 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmodlib: A Submodular Optimization Library
Feb 23, 2022
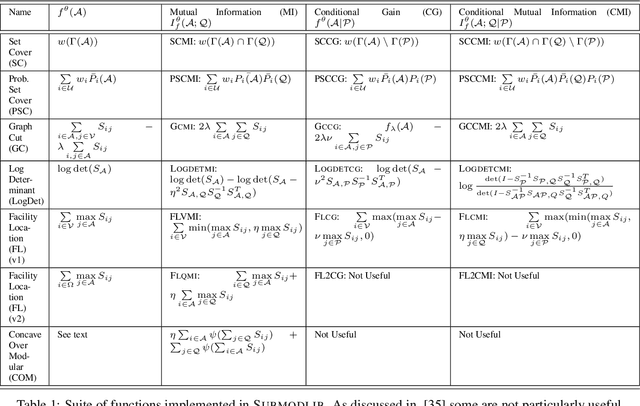

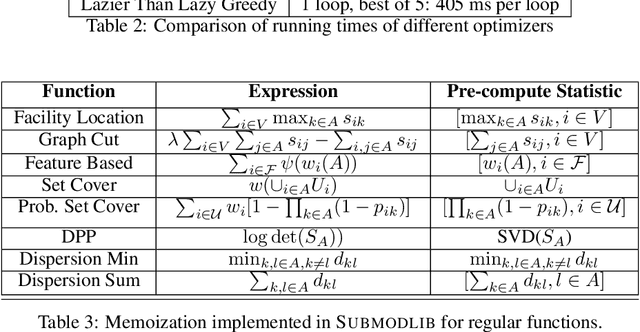
Submodular functions are a special class of set functions which naturally model the notion of representativeness, diversity, coverage etc. and have been shown to be computationally very efficient. A lot of past work has applied submodular optimization to find optimal subsets in various contexts. Some examples include data summarization for efficient human consumption, finding effective smaller subsets of training data to reduce the model development time (training, hyper parameter tuning), finding effective subsets of unlabeled data to reduce the labeling costs, etc. A recent work has also leveraged submodular functions to propose submodular information measures which have been found to be very useful in solving the problems of guided subset selection and guided summarization. In this work, we present Submodlib which is an open-source, easy-to-use, efficient and scalable Python library for submodular optimization with a C++ optimization engine. Submodlib finds its application in summarization, data subset selection, hyper parameter tuning, efficient training and more. Through a rich API, it offers a great deal of flexibility in the way it can be used. Source of Submodlib is available at https://github.com/decile-team/submodlib.
Submodular Mutual Information for Targeted Data Subset Selection
Apr 30, 2021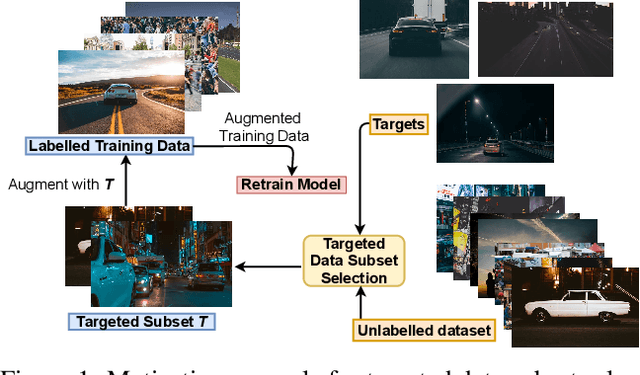
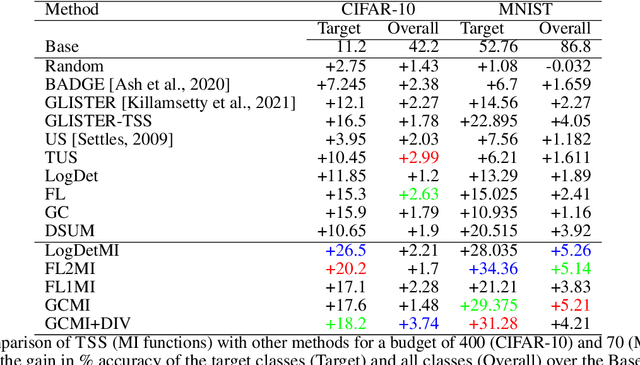
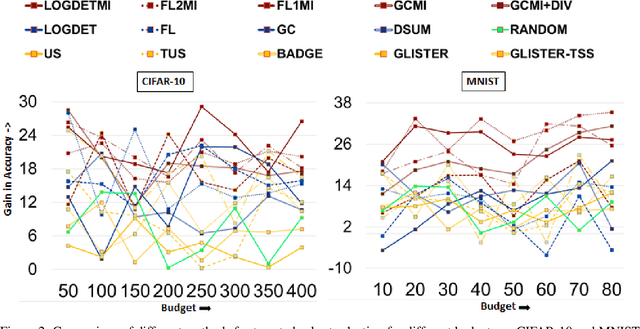
With the rapid growth of data, it is becoming increasingly difficult to train or improve deep learning models with the right subset of data. We show that this problem can be effectively solved at an additional labeling cost by targeted data subset selection(TSS) where a subset of unlabeled data points similar to an auxiliary set are added to the training data. We do so by using a rich class