 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENIUS: A Generative Framework for Universal Multimodal Search
Mar 25, 2025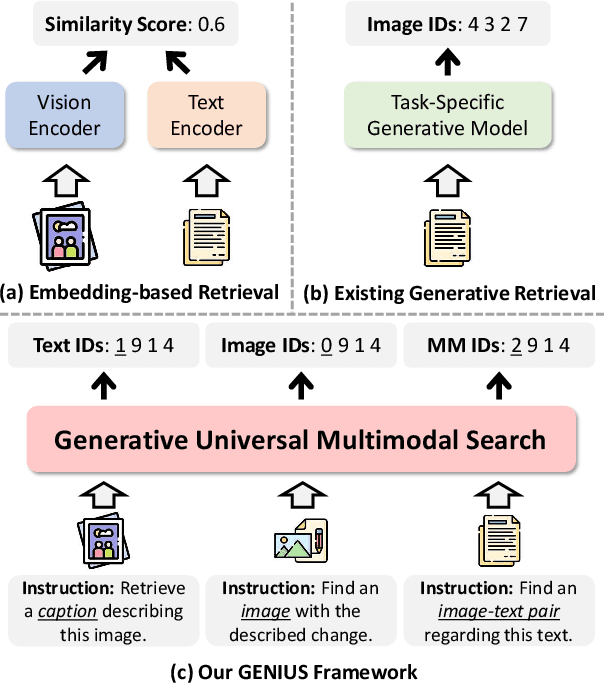
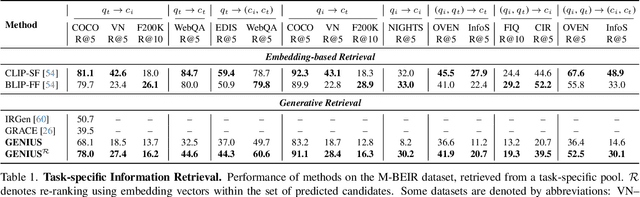
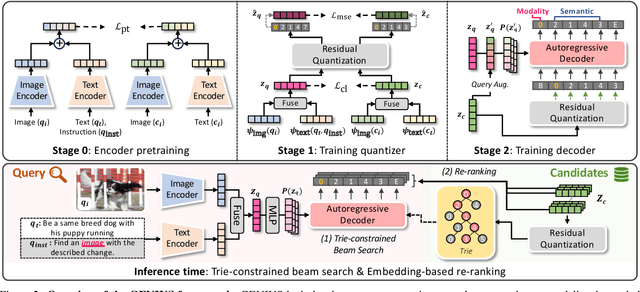
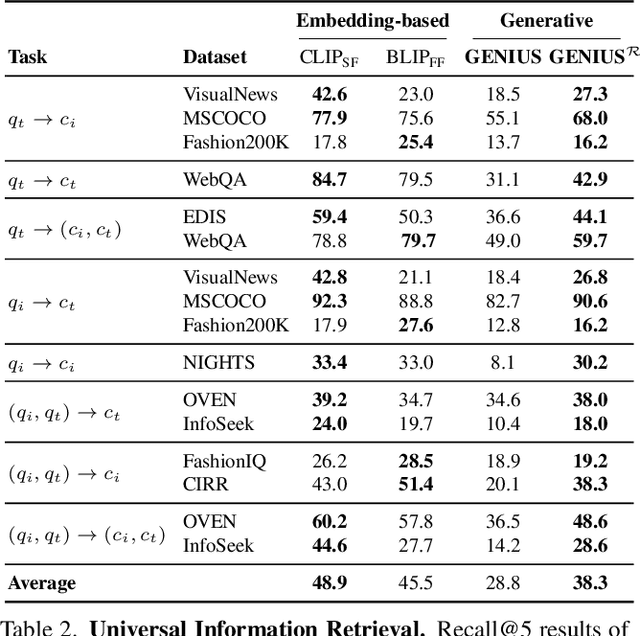
Generative retrieval is an emerging approach in information retrieval that generates identifiers (IDs) of target data based on a query, providing an efficient alternative to traditional embedding-based retrieval methods. However, existing models are task-specific and fall short of embedding-based retrieval in performance. This paper proposes GENIUS, a universal generative retrieval framework supporting diverse tasks across multiple modalities and domains. At its core, GENIUS introduces modality-decoupled semantic quantization, transforming multimodal data into discrete IDs encoding both modality and semantics. Moreover, to enhance generalization, we propose a query augmentation that interpolates between a query and its target, allowing GENIUS to adapt to varied query forms. Evaluated on the M-BEIR benchmark, it surpasses prior generative methods by a clear margin. Unlike embedding-based retrieval, GENIUS consistently maintains high retrieval speed across database size, with competitive performance across multiple benchmarks. With additional re-ranking, GENIUS often achieves results close to those of embedding-based methods while preserving efficiency.
