 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Up LLM Reviews for Google Ads Content Moderation
Feb 07, 2024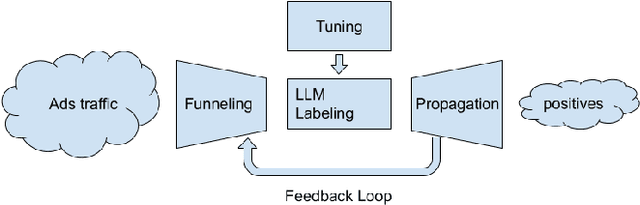
Large language models (LLMs) are powerful tools for content moderation, but their inference costs and latency make them prohibitive for casual use on large datasets, such as the Google Ads repository. This study proposes a method for scaling up LLM reviews for content moderation in Google Ads. First, we use heuristics to select candidates via filtering and duplicate removal, and create clusters of ads for which we select one representative ad per cluster. We then use LLMs to review only the representative ads. Finally, we propagate the LLM decisions for the representative ads back to their clusters. This method reduces the number of reviews by more than 3 orders of magnitude while achieving a 2x recall compared to a baseline non-LLM model. The success of this approach is a strong function of the representations used in clustering and label propagation; we found that cross-modal similarity representations yield better results than uni-modal representations.
Benchmarking Robustness to Adversarial Image Obfuscations
Jan 30, 2023



Automated content filtering and moderation is an important tool that allows online platforms to build striving user communities that facilitate cooperation and prevent abuse. Unfortunately, resourceful actors try to bypass automated filters in a bid to post content that violate platform policies and codes of conduct. To reach this goal, these malicious actors may obfuscate policy violating images (e.g. overlay harmful images by carefully selected benign images or visual patterns) to prevent machine learning models from reaching the correct decision. In this paper, we invite researchers to tackle this specific issue and present a new image benchmark. This benchmark, based on ImageNet, simulates the type of obfuscations created by malicious actors. It goes beyond ImageNet-$\textrm{C}$ and ImageNet-$\bar{\textrm{C}}$ by proposing general, drastic, adversarial modifications that preserve the original content intent. It aims to tackle a more common adversarial threat than the one considered by $\ell_p$-norm bounded adversaries. We evaluate 33 pretrained models on the benchmark and train models with different augmentations, architectures and training methods on subsets of the obfuscations to measure generalization. We hope this benchmark will encourage researchers to test their models and methods and try to find new approaches that are more robust to these obfuscations.
T-VSE: Transformer-Based Visual Semantic Embedding
May 17, 2020
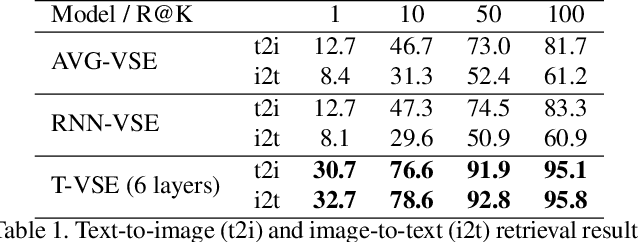
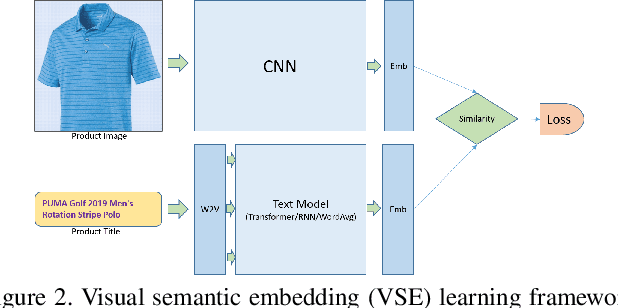
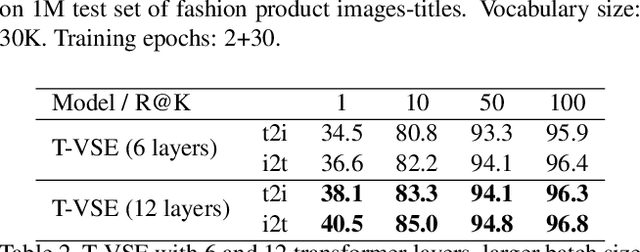
Transformer models have recently achieved impressive performance on NLP tasks, owing to new algorithms for self-supervised pre-training on very large text corpora. In contrast, recent literature suggests that simple average word models outperform more complicated language models, e.g., RNNs and Transformers, on cross-modal image/text search tasks on standard benchmarks, like MS COCO. In this paper, we show that dataset scale and training strategy are critical and demonstrate that transformer-based cross-modal embeddings outperform word average and RNN-based embeddings by a large margin, when trained on a large dataset of e-commerce product image-title pairs.
Large Scale Open-Set Deep Logo Detection
Nov 18, 2019
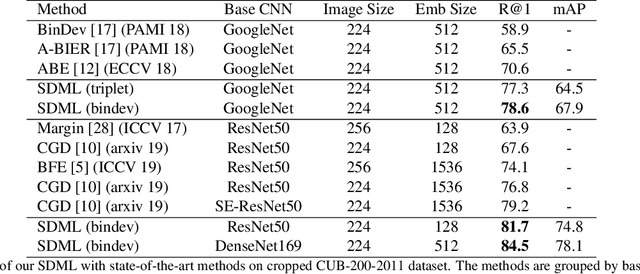

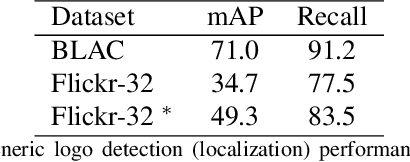
We present an open-set logo detection (OSLD) system, which can detect (localize and recognize) any number of unseen logo classes without re-training; it only requires a small set of canonical logo images for each logo class. We achieve this using a two-stage approach: (1) Generic logo detection to detect candidate logo regions in an image. (2) Logo matching for matching the detected logo regions to a set of canonical logo images to recognize them. We also introduce a 'simple deep metric learning' (SDML) framework that outperformed more complicated ensemble and attention models and boosted the logo matching accuracy. Furthermore, we constructed a new open-set logo detection dataset with thousands of logo classes, and will release it for research purposes. We demonstrate the effectiveness of OSLD on our dataset and on the standard Flickr-32 logo dataset, outperforming the state-of-the-art open-set and closed-set logo detection methods by a large margin.