 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePinPoint: Evaluation of Composed Image Retrieval with Explicit Negatives, Multi-Image Queries, and Paraphrase Testing
Mar 04, 2026Composed Image Retrieval (CIR) has made significant progress, yet current benchmarks are limited to single ground-truth answers and lack the annotations needed to evaluate false positive avoidance, robustness and multi-image reasoning. We present PinPoint, a comprehensive real world benchmark with 7,635 queries and 329K relevance judgments across 23 query categories. PinPoint advances the field by providing: (1) multiple correct answers (averaging 9.1 per query) (2) explicit hard negatives, (3) six instruction paraphrases per query for robustness testing, (4) multi-image composition support (13.4% of queries), and (5) demographic metadata for fairness evaluation. Based on our analysis of 20+ methods across 4 different major paradigms, we uncover three significant drawbacks: The best methods while achieving mAP@10 of 28.5%, still retrieves irrelevant results (hard negatives) 9% of the time. The best models also exhibit 25.1% performance variation across paraphrases, indicating significant potential for enhancing current CIR techniques. Multi-image queries performs 40 to 70% worse across different methods. To overcome these new issues uncovered by our evaluation framework, we propose a training-free reranking method based on an off-the-shelf MLLM that can be applied to any existing system to bridge the gap. We release the complete dataset, including all images, queries, annotations, retrieval index, and benchmarking code.
Visual Product Graph: Bridging Visual Products And Composite Images For End-to-End Style Recommendations
May 27, 2025



Retrieving semantically similar but visually distinct contents has been a critical capability in visual search systems. In this work, we aim to tackle this problem with Visual Product Graph (VPG), leveraging high-performance infrastructure for storage and state-of-the-art computer vision models for image understanding. VPG is built to be an online real-time retrieval system that enables navigation from individual products to composite scenes containing those products, along with complementary recommendations. Our system not only offers contextual insights by showcasing how products can be styled in a context, but also provides recommendations for complementary products drawn from these inspirations. We discuss the essential components for building the Visual Product Graph, along with the core computer vision model improvements across object detection, foundational visual embeddings, and other visual signals. Our system achieves a 78.8% extremely similar@1 in end-to-end human relevance evaluations, and a 6% module engagement rate. The "Ways to Style It" module, powered by the Visual Product Graph technology, is deployed in production at Pinterest.
Understanding Gender and Racial Disparities in Image Recognition Models
Jul 20, 2021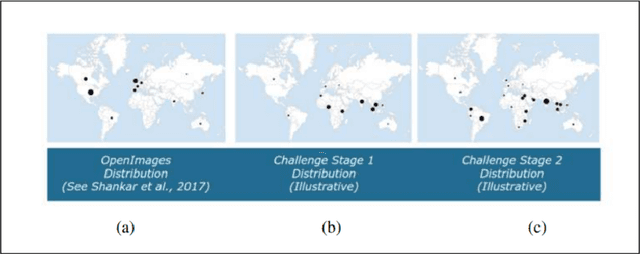
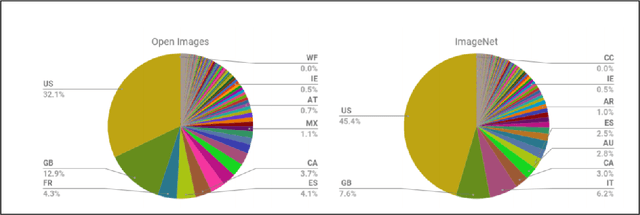


Large scale image classification models trained on top of popular datasets such as Imagenet have shown to have a distributional skew which leads to disparities in prediction accuracies across different subsections of population demographics. A lot of approaches have been made to solve for this distributional skew using methods that alter the model pre, post and during training. We investigate one such approach - which uses a multi-label softmax loss with cross-entropy as the loss function instead of a binary cross-entropy on a multi-label classification problem on the Inclusive Images dataset which is a subset of the OpenImages V6 dataset. We use the MR2 dataset, which contains images of people with self-identified gender and race attributes to evaluate the fairness in the model outcomes and try to interpret the mistakes by looking at model activations and suggest possible fixes.
