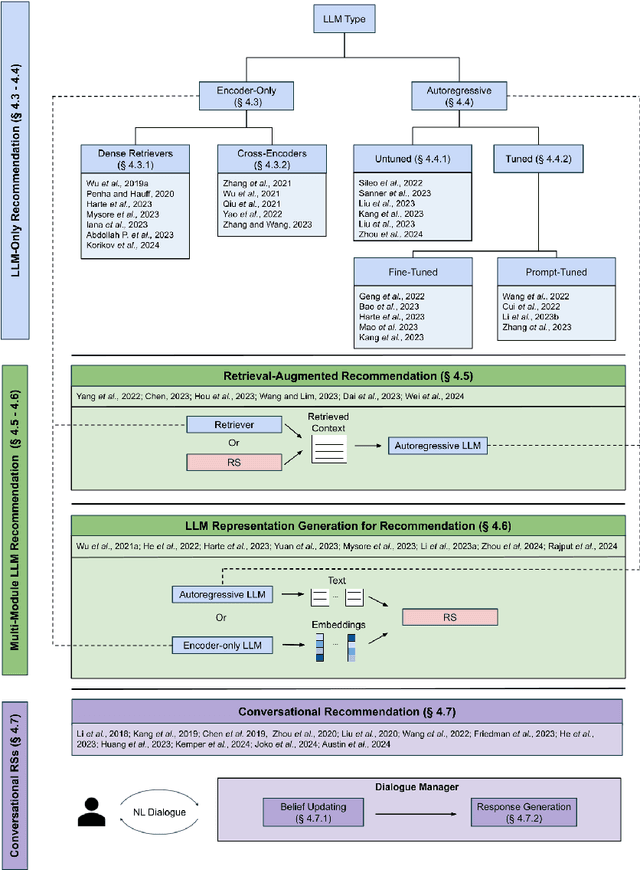

While previous chapters focused on recommendation systems (RSs) based on standardized, non-verbal user feedback such as purchases, views, and clicks -- the advent of LLMs has unlocked the use of natural language (NL) interactions for recommendation. This chapter discusses how LLMs' abilities for general NL reasoning present novel opportunities to build highly personalized RSs -- which can effectively connect nuanced and diverse user preferences to items, potentially via interactive dialogues. To begin this discussion, we first present a taxonomy of the key data sources for language-driven recommendation, covering item descriptions, user-system interactions, and user profiles. We then proceed to fundamental techniques for LLM recommendation, reviewing the use of encoder-only and autoregressive LLM recommendation in both tuned and untuned settings. Afterwards, we move to multi-module recommendation architectures in which LLMs interact with components such as retrievers and RSs in multi-stage pipelines. This brings us to architectures for conversational recommender systems (CRSs), in which LLMs facilitate multi-turn dialogues where each turn presents an opportunity not only to make recommendations, but also to engage with the user in interactive preference elicitation, critiquing, and question-answering.
A Review of Modern Recommender Systems Using Generative Models
Mar 31, 2024

Traditional recommender systems (RS) have used user-item rating histories as their primary data source, with collaborative filtering being one of the principal methods. However, generative models have recently developed abilities to model and sample from complex data distributions, including not only user-item interaction histories but also text, images, and videos - unlocking this rich data for novel recommendation tasks. Through this comprehensive and multi-disciplinary survey, we aim to connect the key advancements in RS using Generative Models (Gen-RecSys), encompassing: a foundational overview of interaction-driven generative models; the application of large language models (LLM) for generative recommendation, retrieval, and conversational recommendation; and the integration of multimodal models for processing and generating image and video content in RS. Our holistic perspective allows us to highlight necessary paradigms for evaluating the impact and harm of Gen-RecSys and identify open challenges. A more up-to-date version of the papers is maintained at: https://github.com/yasdel/LLM-RecSys.
