 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Polarization Modulation: Enabling CSI-Free DCO-OFDM over Dynamic OWC Channels
Mar 18, 2026In dynamically varying optical wireless communication (OWC) links, conventional quadrature amplitude modulation (QAM) in optical orthogonal frequency-division multiplexing (OFDM) requires frequent channel estimation and equalization, incurring pilot overhead and processing latency. This paper proposes a virtual polarization modulation (VPM)-based direct-current-biased optical OFDM (DCO-OFDM) scheme that maps each data symbol onto the three-dimensional Stokes space and places its corresponding Jones vector across two adjacent OFDM subcarriers. Using a rotation-based analytical framework, closed-form symbol error rate (SER) expressions are derived for arbitrary spherical constellations, along with upper and lower bounds and high signal-to-noise ratio (SNR) approximations. The framework is further extended to practical OWC scenarios with frequency-selective channels and atmospheric turbulence. Monte Carlo (MC) simulations validate the theoretical results. The results show that under practical OWC impairments, VPM outperforms QAM with least-squares (LS) channel estimation and minimum mean square error (MMSE) equalization. At a target SER of $10^{-5}$, 16-VPM achieves SNR gains of approximately 7.5 dB and 4 dB over equalized 16-QAM and 8-QAM, respectively, in frequency-selective channels, and a 6 dB advantage over equalized 16-QAM under atmospheric turbulence. By eliminating the need for channel state information, the proposed VPM-based DCO-OFDM provides a robust and low-latency solution for dynamic OWC links.
DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search
Oct 14, 2025Multimodal Large Language Models (MLLMs) in real-world applications require access to external knowledge sources and must remain responsive to the dynamic and ever-changing real-world information in order to address information-seeking and knowledge-intensive user queries. Existing approaches, such as retrieval augmented generation (RAG) methods, search agents, and search equipped MLLMs, often suffer from rigid pipelines, excessive search calls, and poorly constructed search queries, which result in inefficiencies and suboptimal outcomes. To address these limitations, we present DeepMMSearch-R1, the first multimodal LLM capable of performing on-demand, multi-turn web searches and dynamically crafting queries for both image and text search tools. Specifically, DeepMMSearch-R1 can initiate web searches based on relevant crops of the input image making the image search more effective, and can iteratively adapt text search queries