of Submodular Mutual Information (SMI) functions and demonstrate its effectiveness for image classification on CIFAR-10 and MNIST datasets. Lastly, we compare the performance of SMI functions for TSS with other state-of-the-art methods for closely related problems like active learning. Using SMI functions, we observe ~20-30% gain over the model's performance before re-training with added targeted subset; ~12% more than other methods.
PRISM: A Unified Framework of Parameterized Submodular Information Measures for Targeted Data Subset Selection and Summarization
Feb 27, 2021

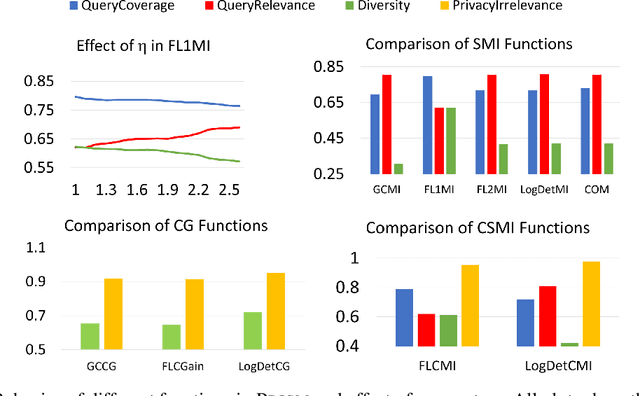
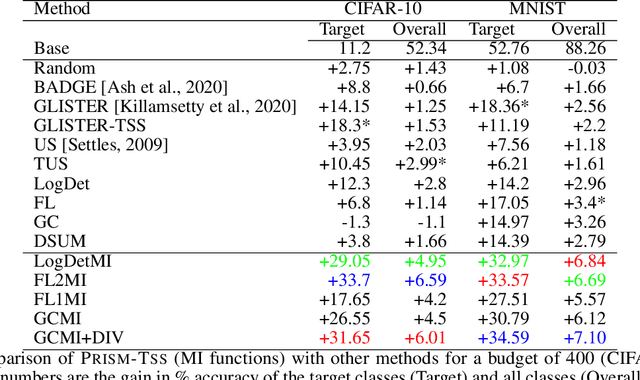
With increasing data, techniques for finding smaller, yet effective subsets with specific characteristics become important. Motivated by this, we present PRISM, a rich class of Parameterized Submodular Information Measures, that can be used in applications where such targeted subsets are desired. We demonstrate the utility of PRISM in two such applications. First, we apply PRISM to improve a supervised model's performance at a given additional labeling cost by targeted subset selection (PRISM-TSS) where a subset of unlabeled points matching a target set are added to the training set. We show that PRISM-TSS generalizes and is connected to several existing approaches to targeted data subset selection. Second, we apply PRISM to a more nuanced targeted summarization (PRISM-TSUM) where data (e.g., image collections, text or videos) is summarized for quicker human consumption with additional user intent. PRISM-TSUM handles multiple flavors of targeted summarization such as query-focused, topic-irrelevant, privacy-preserving and update summarization in a unified way. We show that PRISM-TSUM also generalizes and unifies several existing past work on targeted summarization. Through extensive experiments on image classification and image-collection summarization we empirically verify the superiority of PRISM-TSS and PRISM-TSUM over the state-of-the-art.
