 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinPoint: Evaluation of Composed Image Retrieval with Explicit Negatives, Multi-Image Queries, and Paraphrase Testing
Mar 04, 2026Composed Image Retrieval (CIR) has made significant progress, yet current benchmarks are limited to single ground-truth answers and lack the annotations needed to evaluate false positive avoidance, robustness and multi-image reasoning. We present PinPoint, a comprehensive real world benchmark with 7,635 queries and 329K relevance judgments across 23 query categories. PinPoint advances the field by providing: (1) multiple correct answers (averaging 9.1 per query) (2) explicit hard negatives, (3) six instruction paraphrases per query for robustness testing, (4) multi-image composition support (13.4% of queries), and (5) demographic metadata for fairness evaluation. Based on our analysis of 20+ methods across 4 different major paradigms, we uncover three significant drawbacks: The best methods while achieving mAP@10 of 28.5%, still retrieves irrelevant results (hard negatives) 9% of the time. The best models also exhibit 25.1% performance variation across paraphrases, indicating significant potential for enhancing current CIR techniques. Multi-image queries performs 40 to 70% worse across different methods. To overcome these new issues uncovered by our evaluation framework, we propose a training-free reranking method based on an off-the-shelf MLLM that can be applied to any existing system to bridge the gap. We release the complete dataset, including all images, queries, annotations, retrieval index, and benchmarking code.
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
Aug 12, 2021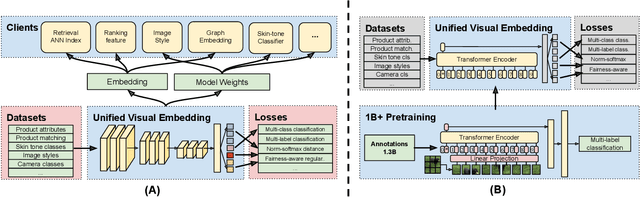


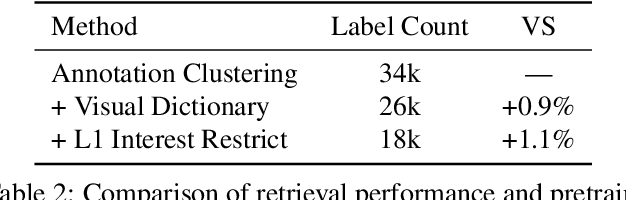
Large-scale pretraining of visual representations has led to state-of-the-art performance on a range of benchmark computer vision tasks, yet the benefits of these techniques at extreme scale in complex production systems has been relatively unexplored. We consider the case of a popular visual discovery product, where these representations are trained with multi-task learning, from use-case specific visual understanding (e.g. skin tone classification) to general representation learning for all visual content (e.g. embeddings for retrieval). In this work, we describe how we (1) generate a dataset with over a billion images via large weakly-supervised pretraining to improve the performance of these visual representations, and (2) leverage Transformers to replace the traditional convolutional backbone, with insights into both system and performance improvements, especially at 1B+ image scale. To support this backbone model, we detail a systematic approach to deriving weakly-supervised image annotations from heterogenous text signals, demonstrating the benefits of clustering techniques to handle the long-tail distribution of image labels. Through a comprehensive study of offline and online evaluation, we show that large-scale Transformer-based pretraining provides significant benefits to industry computer vision applications. The model is deployed in a production visual shopping system, with 36% improvement in top-1 relevance and 23% improvement in click-through volume. We conduct extensive experiments to better understand the empirical relationships between Transformer-based architectures, dataset scale, and the performance of production vision systems.
Shop The Look: Building a Large Scale Visual Shopping System at Pinterest
Jun 18, 2020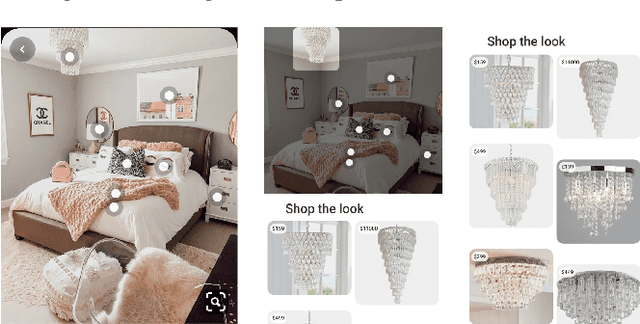