based on retrieved information, thereby enabling self-reflection and self-correction. Our approach relies on a two-stage training pipeline: a cold start supervised finetuning phase followed by an online reinforcement learning optimization. For training, we introduce DeepMMSearchVQA, a novel multimodal VQA dataset created through an automated pipeline intermixed with real-world information from web search tools. This dataset contains diverse, multi-hop queries that integrate textual and visual information, teaching the model when to search, what to search for, which search tool to use and how to reason over the retrieved information. We conduct extensive experiments across a range of knowledge-intensive benchmarks to demonstrate the superiority of our approach. Finally, we analyze the results and provide insights that are valuable for advancing multimodal web-search.
Modeling of UV NLoS Communication Channels: From Atmospheric Scattering and Obstacle Reflection Perspectives
Nov 08, 2024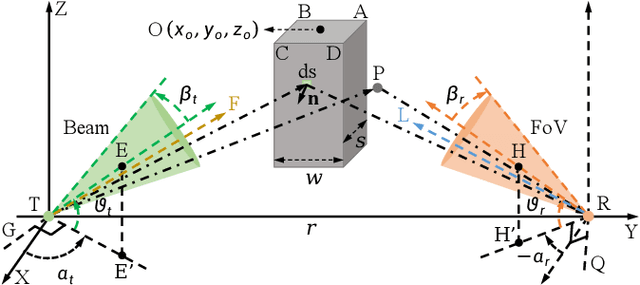
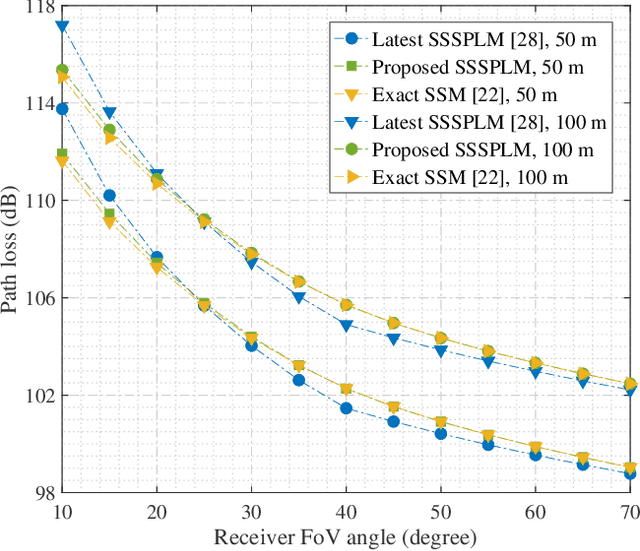
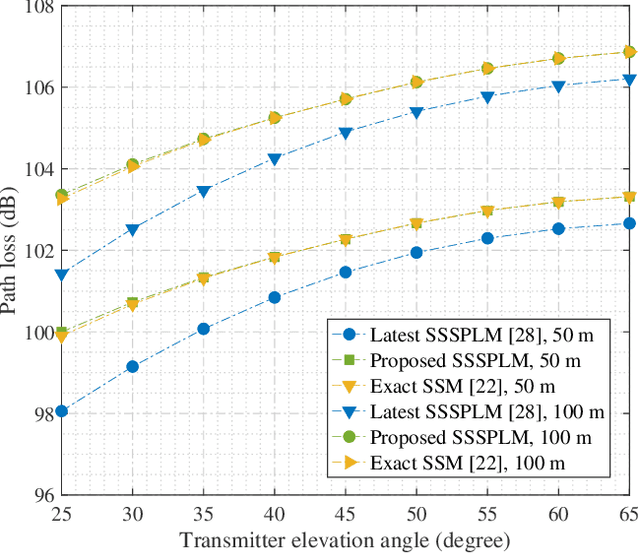
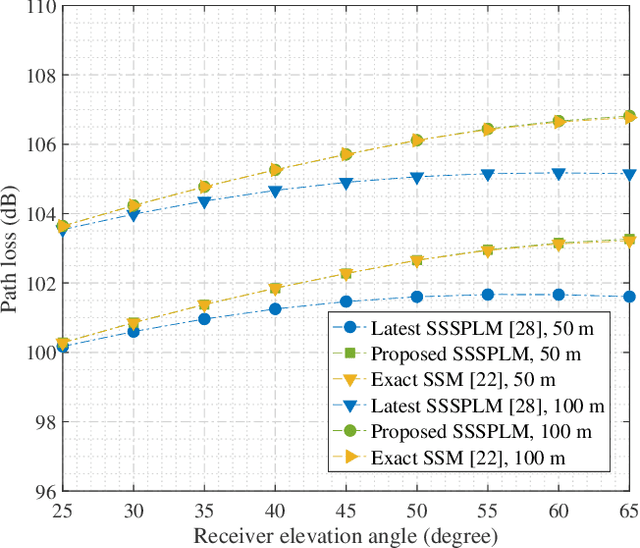
As transceiver elevation angles increase from small to large, existing ultraviolet (UV) non-line-of-sight (NLoS) models encounter two challenges: i) cannot estimate the channel characteristics of UV NLoS communication scenarios when there exists an obstacle in the overlap volume between the transmitter beam and the receiver field-of-view (FoV), and ii) cannot evaluate the channel path loss for the wide beam and wide FoV scenarios with existing simplified single-scattering path loss models. To address these challenges, a UV NLoS scattering model incorporating an obstacle was investigated, where the obstacle's orientation angle, coordinates, and geometric dimensions were taken into account to approach actual application environments. Then, a UV NLoS reflection model was developed combined with specific geometric diagrams. Further, a simplified single-scattering path loss model was proposed with a closed-form expression. Finally, the proposed models were validated by comparing them with the Monte-Carlo photon-tracing model, the exact single-scattering model, and the latest simplified single-scattering model. Numerical results show that the path loss curves obtained by the proposed models agree well with those attained by related NLoS models under identical parameter settings, and avoiding obstacles is not always a good option for UV NLoS communications. Moreover, the accuracy of the proposed simplified model is superior to that of the existing simplified model for all kinds of transceiver FoV angles.