Improving Visual Recognition using Ambient Sound for Supervision
Dec 25, 2019
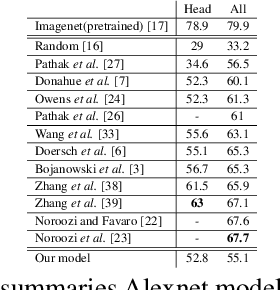

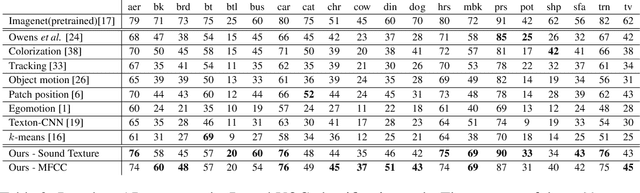
Our brains combine vision and hearing to create a more elaborate interpretation of the world. When the visual input is insufficient, a rich panoply of sounds can be used to describe our surroundings. Since more than 1,000 hours of videos are uploaded to the internet everyday, it is arduous, if not impossible, to manually annotate these videos. Therefore, incorporating audio along with visual data without annotations is crucial for leveraging this explosion of data for recognizing and understanding objects and scenes. Owens,et.al suggest that a rich representation of the physical world can be learned by using a convolutional neural network to predict sound textures associated with a given video frame. We attempt to reproduce the claims from their experiments, of which the code is not publicly available. In addition, we propose improvements in the pretext task that result in better performance in other downstream computer vision tasks.
Learning From Less Data: A Unified Data Subset Selection and Active Learning Framework for Computer Vision
Jan 03, 2019
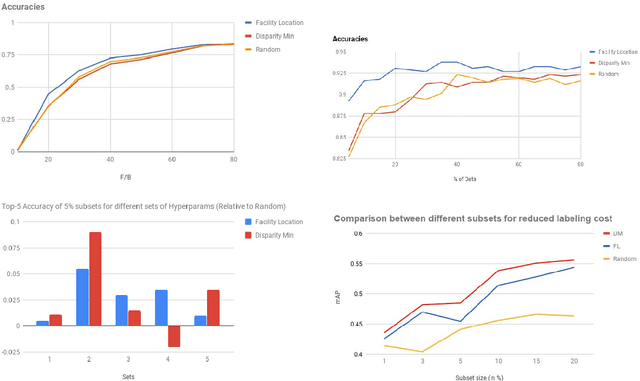
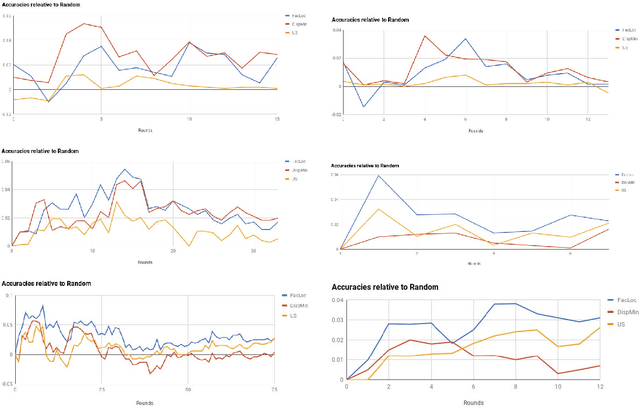
Supervised machine learning based state-of-the-art computer vision techniques are in general data hungry. Their data curation poses the challenges of expensive human labeling, inadequate computing resources and larger experiment turn around times. Training data subset selection and active learning techniques have been proposed as possible solutions to these challenges. A special class of subset selection functions naturally model notions of diversity, coverage and representation and can be used to eliminate redundancy thus lending themselves well for training data subset selection. They can also help improve the efficiency of active learning in further reducing human labeling efforts by selecting a subset of the examples obtained using the conventional uncertainty sampling based techniques. In this work, we empirically demonstrate the effectiveness of two diversity models, namely the Facility-Location and Dispersion models for training-data subset selection and reducing labeling effort. We demonstrate this across the board for a variety of computer vision tasks including Gender Recognition, Face Recognition, Scene Recognition, Object Detection and Object Recognition. Our results show that diversity based subset selection done in the right way can increase the accuracy by upto 5 - 10% over existing baselines, particularly in settings in which less training data is available. This allows the training of complex machine learning models like Convolutional Neural Networks with much less training data and labeling costs while incurring minimal performance loss.