Unsupervised and semi-supervised co-salient object detection via segmentation frequency statistics
Nov 11, 2023In this paper, we address the detection of co-occurring salient objects (CoSOD) in an image group using frequency statistics in an unsupervised manner, which further enable us to develop a semi-supervised method. While previous works have mostly focused on fully supervised CoSOD, less attention has been allocated to detecting co-salient objects when limited segmentation annotations are available for training. Our simple yet effective unsupervised method US-CoSOD combines the object co-occurrence frequency statistics of unsupervised single-image semantic segmentations with salient foreground detections using self-supervised feature learning. For the first time, we show that a large unlabeled dataset e.g. ImageNet-1k can be effectively leveraged to significantly improve unsupervised CoSOD performance. Our unsupervised model is a great pre-training initialization for our semi-supervised model SS-CoSOD, especially when very limited labeled data is available for training. To avoid propagating erroneous signals from predictions on unlabeled data, we propose a confidence estimation module to guide our semi-supervised training. Extensive experiments on three CoSOD benchmark datasets show that both of our unsupervised and semi-supervised models outperform the corresponding state-of-the-art models by a significant margin (e.g., on the Cosal2015 dataset, our US-CoSOD model has an 8.8% F-measure gain over a SOTA unsupervised co-segmentation model and our SS-CoSOD model has an 11.81% F-measure gain over a SOTA semi-supervised CoSOD model).
ProcSim: Proxy-based Confidence for Robust Similarity Learning
Nov 01, 2023Deep Metric Learning (DML) methods aim at learning an embedding space in which distances are closely related to the inherent semantic similarity of the inputs. Previous studies have shown that popular benchmark datasets often contain numerous wrong labels, and DML methods are susceptible to them. Intending to study the effect of realistic noise, we create an ontology of the classes in a dataset and use it to simulate semantically coherent labeling mistakes. To train robust DML models, we propose ProcSim, a simple framework that assigns a confidence score to each sample using the normalized distance to its class representative. The experimental results show that the proposed method achieves state-of-the-art performance on the DML benchmark datasets injected with uniform and the proposed semantically coherent noise.