Channel Modeling for Ultraviolet Non-Line-of-Sight Communications Incorporating an Obstacle
Nov 08, 2024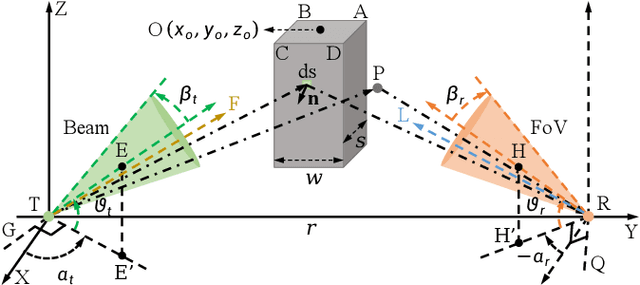
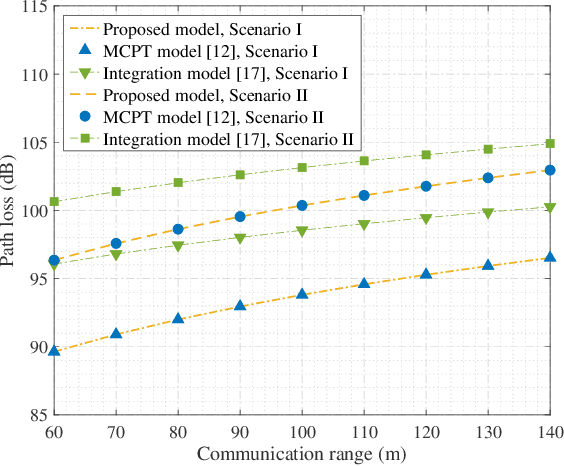
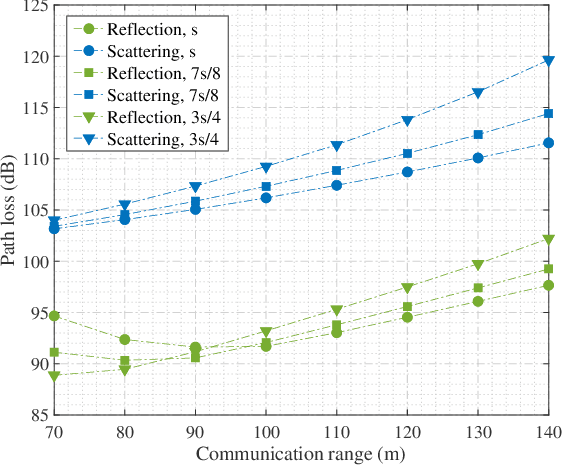

Existing studies on ultraviolet (UV) non-line-of-sight (NLoS) channel modeling primarily focus on scenarios without any obstacle, which makes them unsuitable for small transceiver elevation angles in most cases. To address this issue, a UV NLoS channel model incorporating an obstacle was investigated in this paper, where the impacts of atmospheric scattering and obstacle reflection on UV signals were both taken into account. To validate the proposed model, we compared it to the related Monte-Carlo photon-tracing (MCPT) model that had been verified by outdoor experiments. Numerical results manifest that the path loss curves obtained by the proposed model agree well with those determined by the MCPT model, while its computation complexity is lower than that of the MCPT model. This work discloses that obstacle reflection can effectively reduce the channel path loss of UV NLoS communication systems.