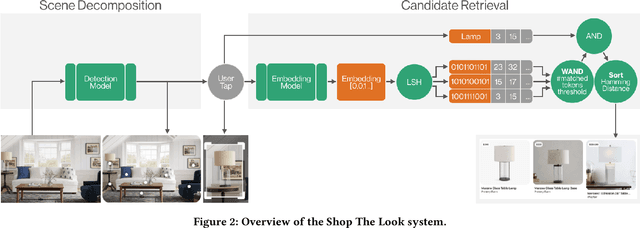
As online content becomes ever more visual, the demand for searching by visual queries grows correspondingly stronger. Shop The Look is an online shopping discovery service at Pinterest, leveraging visual search to enable users to find and buy products within an image. In this work, we provide a holistic view of how we built Shop The Look, a shopping oriented visual search system, along with lessons learned from addressing shopping needs. We discuss topics including core technology across object detection and visual embeddings, serving infrastructure for realtime inference, and data labeling methodology for training/evaluation data collection and human evaluation. The user-facing impacts of our system design choices are measured through offline evaluations, human relevance judgements, and online A/B experiments. The collective improvements amount to cumulative relative gains of over 160% in end-to-end human relevance judgements and over 80% in engagement. Shop The Look is deployed in production at Pinterest.
Large Scale Open-Set Deep Logo Detection
Nov 18, 2019
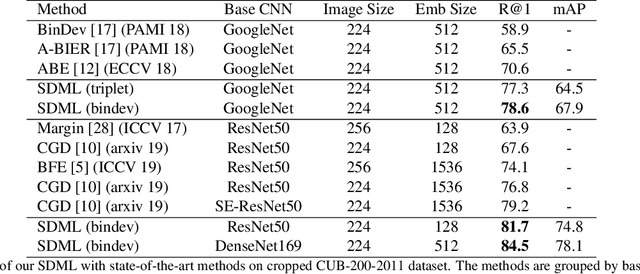

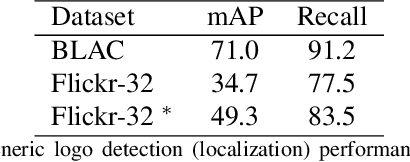
We present an open-set logo detection (OSLD) system, which can detect (localize and recognize) any number of unseen logo classes without re-training; it only requires a small set of canonical logo images for each logo class. We achieve this using a two-stage approach: (1) Generic logo detection to detect candidate logo regions in an image. (2) Logo matching for matching the detected logo regions to a set of canonical logo images to recognize them. We also introduce a 'simple deep metric learning' (SDML) framework that outperformed more complicated ensemble and attention models and boosted the logo matching accuracy. Furthermore, we constructed a new open-set logo detection dataset with thousands of logo classes, and will release it for research purposes. We demonstrate the effectiveness of OSLD on our dataset and on the standard Flickr-32 logo dataset, outperforming the state-of-the-art open-set and closed-set logo detection methods by a large margin.
Learning a Unified Embedding for Visual Search at Pinterest
Aug 05, 2019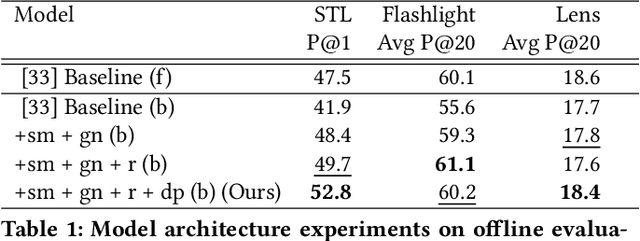