Hierarchical Proxy-based Loss for Deep Metric Learning
Mar 25, 2021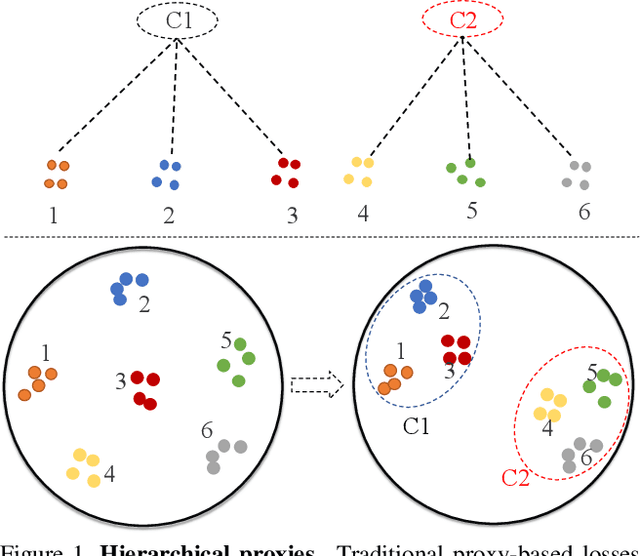
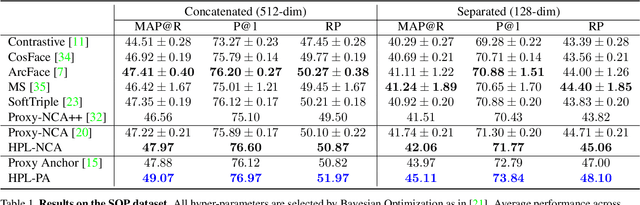
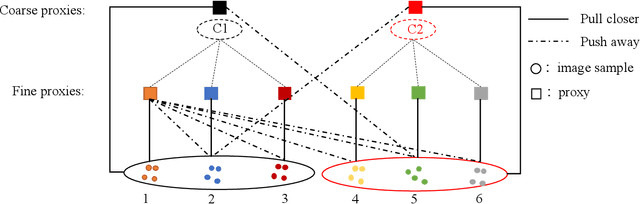
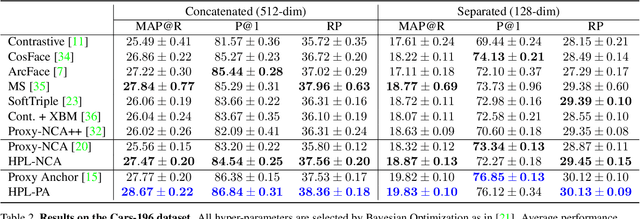
Proxy-based metric learning losses are superior to pair-based losses due to their fast convergence and low training complexity. However, existing proxy-based losses focus on learning class-discriminative features while overlooking the commonalities shared across classes which are potentially useful in describing and matching samples. Moreover, they ignore the implicit hierarchy of categories in real-world datasets, where similar subordinate classes can be grouped together. In this paper, we present a framework that leverages this implicit hierarchy by imposing a hierarchical structure on the proxies and can be used with any existing proxy-based loss. This allows our model to capture both class-discriminative features and class-shared characteristics without breaking the implicit data hierarchy. We evaluate our method on five established image retrieval datasets such as In-Shop and SOP. Results demonstrate that our hierarchical proxy-based loss framework improves the performance of existing proxy-based losses, especially on large datasets which exhibit strong hierarchical structure.
T-VSE: Transformer-Based Visual Semantic Embedding
May 17, 2020
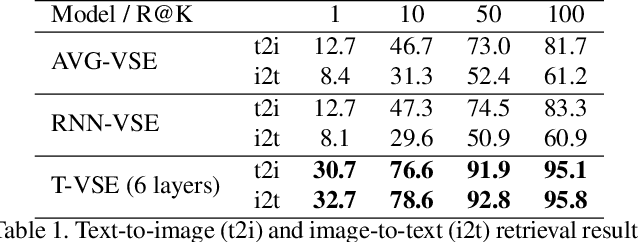
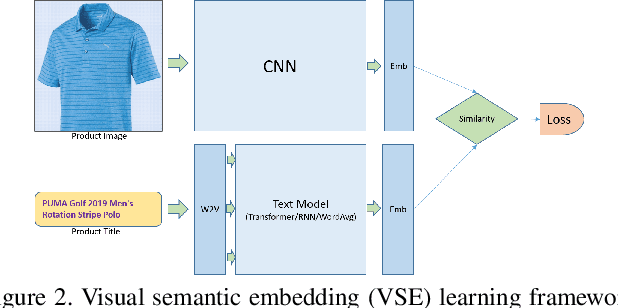
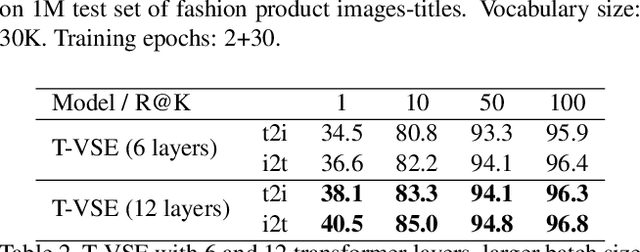
Transformer models have recently achieved impressive performance on NLP tasks, owing to new algorithms for self-supervised pre-training on very large text corpora. In contrast, recent literature suggests that simple average word models outperform more complicated language models, e.g., RNNs and Transformers, on cross-modal image/text search tasks on standard benchmarks, like MS COCO. In this paper, we show that dataset scale and training strategy are critical and demonstrate that transformer-based cross-modal embeddings outperform word average and RNN-based embeddings by a large margin, when trained on a large dataset of e-commerce product image-title pairs.