How Good is a Video Summary? A New Benchmarking Dataset and Evaluation Framework Towards Realistic Video Summarization
Jan 26, 2021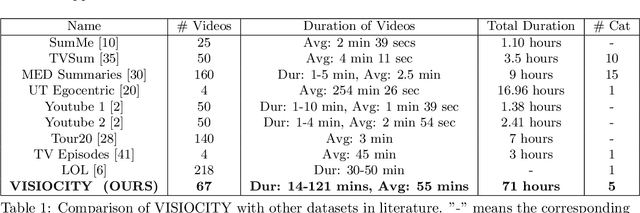
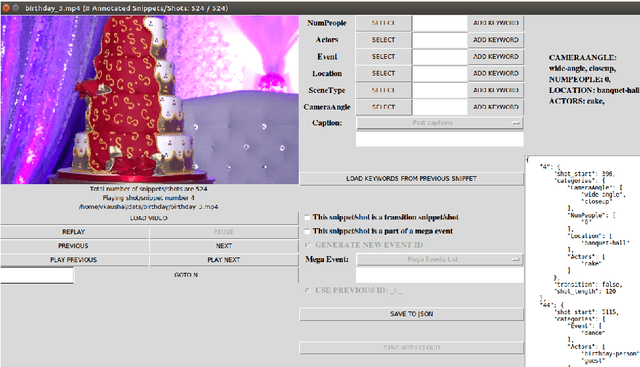
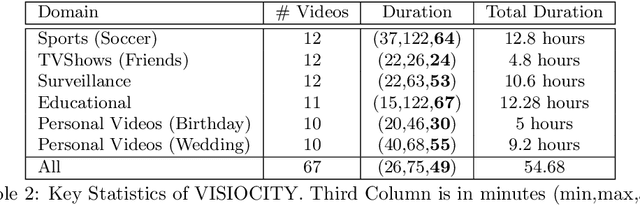
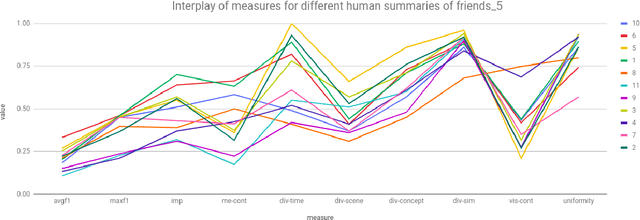
Automatic video summarization is still an unsolved problem due to several challenges. The currently available datasets either have very short videos or have few long videos of only a particular type. We introduce a new benchmarking video dataset called VISIOCITY (VIdeo SummarIzatiOn based on Continuity, Intent and DiversiTY) which comprises of longer videos across six different categories with dense concept annotations capable of supporting different flavors of video summarization and other vision problems. For long videos, human reference summaries necessary for supervised video summarization techniques are difficult to obtain. We explore strategies to automatically generate multiple reference summaries from indirect ground truth present in VISIOCITY. We show that these summaries are at par with human summaries. We also present a study of different desired characteristics of a good summary and demonstrate how it is normal to have two good summaries with different characteristics. Thus we argue that evaluating a summary against one or more human summaries and using a single measure has its shortcomings. We propose an evaluation framework for better quantitative assessment of summary quality which is closer to human judgment. Lastly, we present insights into how a model can be enhanced to yield better summaries. Sepcifically, when multiple diverse ground truth summaries can exist, learning from them individually and using a combination of loss functions measuring different characteristics is better than learning from a single combined (oracle) ground truth summary using a single loss function. We demonstrate the effectiveness of doing so as compared to some of the representative state of the art techniques tested on VISIOCITY. We release VISIOCITY as a benchmarking dataset and invite researchers to test the effectiveness of their video summarization algorithms on VISIOCITY.
