 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinPoint: Evaluation of Composed Image Retrieval with Explicit Negatives, Multi-Image Queries, and Paraphrase Testing
Mar 04, 2026Composed Image Retrieval (CIR) has made significant progress, yet current benchmarks are limited to single ground-truth answers and lack the annotations needed to evaluate false positive avoidance, robustness and multi-image reasoning. We present PinPoint, a comprehensive real world benchmark with 7,635 queries and 329K relevance judgments across 23 query categories. PinPoint advances the field by providing: (1) multiple correct answers (averaging 9.1 per query) (2) explicit hard negatives, (3) six instruction paraphrases per query for robustness testing, (4) multi-image composition support (13.4% of queries), and (5) demographic metadata for fairness evaluation. Based on our analysis of 20+ methods across 4 different major paradigms, we uncover three significant drawbacks: The best methods while achieving mAP@10 of 28.5%, still retrieves irrelevant results (hard negatives) 9% of the time. The best models also exhibit 25.1% performance variation across paraphrases, indicating significant potential for enhancing current CIR techniques. Multi-image queries performs 40 to 70% worse across different methods. To overcome these new issues uncovered by our evaluation framework, we propose a training-free reranking method based on an off-the-shelf MLLM that can be applied to any existing system to bridge the gap. We release the complete dataset, including all images, queries, annotations, retrieval index, and benchmarking code.
PinCLIP: Large-scale Foundational Multimodal Representation at Pinterest
Mar 03, 2026While multi-modal Visual Language Models (VLMs) have demonstrated significant success across various domains, the integration of VLMs into recommendation and retrieval systems remains a challenge, due to issues like training objective discrepancies and serving efficiency bottlenecks. This paper introduces PinCLIP, a large-scale visual representation learning approach developed to enhance retrieval and ranking models at Pinterest by leveraging VLMs to learn image-text alignment. We propose a novel hybrid Vision Transformer architecture that utilizes a VLM backbone and a hybrid fusion mechanism to capture multi-modality content representation at varying granularities. Beyond standard image-to-text alignment objectives, we introduce a neighbor alignment objective to model the cross-fusion of multi-modal representations within the Pinterest Pin-Board graph. Offline evaluations show that PinCLIP outperforms state-of-the-art baselines, such as Qwen, by 20% in multi-modal retrieval tasks. Online A/B testing demonstrates significant business impact, including substantial engagement gains across all major surfaces in Pinterest. Notably, PinCLIP significantly addresses the "cold-start" problem, enhancing fresh content distribution with a 15% Repin increase in organic content and 8.7% higher click for new Ads.
Visual Product Graph: Bridging Visual Products And Composite Images For End-to-End Style Recommendations
May 27, 2025



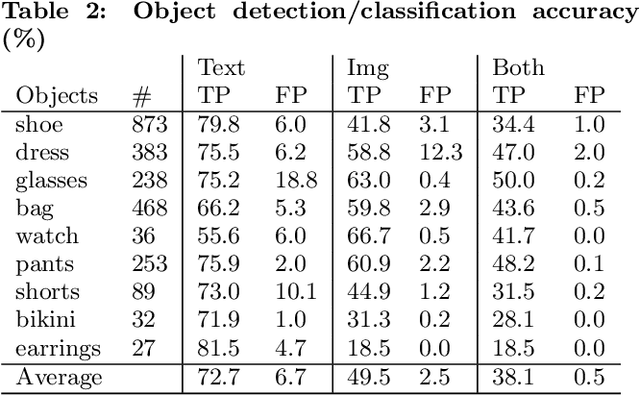
Retrieving semantically similar but visually distinct contents has been a critical capability in visual search systems. In this work, we aim to tackle this problem with Visual Product Graph (VPG), leveraging high-performance infrastructure for storage and state-of-the-art computer vision models for image understanding. VPG is built to be an online real-time retrieval system that enables navigation from individual products to composite scenes containing those products, along with complementary recommendations. Our system not only offers contextual insights by showcasing how products can be styled in a context, but also provides recommendations for complementary products drawn from these inspirations. We discuss the essential components for building the Visual Product Graph, along with the core computer vision model improvements across object detection, foundational visual embeddings, and other visual signals. Our system achieves a 78.8% extremely similar@1 in end-to-end human relevance evaluations, and a 6% module engagement rate. The "Ways to Style It" module, powered by the Visual Product Graph technology, is deployed in production at Pinterest.