Large Scale Open-Set Deep Logo Detection
Nov 18, 2019

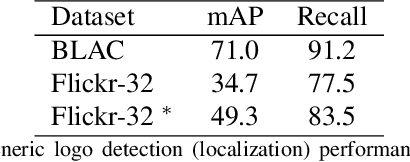
We present an open-set logo detection (OSLD) system, which can detect (localize and recognize) any number of unseen logo classes without re-training; it only requires a small set of canonical logo images for each logo class. We achieve this using a two-stage approach: (1) Generic logo detection to detect candidate logo regions in an image. (2) Logo matching for matching the detected logo regions to a set of canonical logo images to recognize them. We also introduce a 'simple deep metric learning' (SDML) framework that outperformed more complicated ensemble and attention models and boosted the logo matching accuracy. Furthermore, we constructed a new open-set logo detection dataset with thousands of logo classes, and will release it for research purposes. We demonstrate the effectiveness of OSLD on our dataset and on the standard Flickr-32 logo dataset, outperforming the state-of-the-art open-set and closed-set logo detection methods by a large margin.
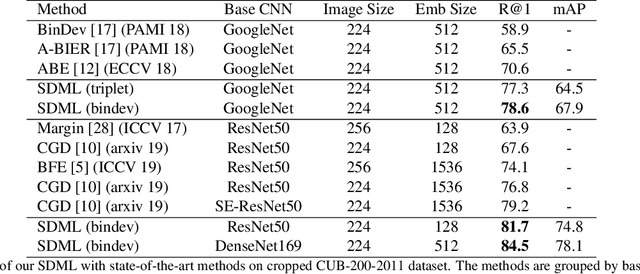
Semantic Granularity Metric Learning for Visual Search
Nov 14, 2019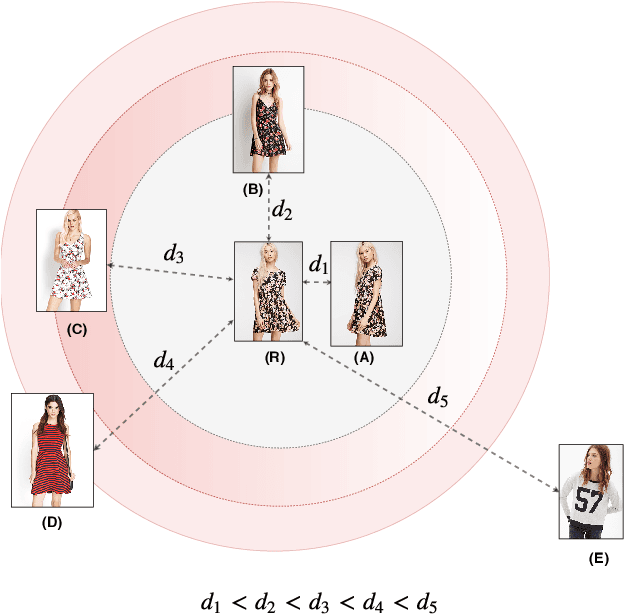

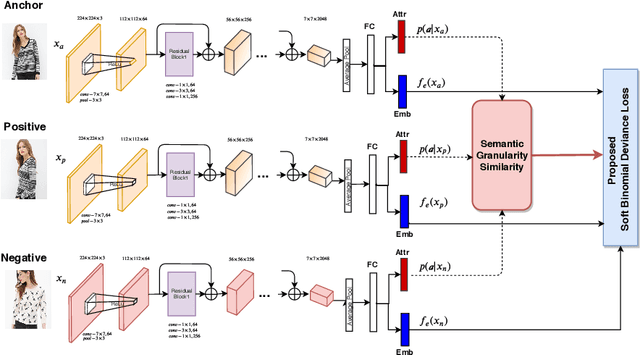
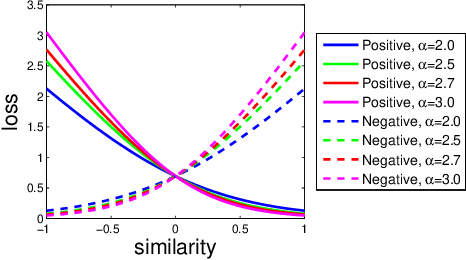
Deep metric learning applied to various applications has shown promising results in identification, retrieval and recognition. Existing methods often do not consider different granularity in visual similarity. However, in many domain applications, images exhibit similarity at multiple granularities with visual semantic concepts, e.g. fashion demonstrates similarity ranging from clothing of the exact same instance to similar looks/design or a common category. Therefore, training image triplets/pairs used for metric learning inherently possess different degree of information. However, the existing methods often treats them with equal importance during training. This hinders capturing the underlying granularities in feature similarity required for effective visual search. In view of this, we propose a new deep semantic granularity metric learning (SGML) that develops a novel