On Utilizing Relationships for Transferable Few-Shot Fine-Grained Object Detection
Dec 01, 2022
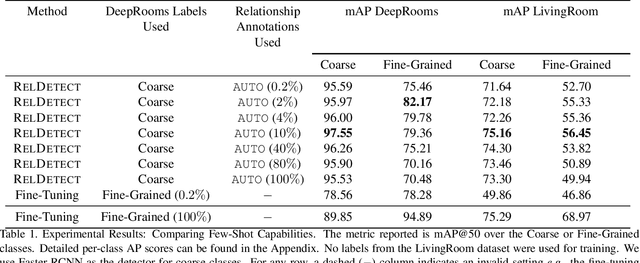
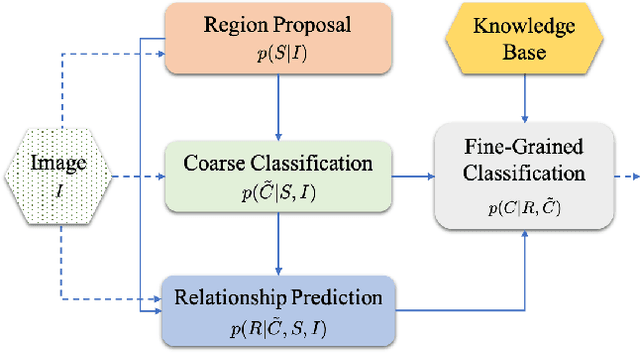
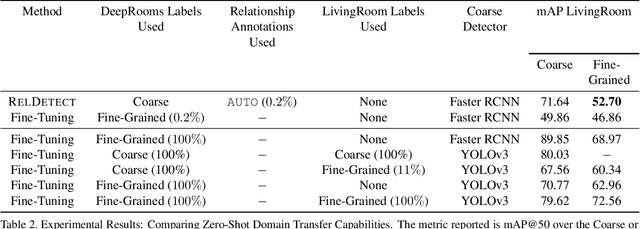
State-of-the-art object detectors are fast and accurate, but they require a large amount of well annotated training data to obtain good performance. However, obtaining a large amount of training annotations specific to a particular task, i.e., fine-grained annotations, is costly in practice. In contrast, obtaining common-sense relationships from text, e.g., "a table-lamp is a lamp that sits on top of a table", is much easier. Additionally, common-sense relationships like "on-top-of" are easy to annotate in a task-agnostic fashion. In this paper, we propose a probabilistic model that uses such relational knowledge to transform an off-the-shelf detector of coarse object categories (e.g., "table", "lamp") into a detector of fine-grained categories (e.g., "table-lamp"). We demonstrate that our method, RelDetect, achieves performance competitive to finetuning based state-of-the-art object detector baselines when an extremely low amount of fine-grained annotations is available ($0.2\%$ of entire dataset). We also demonstrate that RelDetect is able to utilize the inherent transferability of relationship information to obtain a better performance ($+5$ mAP points) than the above baselines on an unseen dataset (zero-shot transfer). In summary, we demonstrate the power of using relationships for object detection on datasets where fine-grained object categories can be linked to coarse-grained categories via suitable relationships.
A Review of Modern Fashion Recommender Systems
Feb 06, 2022


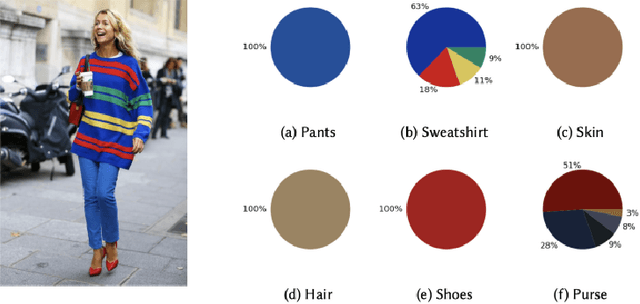
The textile and apparel industries have grown tremendously over the last years. Customers no longer have to visit many stores, stand in long queues, or try on garments in dressing rooms as millions of products are now available in online catalogs. However, given the plethora of options available, an effective recommendation system is necessary to properly sort, order, and communicate relevant product material or information to users. Effective fashion RS can have a noticeable impact on billions of customers' shopping experiences and increase sales and revenues on the provider-side. The goal of this survey is to provide a review of recommender systems that operate in the specific vertical domain of garment and fashion products. We have identified the most pressing challenges in fashion RS research and created a taxonomy that categorizes the literature according to the objective they are trying to accomplish (e.g., item or outfit recommendation, size recommendation, explainability, among others) and type of side-information (users, items, context). We have also identified the most important evaluation goals and perspectives (outfit generation, outfit recommendation, pairing recommendation, and fill-in-the-blank outfit compatibility prediction) and the most commonly used datasets and evaluation metrics.