A Unified Framework for Generic, Query-Focused, Privacy Preserving and Update Summarization using Submodular Information Measures
Oct 12, 2020
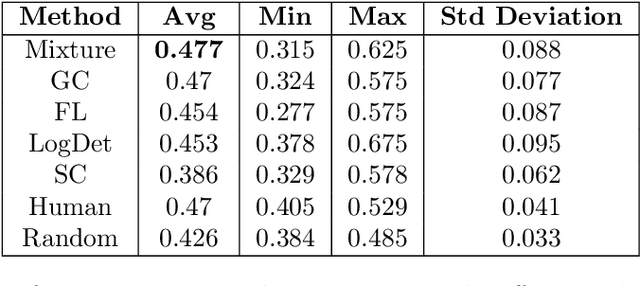
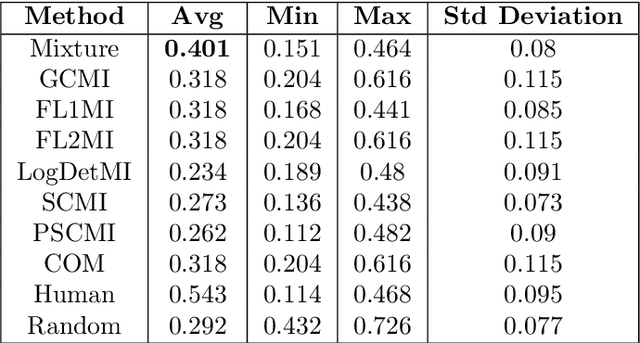
We study submodular information measures as a rich framework for generic, query-focused, privacy sensitive, and update summarization tasks. While past work generally treats these problems differently ({\em e.g.}, different models are often used for generic and query-focused summarization), the submodular information measures allow us to study each of these problems via a unified approach. We first show that several previous query-focused and update summarization techniques have, unknowingly, used various instantiations of the aforesaid submodular information measures, providing evidence for the benefit and naturalness of these models. We then carefully study and demonstrate the modelling capabilities of the proposed functions in different settings and empirically verify our findings on both a synthetic dataset and an existing real-world image collection dataset (that has been extended by adding concept annotations to each image making it suitable for this task) and will be publicly released. We employ a max-margin framework to learn a mixture model built using the proposed instantiations of submodular information measures and demonstrate the effectiveness of our approach. While our experiments are in the context of image summarization, our framework is generic and can be easily extended to other summarization settings (e.g., videos or documents).