idea of leveraging attribute semantic space to capture different granularity of similarity, and then integrate this information into deep metric learning. The proposed method simultaneously learns image attributes and embeddings using multitask CNNs. The two tasks are not only jointly optimized but are further linked by the semantic granularity similarity mappings to leverage the correlations between the tasks. To this end, we propose a new soft-binomial deviance loss that effectively integrates the degree of information in training samples, which helps to capture visual similarity at multiple granularities. Compared to recent ensemble-based methods, our framework is conceptually elegant, computationally simple and provides better performance. We perform extensive experiments on benchmark metric learning datasets and demonstrate that our method outperforms recent state-of-the-art methods, e.g., 1-4.5\% improvement in Recall@1 over the previous state-of-the-arts [1],[2] on DeepFashion In-Shop dataset.
Mobile Multi-View Object Image Search
Apr 30, 2018

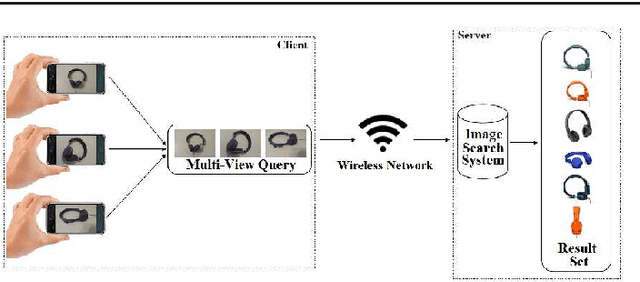

High user interaction capability of mobile devices can help improve the accuracy of mobile visual search systems. At query time, it is possible to capture multiple views of an object from different viewing angles and at different scales with the mobile device camera to obtain richer information about the object compared to a single view and hence return more accurate results. Motivated by this, we developed a mobile multi-view object image search system, using a client-server architecture. Multi-view images of objects acquired by the mobile clients are processed and local features are sent to the server, which combines the query image representations with early/late fusion methods based on bag-of-visual-words and sends back the query results. We performed a comprehensive analysis of early and late fusion approaches using various similarity functions, on an existing single view and a new multi-view object image database. The experimental results show that multi-view search provides significantly better retrieval accuracy compared to single view search.