Main Product Detection with Graph Networks for Fashion
Jan 25, 2022Computer vision has established a foothold in the online fashion retail industry. Main product detection is a crucial step of vision-based fashion product feed parsing pipelines, focused in identifying the bounding boxes that contain the product being sold in the gallery of images of the product page. The current state-of-the-art approach does not leverage the relations between regions in the image, and treats images of the same product independently, therefore not fully exploiting visual and product contextual information. In this paper we propose a model that incorporates Graph Convolutional Networks (GCN) that jointly represent all detected bounding boxes in the gallery as nodes. We show that the proposed method is better than the state-of-the-art, especially, when we consider the scenario where title-input is missing at inference time and for cross-dataset evaluation, our method outperforms previous approaches by a large margin.
T-VSE: Transformer-Based Visual Semantic Embedding
May 17, 2020
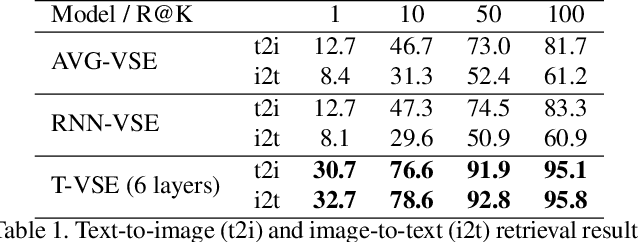
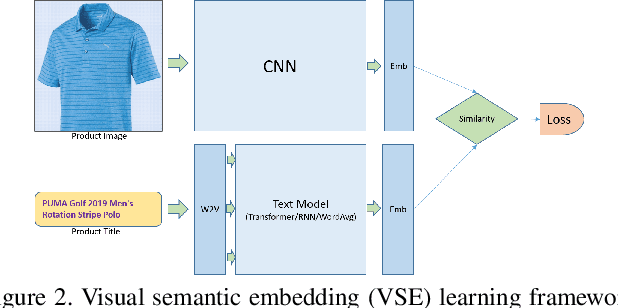
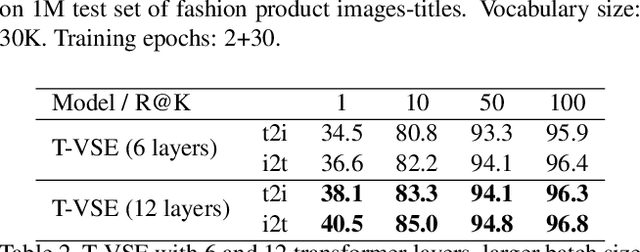
Transformer models have recently achieved impressive performance on NLP tasks, owing to new algorithms for self-supervised pre-training on very large text corpora. In contrast, recent literature suggests that simple average word models outperform more complicated language models, e.g., RNNs and Transformers, on cross-modal image/text search tasks on standard benchmarks, like MS COCO. In this paper, we show that dataset scale and training strategy are critical and demonstrate that transformer-based cross-modal embeddings outperform word average and RNN-based embeddings by a large margin, when trained on a large dataset of e-commerce product image-title pairs.