Realistic Video Summarization through VISIOCITY: A New Benchmark and Evaluation Framework
Aug 25, 2020
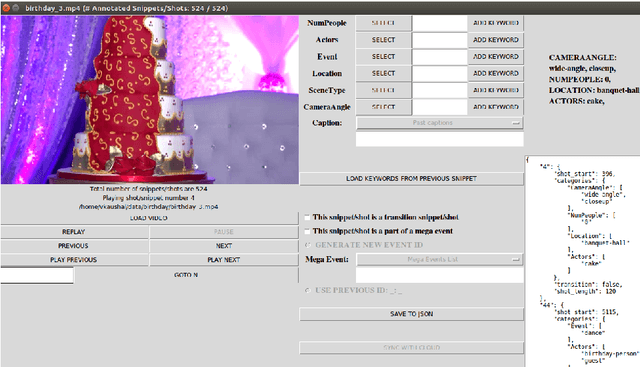
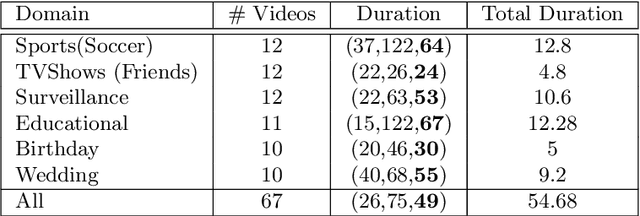
Automatic video summarization is still an unsolved problem due to several challenges. We take steps towards making automatic video summarization more realistic by addressing them. Firstly, the currently available datasets either have very short videos or have few long videos of only a particular type. We introduce a new benchmarking dataset VISIOCITY which comprises of longer videos across six different categories with dense concept annotations capable of supporting different flavors of video summarization and can be used for other vision problems. Secondly, for long videos, human reference summaries are difficult to obtain. We present a novel recipe based on pareto optimality to automatically generate multiple reference summaries from indirect ground truth present in VISIOCITY. We show that these summaries are at par with human summaries. Thirdly, we demonstrate that in the presence of multiple ground truth summaries (due to the highly subjective nature of the task), learning from a single combined ground truth summary using a single loss function is not a good idea. We propose a simple recipe VISIOCITY-SUM to enhance an existing model using a combination of losses and demonstrate that it beats the current state of the art techniques when tested on VISIOCITY. We also show that a single measure to evaluate a summary, as is the current typical practice, falls short. We propose a framework for better quantitative assessment of summary quality which is closer to human judgment than a single measure, say F1. We report the performance of a few representative techniques of video summarization on VISIOCITY assessed using various measures and bring out the limitation of the techniques and/or the assessment mechanism in modeling human judgment and demonstrate the effectiveness of our evaluation framework in doing so.
Learning From Less Data: A Unified Data Subset Selection and Active Learning Framework for Computer Vision
Jan 03, 2019
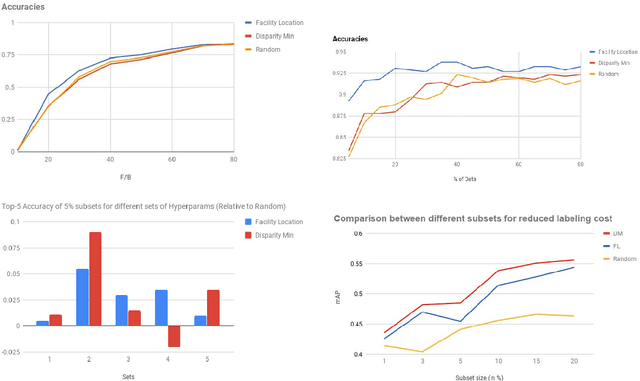
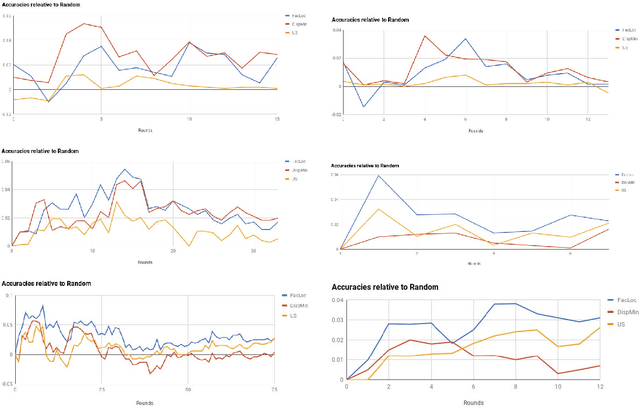
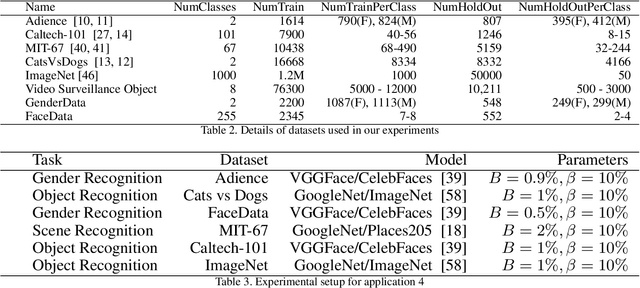
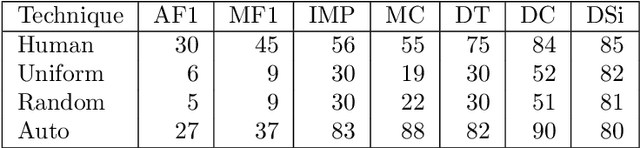