Demystifying Multi-Faceted Video Summarization: Tradeoff Between Diversity,Representation, Coverage and Importance
Jan 03, 2019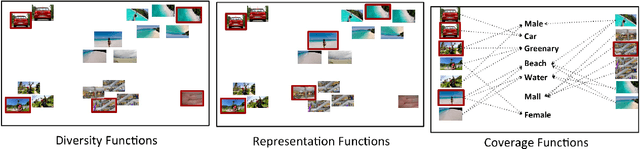

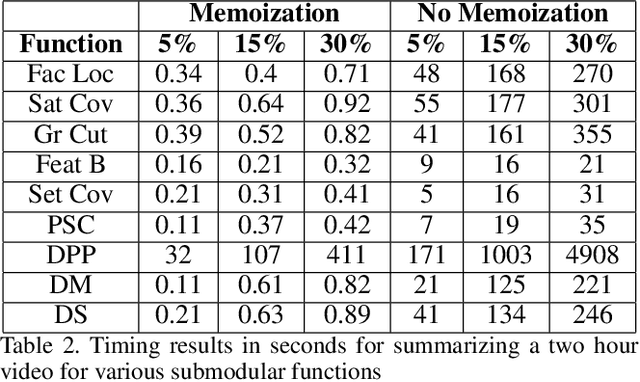

This paper addresses automatic summarization of videos in a unified manner. In particular, we propose a framework for multi-faceted summarization for extractive, query base and entity summarization (summarization at the level of entities like objects, scenes, humans and faces in the video). We investigate several summarization models which capture notions of diversity, coverage, representation and importance, and argue the utility of these different models depending on the application. While most of the prior work on submodular summarization approaches has focused oncombining several models and learning weighted mixtures, we focus on the explainability of different models and featurizations, and how they apply to different domains. We also provide implementation details on summarization systems and the different modalities involved. We hope that the study from this paper will give insights into practitioners to appropriately choose the right summarization models for the problems at hand.
Vis-DSS: An Open-Source toolkit for Visual Data Selection and Summarization
Sep 24, 2018

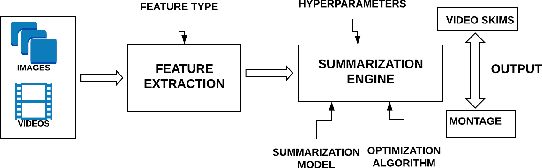
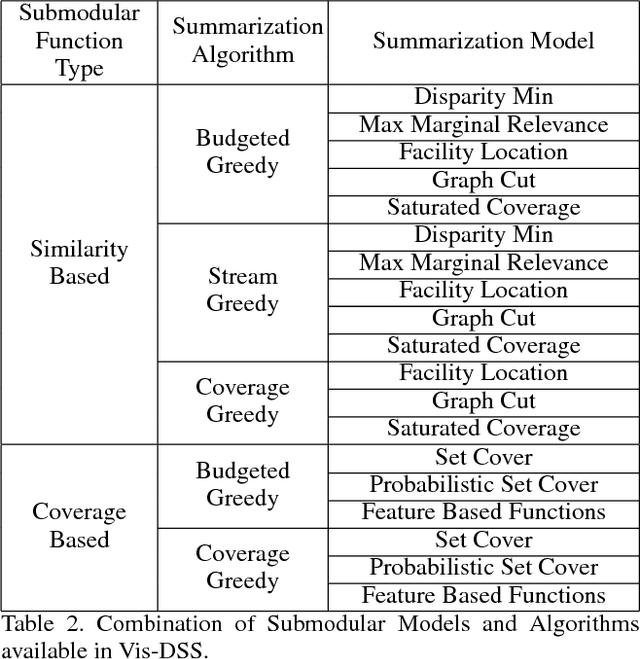
With increasing amounts of visual data being created in the form of videos and images, visual data selection and summarization are becoming ever increasing problems. We present Vis-DSS, an open-source toolkit for Visual Data Selection and Summarization. Vis-DSS implements a framework of models for summarization and data subset selection using submodular functions, which are becoming increasingly popular today for these problems. We present several classes of models, capturing notions of diversity, coverage, representation and importance, along with optimization/inference and learning algorithms. Vis-DSS is the first open source toolkit for several Data selection and summarization tasks including Image Collection Summarization, Video Summarization, Training Data selection for Classification and Diversified Active Learning. We demonstrate state-of-the art performance