 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Multi-Faceted Video Summarization: Tradeoff Between Diversity,Representation, Coverage and Importance
Jan 03, 2019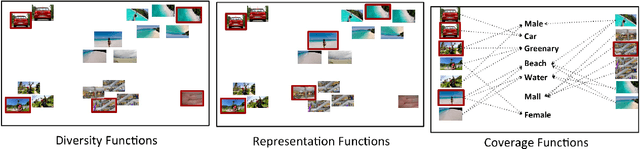


This paper addresses automatic summarization of videos in a unified manner. In particular, we propose a framework for multi-faceted summarization for extractive, query base and entity summarization (summarization at the level of entities like objects, scenes, humans and faces in the video). We investigate several summarization models which capture notions of diversity, coverage, representation and importance, and argue the utility of these different models depending on the application. While most of the prior work on submodular summarization approaches has focused oncombining several models and learning weighted mixtures, we focus on the explainability of different models and featurizations, and how they apply to different domains. We also provide implementation details on summarization systems and the different modalities involved. We hope that the study from this paper will give insights into practitioners to appropriately choose the right summarization models for the problems at hand.
Learning From Less Data: Diversified Subset Selection and Active Learning in Image Classification Tasks
May 28, 2018
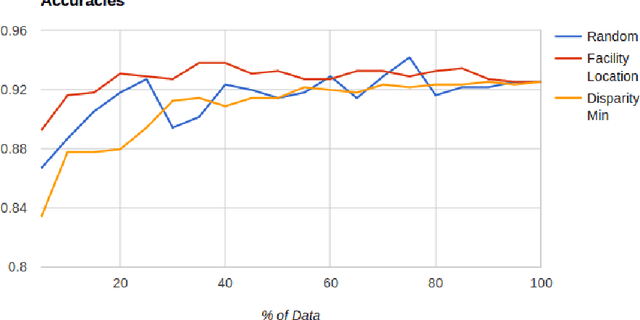
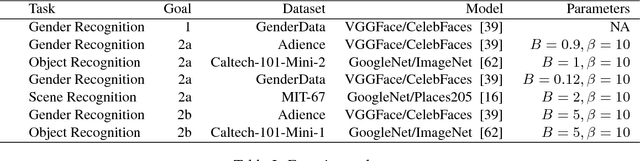
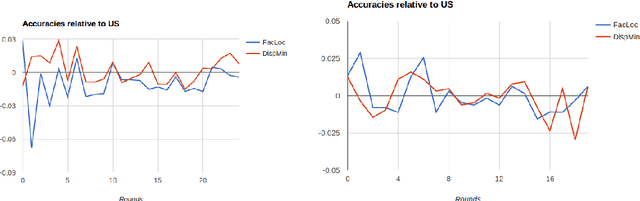
Supervised machine learning based state-of-the-art computer vision techniques are in general data hungry and pose the challenges of not having adequate computing resources and of high costs involved in human labeling efforts. Training data subset selection and active learning techniques have been proposed as possible solutions to these challenges respectively. A special class of subset selection functions naturally model notions of diversity, coverage and representation and they can be used to eliminate redundancy and thus lend themselves well for training data subset selection. They can also help improve the efficiency of active learning in further reducing human labeling efforts by selecting a subset of the examples obtained using the conventional uncertainty sampling based techniques. In this work we empirically demonstrate the effectiveness of two diversity models, namely the Facility-Location and Disparity-Min models for training-data subset selection and reducing labeling effort. We do this for a variety of computer vision tasks including Gender Recognition, Scene Recognition and Object Recognition. Our results show that subset selection done in the right way can add 2-3% in accuracy on existing baselines, particularly in the case of less training data. This allows the training of complex machine learning models (like Convolutional Neural Networks) with much less training data while incurring minimal performance loss.
A Unified Multi-Faceted Video Summarization System
Apr 04, 2017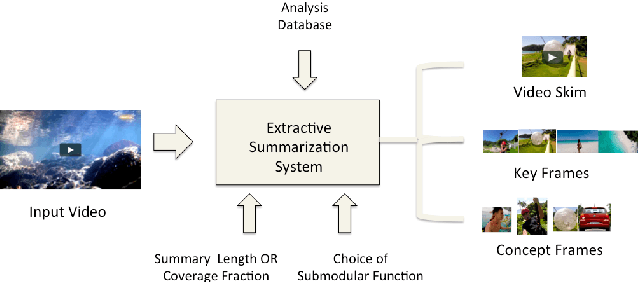

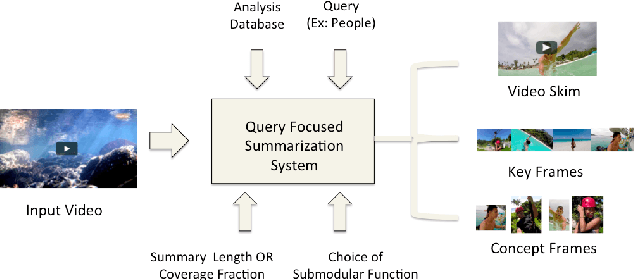

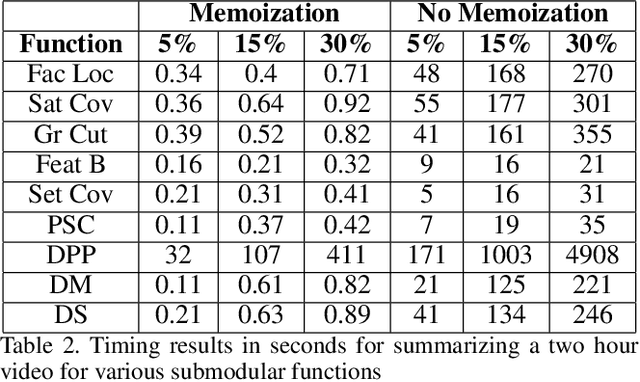
This paper addresses automatic summarization and search in visual data comprising of videos, live streams and image collections in a unified manner. In particular, we propose a framework for multi-faceted summarization which extracts key-frames (image summaries), skims (video summaries) and entity summaries (summarization at the level of entities like objects, scenes, humans and faces in the video). The user can either view these as extractive summarization, or query focused summarization. Our approach first pre-processes the video or image collection once, to extract all important visual features, following which we provide an interactive mechanism to the user to summarize the video based on their choice. We investigate several diversity, coverage and representation models for all these problems, and argue the utility of these different mod- els depending on the application. While most of the prior work on submodular summarization approaches has focused on combining several models and learning weighted mixtures, we focus on the explain-ability of different the diversity, coverage and representation models and their scalability. Most importantly, we also show that we can summarize hours of video data in a few seconds, and our system allows the user to generate summaries of various lengths and types interactively on the fly.