Supervised machine learning based state-of-the-art computer vision techniques are in general data hungry. Their data curation poses the challenges of expensive human labeling, inadequate computing resources and larger experiment turn around times. Training data subset selection and active learning techniques have been proposed as possible solutions to these challenges. A special class of subset selection functions naturally model notions of diversity, coverage and representation and can be used to eliminate redundancy thus lending themselves well for training data subset selection. They can also help improve the efficiency of active learning in further reducing human labeling efforts by selecting a subset of the examples obtained using the conventional uncertainty sampling based techniques. In this work, we empirically demonstrate the effectiveness of two diversity models, namely the Facility-Location and Dispersion models for training-data subset selection and reducing labeling effort. We demonstrate this across the board for a variety of computer vision tasks including Gender Recognition, Face Recognition, Scene Recognition, Object Detection and Object Recognition. Our results show that diversity based subset selection done in the right way can increase the accuracy by upto 5 - 10% over existing baselines, particularly in settings in which less training data is available. This allows the training of complex machine learning models like Convolutional Neural Networks with much less training data and labeling costs while incurring minimal performance loss.
Demystifying Multi-Faceted Video Summarization: Tradeoff Between Diversity,Representation, Coverage and Importance
Jan 03, 2019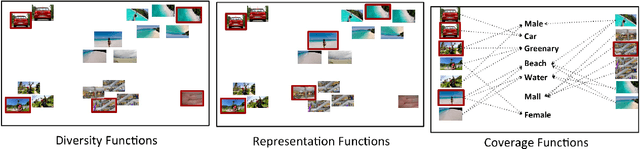


This paper addresses automatic summarization of videos in a unified manner. In particular, we propose a framework for multi-faceted summarization for extractive, query base and entity summarization (summarization at the level of entities like objects, scenes, humans and faces in the video). We investigate several summarization models which capture notions of diversity, coverage, representation and importance, and argue the utility of these different models depending on the application. While most of the prior work on submodular summarization approaches has focused oncombining several models and learning weighted mixtures, we focus on the explainability of different models and featurizations, and how they apply to different domains. We also provide implementation details on summarization systems and the different modalities involved. We hope that the study from this paper will give insights into practitioners to appropriately choose the right summarization models for the problems at hand.