Large-scale Reinforcement Learning for Diffusion Models
Jan 20, 2024Text-to-image diffusion models are a class of deep generative models that have demonstrated an impressive capacity for high-quality image generation. However, these models are susceptible to implicit biases that arise from web-scale text-image training pairs and may inaccurately model aspects of images we care about. This can result in suboptimal samples, model bias, and images that do not align with human ethics and preferences. In this paper, we present an effective scalable algorithm to improve diffusion models using Reinforcement Learning (RL) across a diverse set of reward functions, such as human preference, compositionality, and fairness over millions of images. We illustrate how our approach substantially outperforms existing methods for aligning diffusion models with human preferences. We further illustrate how this substantially improves pretrained Stable Diffusion (SD) models, generating samples that are preferred by humans 80.3% of the time over those from the base SD model while simultaneously improving both the composition and diversity of generated samples.
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
Aug 12, 2021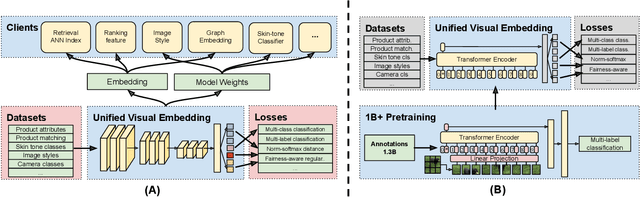


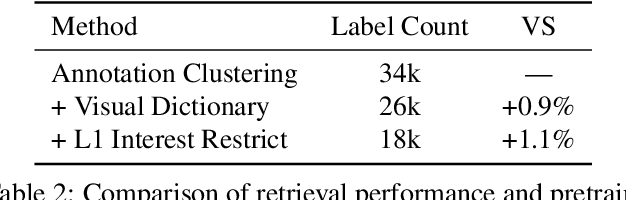
Large-scale pretraining of visual representations has led to state-of-the-art performance on a range of benchmark computer vision tasks, yet the benefits of these techniques at extreme scale in complex production systems has been relatively unexplored. We consider the case of a popular visual discovery product, where these representations are trained with multi-task learning, from use-case specific visual understanding (e.g. skin tone classification) to general representation learning for all visual content (e.g. embeddings for retrieval). In this work, we describe how we (1) generate a dataset with over a billion images via large weakly-supervised pretraining to improve the performance of these visual representations, and (2) leverage Transformers to replace the traditional convolutional backbone, with insights into both system and performance improvements, especially at 1B+ image scale. To support this backbone model, we detail a systematic approach to deriving weakly-supervised image annotations from heterogenous text signals, demonstrating the benefits of clustering techniques to handle the long-tail distribution of image labels. Through a comprehensive study of offline and online evaluation, we show that large-scale Transformer-based pretraining provides significant benefits to industry computer vision applications. The model is deployed in a production visual shopping system, with 36% improvement in top-1 relevance and 23% improvement in click-through volume. We conduct extensive experiments to better understand the empirical relationships between Transformer-based architectures, dataset scale, and the performance of production vision systems.