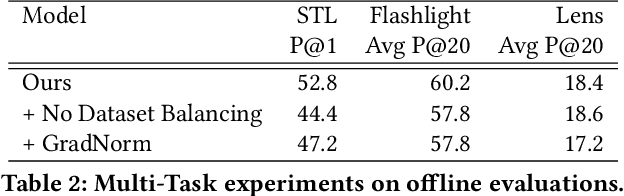
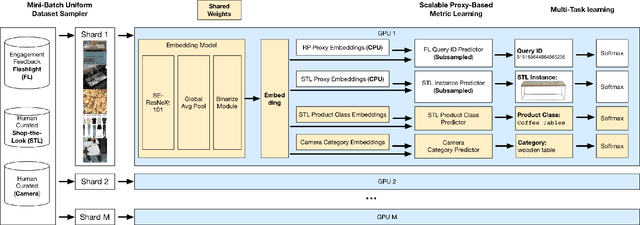
At Pinterest, we utilize image embeddings throughout our search and recommendation systems to help our users navigate through visual content by powering experiences like browsing of related content and searching for exact products for shopping. In this work we describe a multi-task deep metric learning system to learn a single unified image embedding which can be used to power our multiple visual search products. The solution we present not only allows us to train for multiple application objectives in a single deep neural network architecture, but takes advantage of correlated information in the combination of all training data from each application to generate a unified embedding that outperforms all specialized embeddings previously deployed for each product. We discuss the challenges of handling images from different domains such as camera photos, high quality web images, and clean product catalog images. We also detail how to jointly train for multiple product objectives and how to leverage both engagement data and human labeled data. In addition, our trained embeddings can also be binarized for efficient storage and retrieval without compromising precision and recall. Through comprehensive evaluations on offline metrics, user studies, and online A/B experiments, we demonstrate that our proposed unified embedding improves both relevance and engagement of our visual search products for both browsing and searching purposes when compared to existing specialized embeddings. Finally, the deployment of the unified embedding at Pinterest has drastically reduced the operation and engineering cost of maintaining multiple embeddings while improving quality.
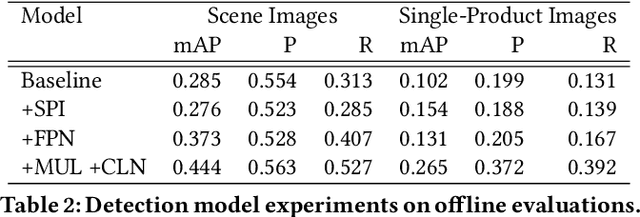
Making Classification Competitive for Deep Metric Learning
Nov 30, 2018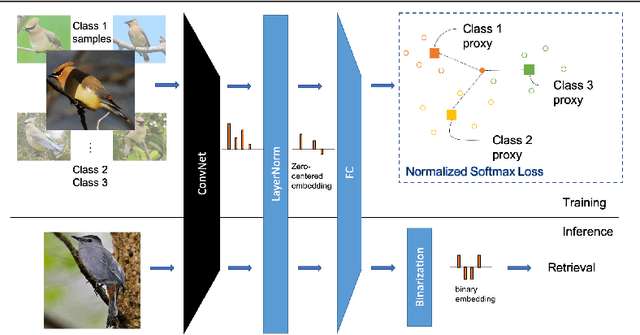
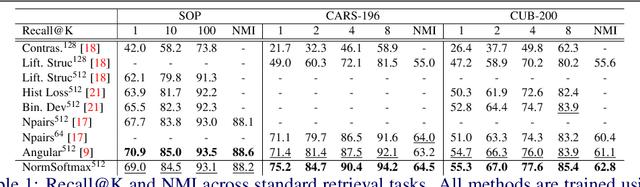
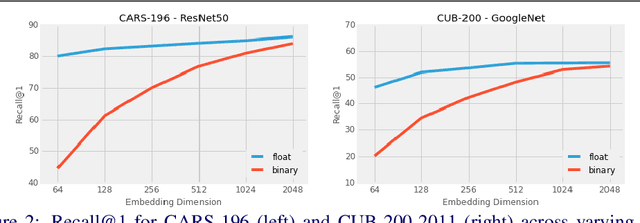

Deep metric learning aims to learn a function mapping image pixels to embedding feature vectors that model the similarity between images. The majority of current approaches are non-parametric, learning the metric space directly through the supervision of similar (pairs) or relatively similar (triplets) sets of images. A difficult challenge for training these approaches is mining informative samples of images as the metric space is learned with only the local context present within a single mini-batch. Alternative approaches use parametric metric learning to eliminate the need for sampling through supervision of images to proxies. Although this simplifies optimization, such proxy-based approaches have lagged behind in performance. In this work, we demonstrate that a standard classification network can be transformed into a variant of proxy-based metric learning that is competitive against non-parametric approaches across a wide variety of image retrieval tasks. We address key challenges in proxy-based metric learning such as performance under extreme classification and describe techniques to stabilize and learn higher dimensional embeddings. We evaluate our approach on the CAR-196, CUB-200-2011, Stanford Online Product, and In-Shop datasets for image retrieval and clustering. Finally, we show that our softmax classification approach can learn high-dimensional binary embeddings that achieve new state-of-the-art performance on all datasets evaluated with a memory footprint that is the same or smaller than competing approaches.