Single-Collision Model for Non-Line-of-Sight UV Communication Channel With Obstacle
Nov 08, 2024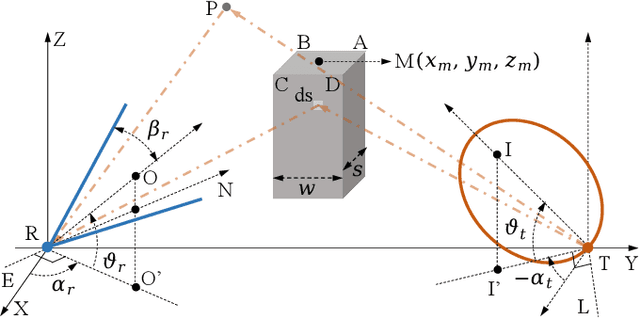

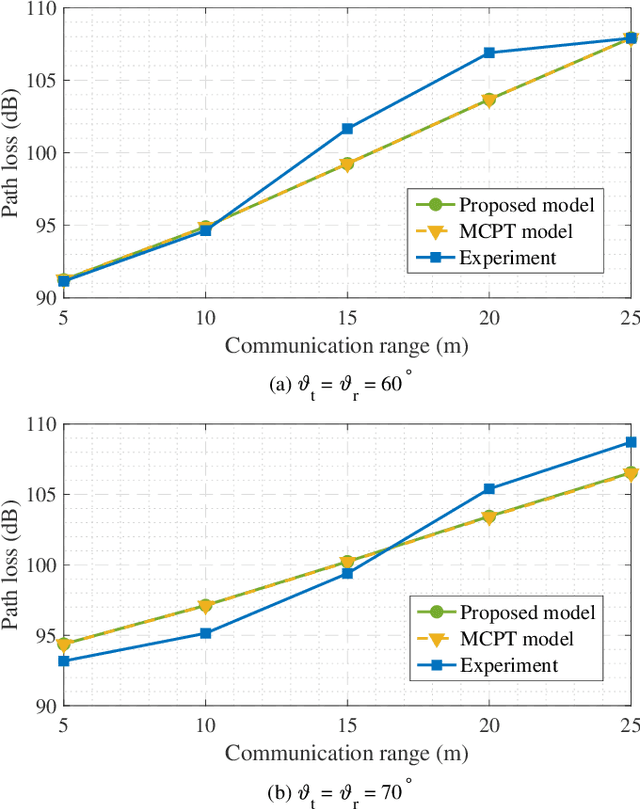
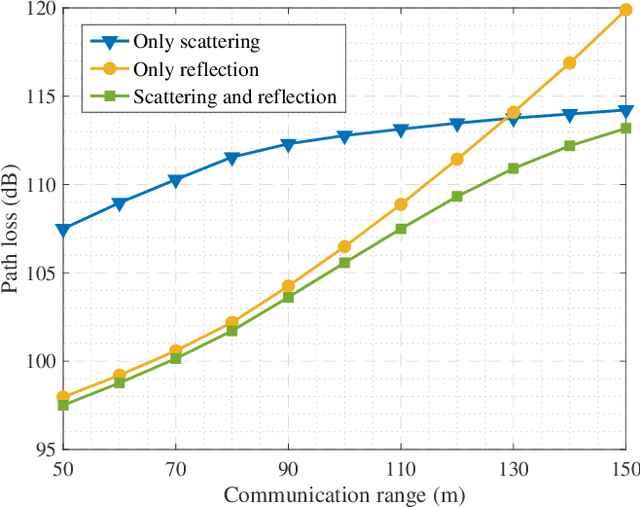
Existing research on non-line-of-sight (NLoS) ultraviolet (UV) channel modeling mainly focuses on scenarios where the signal propagation process is not affected by any obstacle and the radiation intensity (RI) of the light source is uniformly distributed. To eliminate these restrictions, we propose a single-collision model for the NLoS UV channel incorporating a cuboid-shaped obstacle, where the RI of the UV light source is modeled as the Lambertian distribution. For easy interpretation, we categorize the intersection circumstances between the receiver field-of-view and the obstacle into six cases and provide derivations of the weighting factor for each case. To investigate the accuracy of the proposed model, we compare it with the associated Monte Carlo photon tracing model via simulations and experiments. Results verify the correctness of the proposed model. This work reveals that obstacle avoidance is not always beneficial for NLoS UV communications and provides guidelines for relevant system design.