on all these tasks, and also show how we can scale to large problems. Vis-DSS allows easy integration for applications to be built on it, also can serve as a general skeleton that can be extended to several use cases, including video and image sharing platforms for creating GIFs, image montage creation, or as a component to surveillance systems and we demonstrate this by providing a graphical user-interface (GUI) desktop app built over Qt framework. Vis-DSS is available at https://github.com/rishabhk108/vis-dss
Deployment of Customized Deep Learning based Video Analytics On Surveillance Cameras
Jun 27, 2018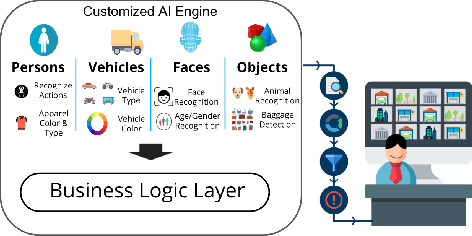
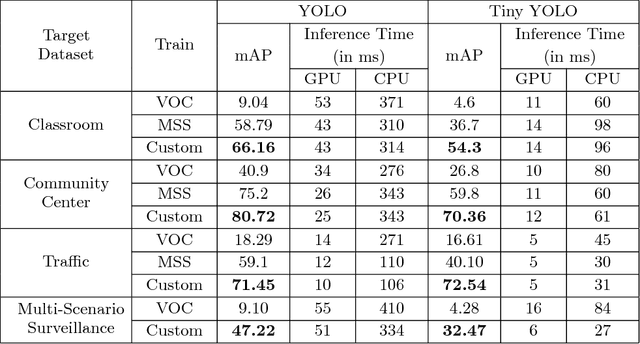

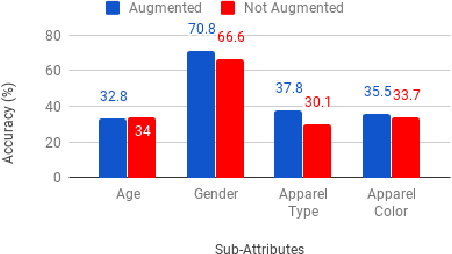
This paper demonstrates the effectiveness of our customized deep learning based video analytics system in various applications focused on security, safety, customer analytics and process compliance. We describe our video analytics system comprising of Search, Summarize, Statistics and real-time alerting, and outline its building blocks. These building blocks include object detection, tracking, face detection and recognition, human and face sub-attribute analytics. In each case, we demonstrate how custom models trained using data from the deployment scenarios provide considerably superior accuracies than off-the-shelf models. Towards this end, we describe our data processing and model training pipeline, which can train and fine-tune models from videos with a quick turnaround time. Finally, since most of these models are deployed on-site, it is important to have resource constrained models which do not require GPUs. We demonstrate how we custom train resource constrained models and deploy them on embedded devices without significant loss in accuracy. To our knowledge, this is the first work which provides a comprehensive evaluation of different deep learning models on various real-world customer deployment scenarios of surveillance video analytics. By sharing our implementation details and the experiences learned from deploying customized deep learning models for various customers, we hope that customized deep learning based video analytics is widely incorporated in commercial products around the world.