A Framework towards Domain Specific Video Summarization
Sep 24, 2018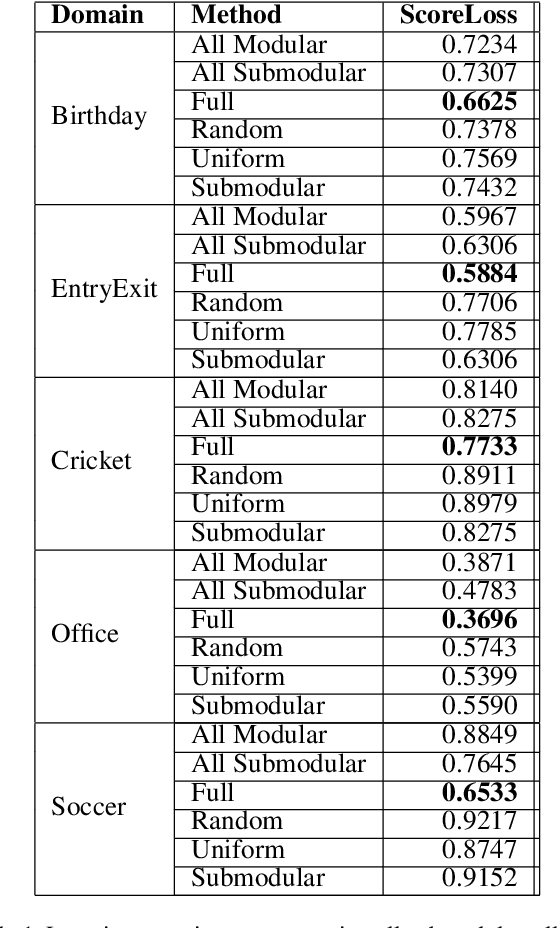
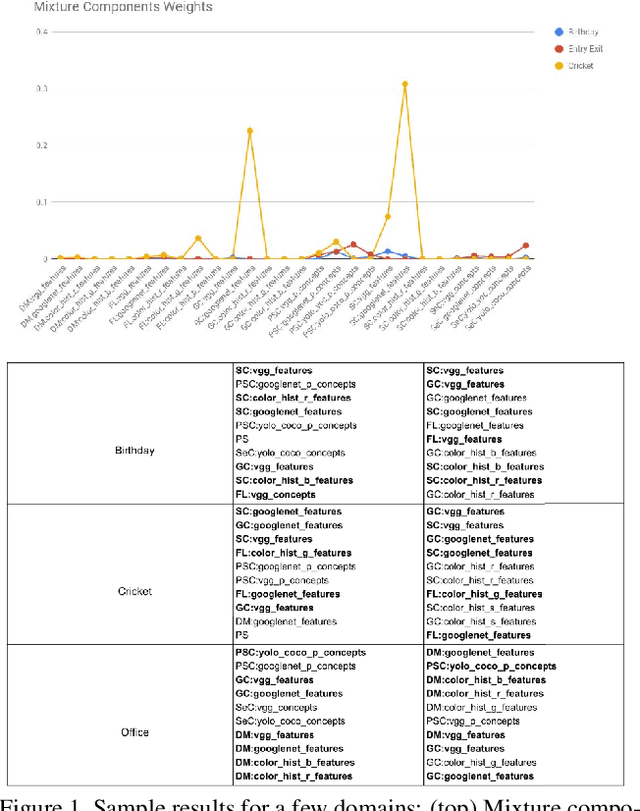


In the light of exponentially increasing video content, video summarization has attracted a lot of attention recently due to its ability to optimize time and storage. Characteristics of a good summary of a video depend on the particular domain under question. We propose a novel framework for domain specific video summarization. Given a video of a particular domain, our system can produce a summary based on what is important for that domain in addition to possessing other desired characteristics like representativeness, coverage, diversity etc. as suitable to that domain. Past related work has focused either on using supervised approaches for ranking the snippets to produce summary or on using unsupervised approaches of generating the summary as a subset of snippets with the above characteristics. We look at the joint problem of learning domain specific importance of segments as well as the desired summary characteristic for that domain. Our studies show that the more efficient way of incorporating domain specific relevances into a summary is by obtaining ratings of shots as opposed to binary inclusion/exclusion information. We also argue that ratings can be seen as unified representation of all possible ground truth summaries of a video, taking us one step closer in dealing with challenges associated with multiple ground truth summaries of a video. We also propose a novel evaluation measure which is more naturally suited in assessing the quality of video summary for the task at hand than F1 like measures. It leverages the ratings information and is richer in appropriately modeling desirable and undesirable characteristics of a summary. Lastly, we release a gold standard dataset for furthering research in domain specific video summarization, which to our knowledge is the first dataset with long videos across several domains with rating annotations.