Orderless Recurrent Models for Multi-label Classification
Nov 25, 2019
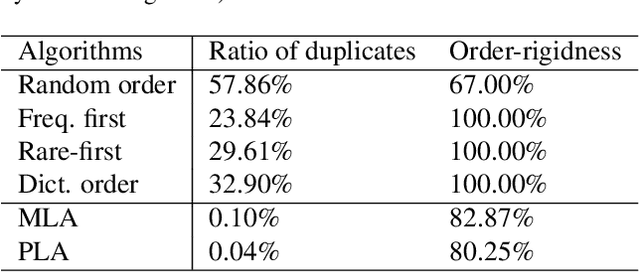
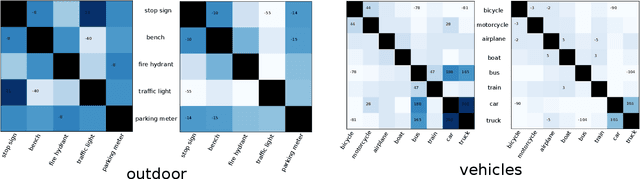
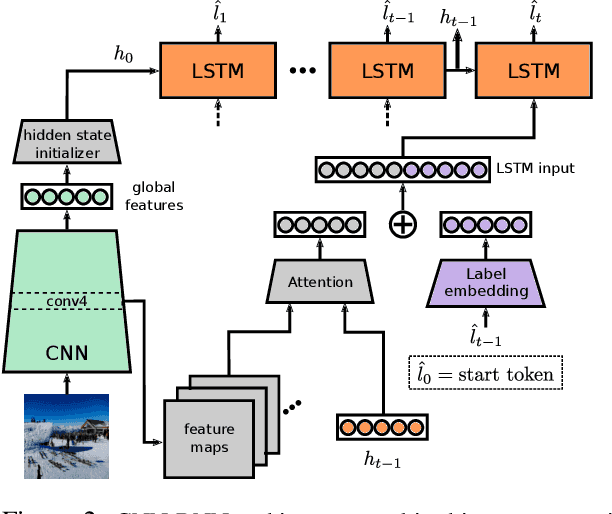
Recurrent neural networks (RNN) are popular for many computer vision tasks, including multi-label classification. Since RNNs produce sequential outputs, labels need to be ordered for the multi-label classification task. Current approaches sort labels according to their frequency, typically ordering them in either rare-first or frequent-first. These imposed orderings do not take into account that the natural order to generate the labels can change for each image, e.g.\ first the dominant object before summing up the smaller objects in the image. Therefore, in this paper, we propose ways to dynamically order the ground truth labels with the predicted label sequence. This allows for the faster training of more optimal LSTM models for multi-label classification. Analysis evidences that our method does not suffer from duplicate generation, something which is common for other models. Furthermore, it outperforms other CNN-RNN models, and we show that a standard architecture of an image encoder and language decoder trained with our proposed loss obtains the state-of-the-art results on the challenging MS-COCO, WIDER Attribute and PA-100K and competitive results on NUS-WIDE.