Toward Transformer-Based Object Detection
Dec 17, 2020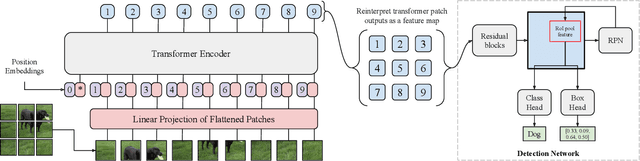
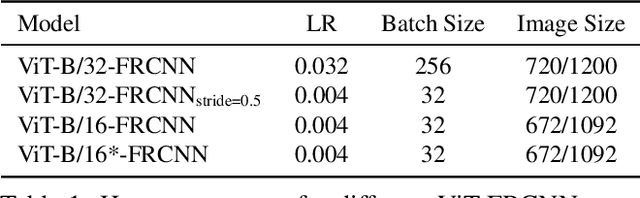
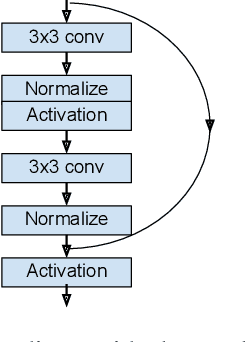
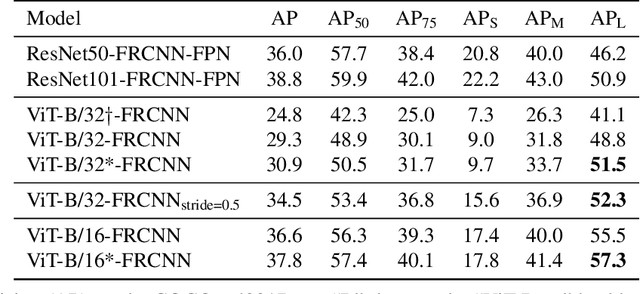
Transformers have become the dominant model in natural language processing, owing to their ability to pretrain on massive amounts of data, then transfer to smaller, more specific tasks via fine-tuning. The Vision Transformer was the first major attempt to apply a pure transformer model directly to images as input, demonstrating that as compared to convolutional networks, transformer-based architectures can achieve competitive results on benchmark classification tasks. However, the computational complexity of the attention operator means that we are limited to low-resolution inputs. For more complex tasks such as detection or segmentation, maintaining a high input resolution is crucial to ensure that models can properly identify and reflect fine details in their output. This naturally raises the question of whether or not transformer-based architectures such as the Vision Transformer are capable of performing tasks other than classification. In this paper, we determine that Vision Transformers can be used as a backbone by a common detection task head to produce competitive COCO results. The model that we propose, ViT-FRCNN, demonstrates several known properties associated with transformers, including large pretraining capacity and fast fine-tuning performance. We also investigate improvements over a standard detection backbone, including superior performance on out-of-domain images, better performance on large objects, and a lessened reliance on non-maximum suppression. We view ViT-FRCNN as an important stepping stone toward a pure-transformer solution of complex vision tasks such as object detection.
Visual Discovery at Pinterest
Mar 25, 2017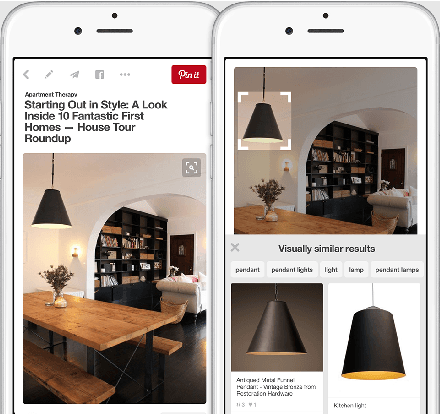
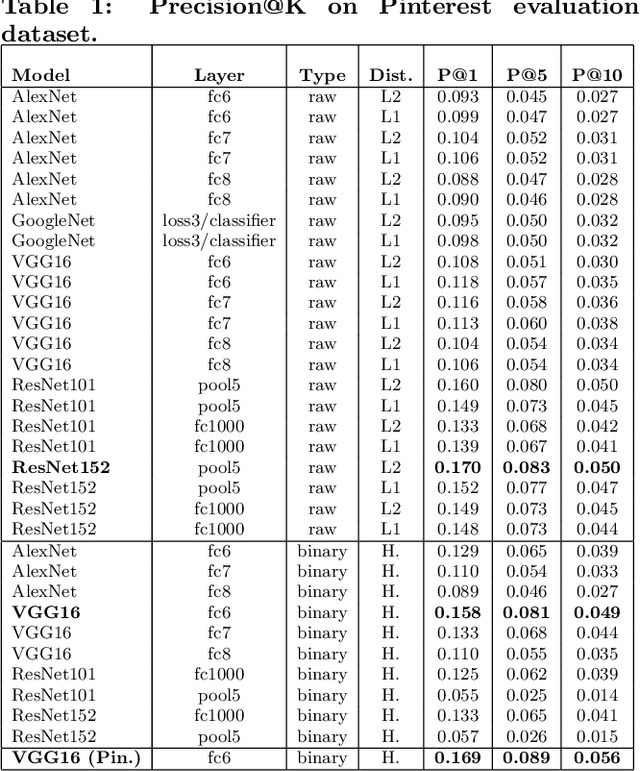
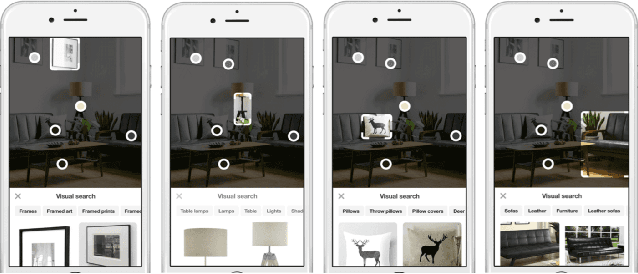
Over the past three years Pinterest has experimented with several visual search and recommendation services, including Related Pins (2014), Similar Looks (2015), Flashlight (2016) and Lens (2017). This paper presents an overview of our visual discovery engine powering these services, and shares the rationales behind our technical and product decisions such as the use of object detection and interactive user interfaces. We conclude that this visual discovery engine significantly improves engagement in both search and recommendation tasks.