Multi-Language Identification Using Convolutional Recurrent Neural Network
May 18, 2017
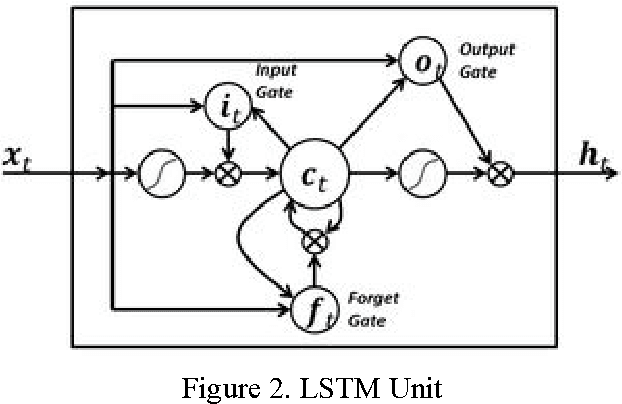
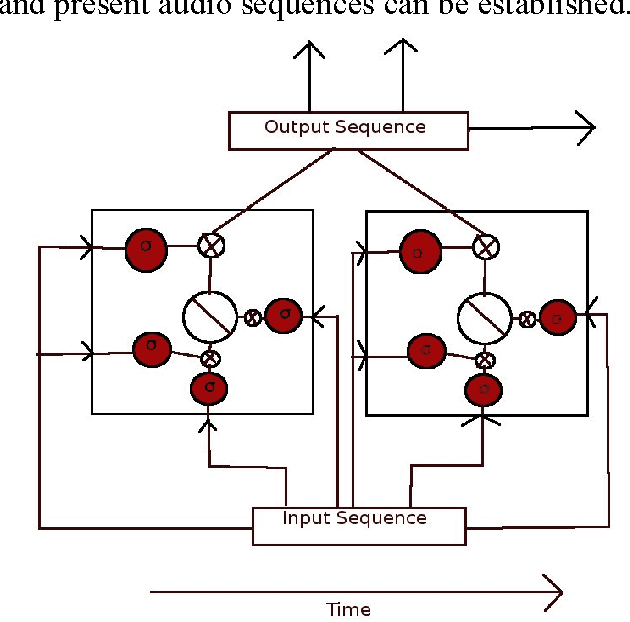
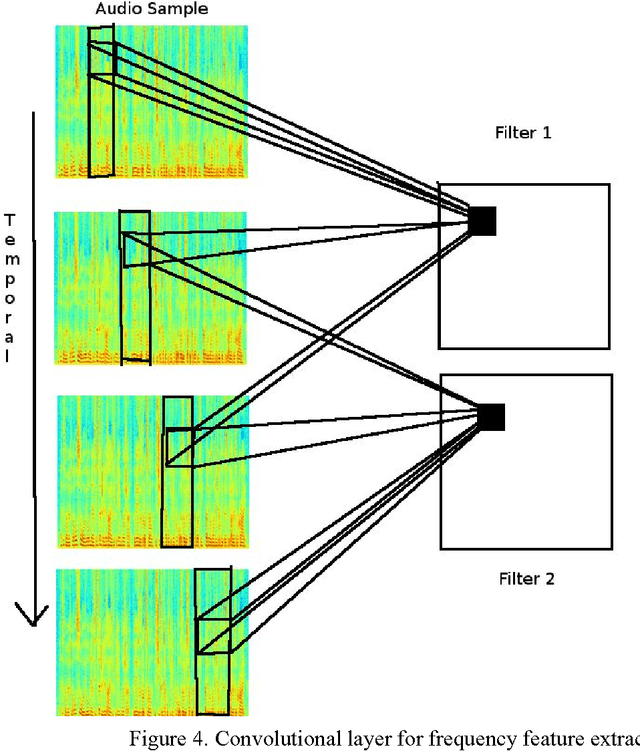
Language Identification, being an important aspect of Automatic Speaker Recognition has had many changes and new approaches to ameliorate performance over the last decade. We compare the performance of using audio spectrum in the log scale and using Polyphonic sound sequences from raw audio samples to train the neural network and to classify speech as either English or Spanish. To achieve this, we use the novel approach of using a Convolutional Recurrent Neural Network using Long Short Term Memory (LSTM) or a Gated Recurrent Unit (GRU) for forward propagation of the neural network. Our hypothesis is that the performance of using polyphonic sound sequence as features and both LSTM and GRU as the gating mechanisms for the neural network outperform the traditional MFCC features using a unidirectional Deep Neural Network.