Learning Metrics from Teachers: Compact Networks for Image Embedding
Apr 07, 2019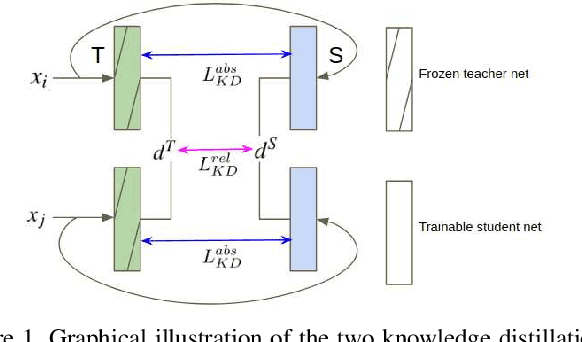
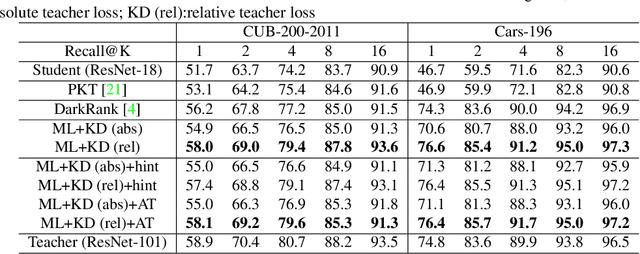
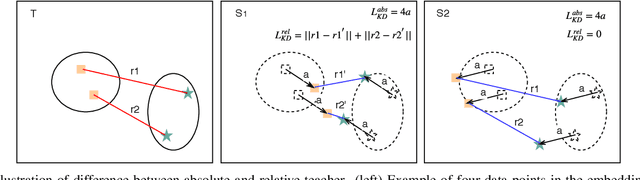
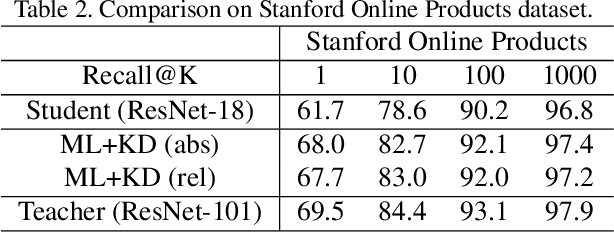
Metric learning networks are used to compute image embeddings, which are widely used in many applications such as image retrieval and face recognition. In this paper, we propose to use network distillation to efficiently compute image embeddings with small networks. Network distillation has been successfully applied to improve image classification, but has hardly been explored for metric learning. To do so, we propose two new loss functions that model the communication of a deep teacher network to a small student network. We evaluate our system in several datasets, including CUB-200-2011, Cars-196, Stanford Online Products and show that embeddings computed using small student networks perform significantly better than those computed using standard networks of similar size. Results on a very compact network (MobileNet-0.25), which can be used on mobile devices, show that the proposed method can greatly improve Recall@1 results from 27.5\% to 44.6\%. Furthermore, we investigate various aspects of distillation for embeddings, including hint and attention layers, semi-supervised learning and cross quality distillation. (Code is available at https://github.com/yulu0724/EmbeddingDistillation.)
Visually-Aware Personalized Recommendation using Interpretable Image Representations
Aug 21, 2018
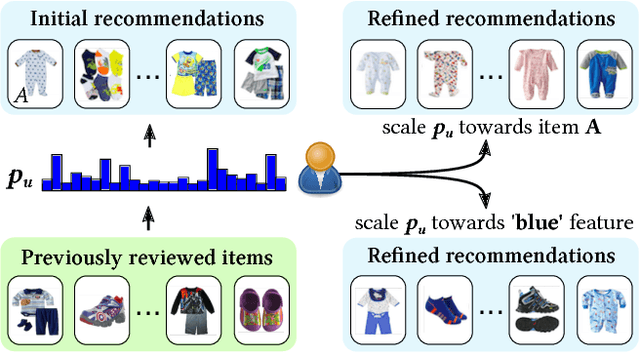


Visually-aware recommender systems use visual signals present in the underlying data to model the visual characteristics of items and users' preferences towards them. In the domain of clothing recommendation, incorporating items' visual information (e.g., product images) is particularly important since clothing item appearance is often a critical factor in influencing the user's purchasing decisions. Current state-of-the-art visually-aware recommender systems utilize image features extracted from pre-trained deep convolutional neural networks, however these extremely high-dimensional representations are difficult to interpret, especially in relation to the relatively low number of visual properties that may guide users' decisions. In this paper we propose a novel approach to personalized clothing recommendation that models the dynamics of individual users' visual preferences. By using interpretable image representations generated with a unique feature learning process, our model learns to explain users' prior feedback in terms of their affinity towards specific visual attributes and styles. Our approach achieves state-of-the-art performance on personalized ranking tasks, and the incorporation of interpretable visual features allows for powerful model introspection, which we demonstrate by using an interactive recommendation algorithm and visualizing the rise and fall of fashion trends over time.