Visual Search at Pinterest
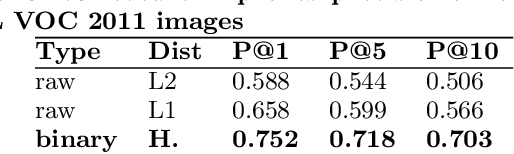
Mar 08, 2017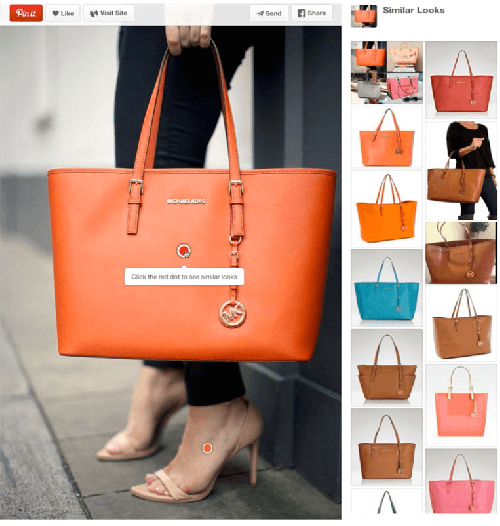
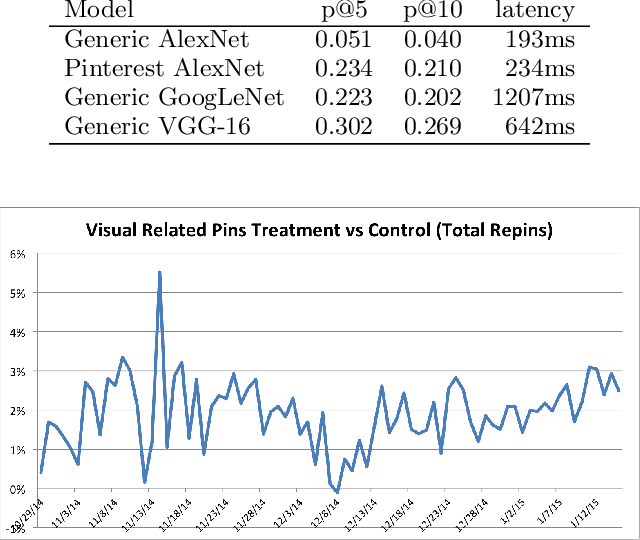
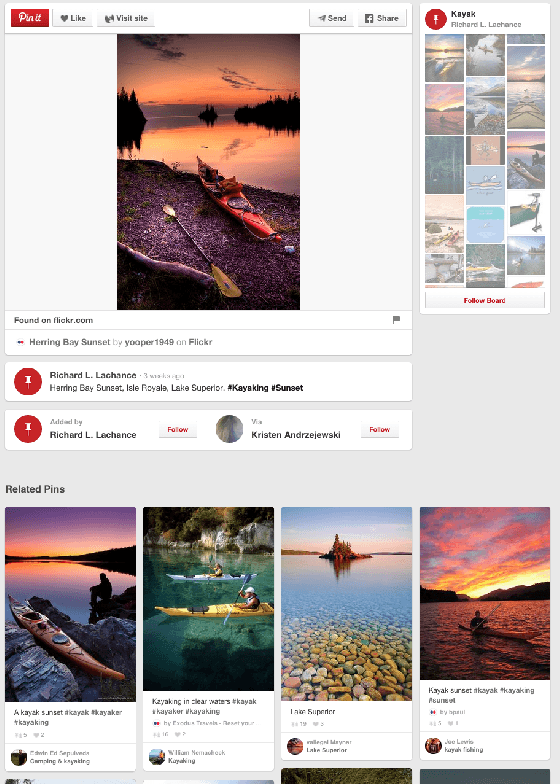
We demonstrate that, with the availability of distributed computation platforms such as Amazon Web Services and open-source tools, it is possible for a small engineering team to build, launch and maintain a cost-effective, large-scale visual search system with widely available tools. We also demonstrate, through a comprehensive set of live experiments at Pinterest, that content recommendation powered by visual search improve user engagement. By sharing our implementation details and the experiences learned from launching a commercial visual search engines from scratch, we hope visual search are more widely incorporated into today's commercial applications.