Vis-DSS: An Open-Source toolkit for Visual Data Selection and Summarization
Sep 24, 2018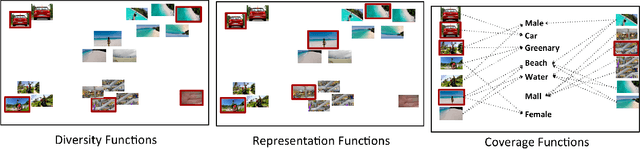

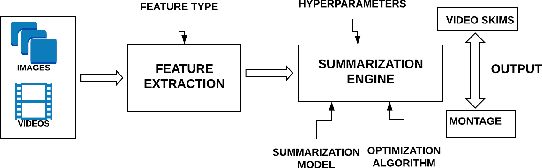
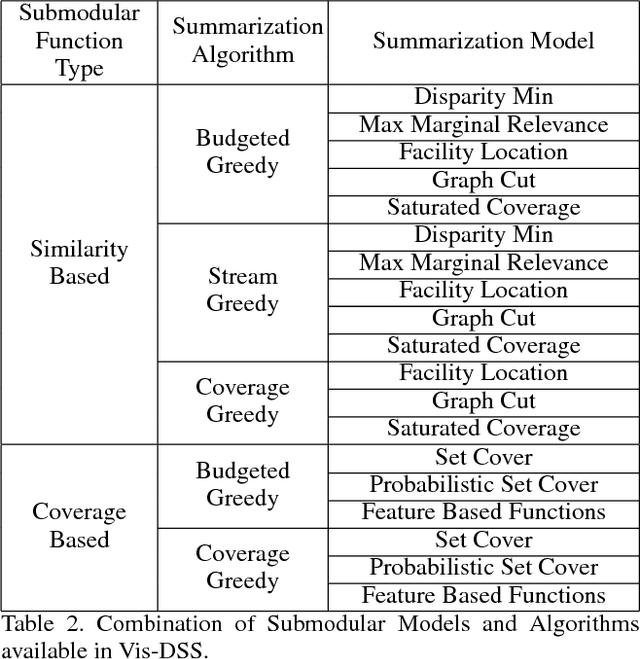
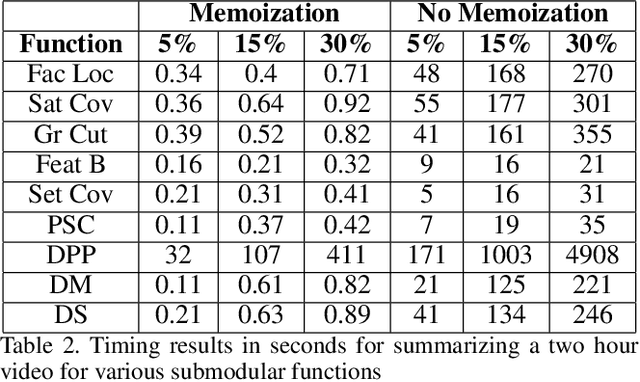
With increasing amounts of visual data being created in the form of videos and images, visual data selection and summarization are becoming ever increasing problems. We present Vis-DSS, an open-source toolkit for Visual Data Selection and Summarization. Vis-DSS implements a framework of models for summarization and data subset selection using submodular functions, which are becoming increasingly popular today for these problems. We present several classes of models, capturing notions of diversity, coverage, representation and importance, along with optimization/inference and learning algorithms. Vis-DSS is the first open source toolkit for several Data selection and summarization tasks including Image Collection Summarization, Video Summarization, Training Data selection for Classification and Diversified Active Learning. We demonstrate state-of-the art performance on all these tasks, and also show how we can scale to large problems. Vis-DSS allows easy integration for applications to be built on it, also can serve as a general skeleton that can be extended to several use cases, including video and image sharing platforms for creating GIFs, image montage creation, or as a component to surveillance systems and we demonstrate this by providing a graphical user-interface (GUI) desktop app built over Qt framework. Vis-DSS is available at https://github.com/rishabhk108/vis-dss