Remote Detection of Idling Cars Using Infrared Imaging and Deep Networks
Apr 28, 2018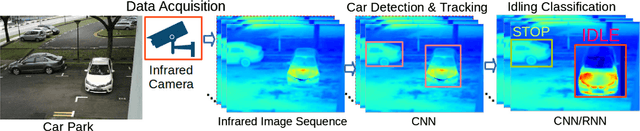

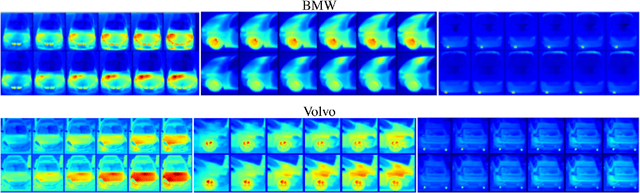
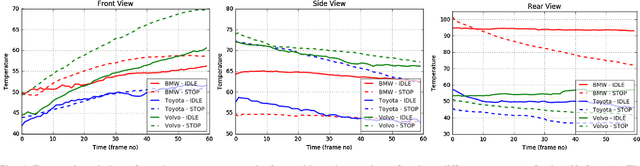
Idling vehicles waste energy and pollute the environment through exhaust emission. In some countries, idling a vehicle for more than a predefined duration is prohibited and automatic idling vehicle detection is desirable for law enforcement. We propose the first automatic system to detect idling cars, using infrared (IR) imaging and deep networks. We rely on the differences in spatio-temporal heat signatures of idling and stopped cars and monitor the car temperature with a long-wavelength IR camera. We formulate the idling car detection problem as spatio-temporal event detection in IR image sequences and employ deep networks for spatio-temporal modeling. We collected the first IR image sequence dataset for idling car detection. First, we detect the cars in each IR image using a convolutional neural network, which is pre-trained on regular RGB images and fine-tuned on IR images for higher accuracy. Then, we track the detected cars over time to identify the cars that are parked. Finally, we use the 3D spatio-temporal IR image volume of each parked car as input to convolutional and recurrent networks to classify them as idling or not. We carried out an extensive empirical evaluation of temporal and spatio-temporal modeling approaches with various convolutional and recurrent architectures. We present promising experimental results on our IR image sequence dataset.
Multi-View Product Image Search Using Deep ConvNets Representations
May 01, 2017

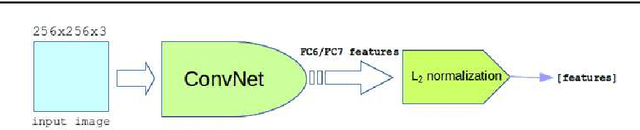
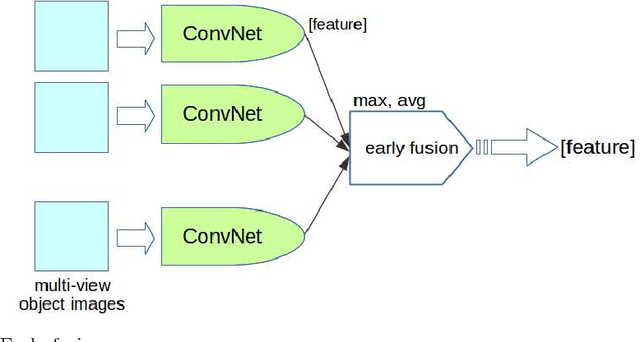
Multi-view product image queries can improve retrieval performance over single view queries significantly. In this paper, we investigated the performance of deep convolutional neural networks (ConvNets) on multi-view product image search. First, we trained a VGG-like network to learn deep ConvNets representations of product images. Then, we computed the deep ConvNets representations of database and query images and performed single view queries, and multi-view queries using several early and late fusion approaches. We performed extensive experiments on the publicly available Multi-View Object Image Dataset (MVOD 5K) with both clean background queries from the Internet and cluttered background queries from a mobile phone. We compared the performance of ConvNets to the classical bag-of-visual-words (BoWs). We concluded that (1) multi-view queries with deep ConvNets representations perform significantly better than single view queries, (2) ConvNets perform much better than BoWs and have room for further improvement, (3) pre-training of ConvNets on a different image dataset with background clutter is needed to obtain good performance on cluttered product image queries obtained with a mobile phone.