Human Curation and Convnets: Powering Item-to-Item Recommendations on Pinterest
Nov 12, 2015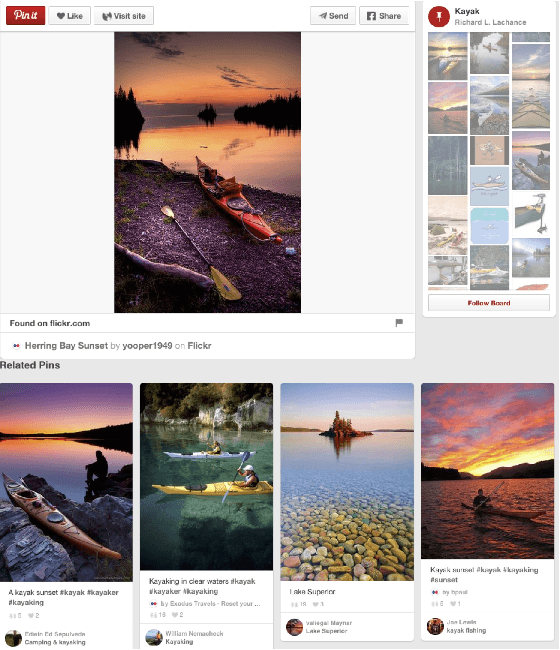
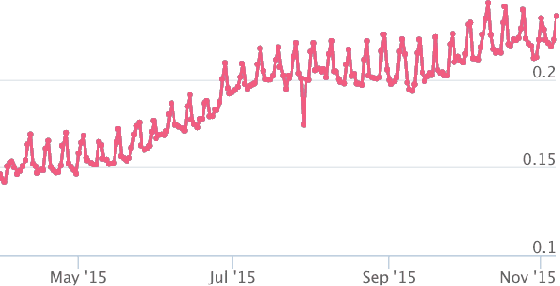
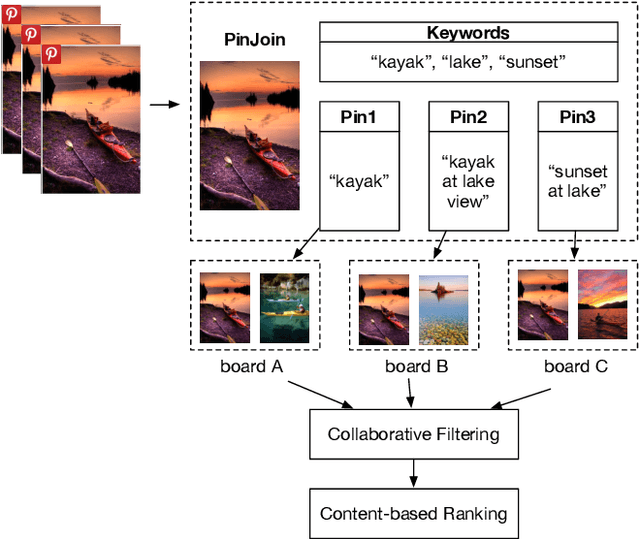

This paper presents Pinterest Related Pins, an item-to-item recommendation system that combines collaborative filtering with content-based ranking. We demonstrate that signals derived from user curation, the activity of users organizing content, are highly effective when used in conjunction with content-based ranking. This paper also demonstrates the effectiveness of visual features, such as image or object representations learned from convnets, in improving the user engagement rate of our item-to-item recommendation system.