Large Scale Open-Set Deep Logo Detection
Nov 18, 2019
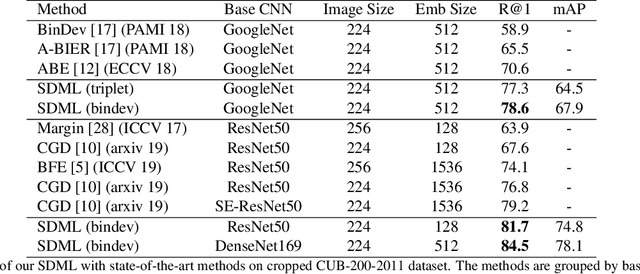

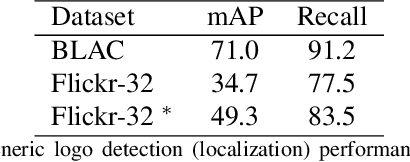
We present an open-set logo detection (OSLD) system, which can detect (localize and recognize) any number of unseen logo classes without re-training; it only requires a small set of canonical logo images for each logo class. We achieve this using a two-stage approach: (1) Generic logo detection to detect candidate logo regions in an image. (2) Logo matching for matching the detected logo regions to a set of canonical logo images to recognize them. We also introduce a 'simple deep metric learning' (SDML) framework that outperformed more complicated ensemble and attention models and boosted the logo matching accuracy. Furthermore, we constructed a new open-set logo detection dataset with thousands of logo classes, and will release it for research purposes. We demonstrate the effectiveness of OSLD on our dataset and on the standard Flickr-32 logo dataset, outperforming the state-of-the-art open-set and closed-set logo detection methods by a large margin.
Multi-modal Image Registration for Correlative Microscopy
Jan 13, 2015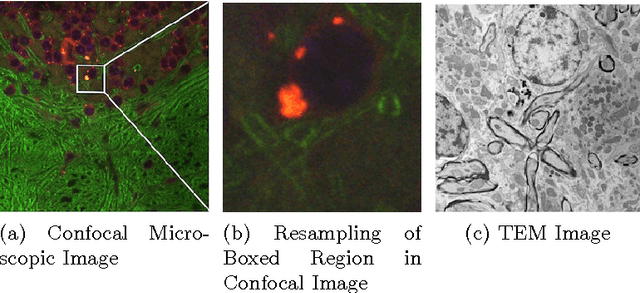
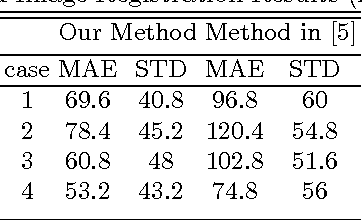

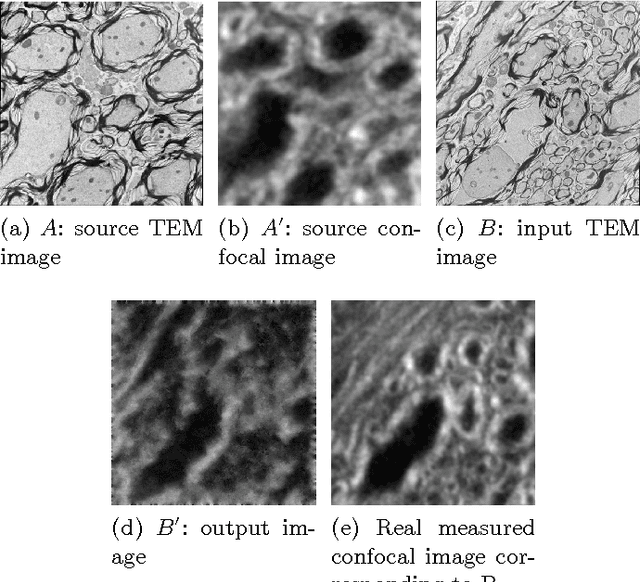
Correlative microscopy is a methodology combining the functionality of light microscopy with the high resolution of electron microscopy and other microscopy technologies. Image registration for correlative microscopy is quite challenging because it is a multi-modal, multi-scale and multi-dimensional registration problem. In this report, I introduce two methods of image registration for correlative microscopy. The first method is based on fiducials (beads). I generate landmarks from the fiducials and compute the similarity transformation matrix based on three pairs of nearest corresponding landmarks. A least-squares matching process is applied afterwards to further refine the registration. The second method is inspired by the image analogies approach. I introduce the sparse representation model into image analogies. I first train representative image patches (dictionaries) for pre-registered datasets from two different modalities, and then I use the sparse coding technique to transfer a given image to a predicted image from one modality to another based on the learned dictionaries. The final image registration is between the predicted image and the original image corresponding to the given image in the different modality. The method transforms a multi-modal registration problem to a mono-modal one. I test my approaches on Transmission Electron Microscopy (TEM) and confocal microscopy images. Experimental results of the methods are also shown in this report.