 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Demystifying Multi-Faceted Video Summarization: Tradeoff Between Diversity,Representation, Coverage and Importance
Jan 03, 2019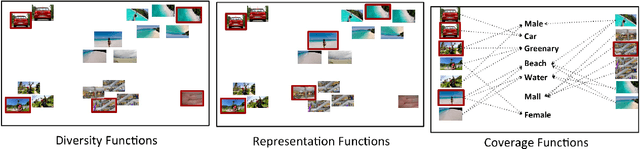

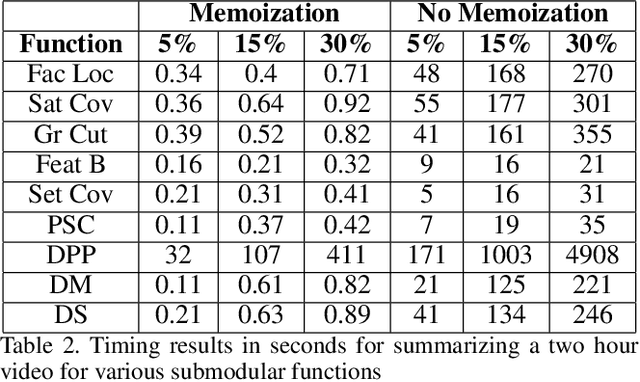

This paper addresses automatic summarization of videos in a unified manner. In particular, we propose a framework for multi-faceted summarization for extractive, query base and entity summarization (summarization at the level of entities like objects, scenes, humans and faces in the video). We investigate several summarization models which capture notions of diversity, coverage, representation and importance, and argue the utility of these different models depending on the application. While most of the prior work on submodular summarization approaches has focused oncombining several models and learning weighted mixtures, we focus on the explainability of different models and featurizations, and how they apply to different domains. We also provide implementation details on summarization systems and the different modalities involved. We hope that the study from this paper will give insights into practitioners to appropriately choose the right summarization models for the problems at hand.
Vis-DSS: An Open-Source toolkit for Visual Data Selection and Summarization
Sep 24, 2018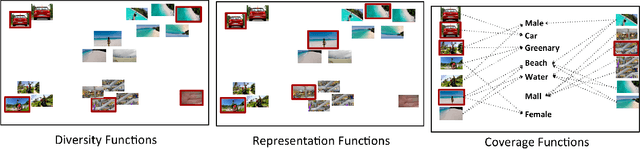

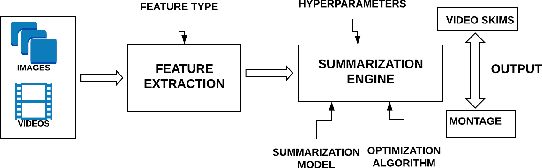
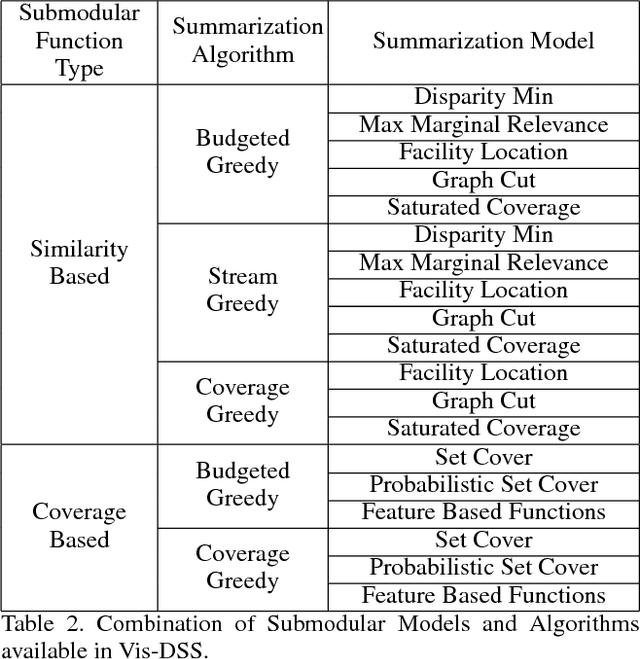
With increasing amounts of visual data being created in the form of videos and images, visual data selection and summarization are becoming ever increasing problems. We present Vis-DSS, an open-source toolkit for Visual Data Selection and Summarization. Vis-DSS implements a framework of models for summarization and data subset selection using submodular functions, which are becoming increasingly popular today for these problems. We present several classes of models, capturing notions of diversity, coverage, representation and importance, along with optimization/inference and learning algorithms. Vis-DSS is the first open source toolkit for several Data selection and summarization tasks including Image Collection Summarization, Video Summarization, Training Data selection for Classification and Diversified Active Learning. We demonstrate state-of-the art performance on all these tasks, and also show how we can scale to large problems. Vis-DSS allows easy integration for applications to be built on it, also can serve as a general skeleton that can be extended to several use cases, including video and image sharing platforms for creating GIFs, image montage creation, or as a component to surveillance systems and we demonstrate this by providing a graphical user-interface (GUI) desktop app built over Qt framework. Vis-DSS is available at https://github.com/rishabhk108/vis-dss
Deployment of Customized Deep Learning based Video Analytics On Surveillance Cameras
Jun 27, 2018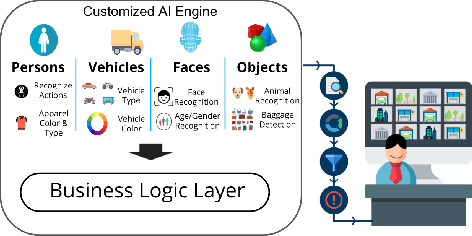
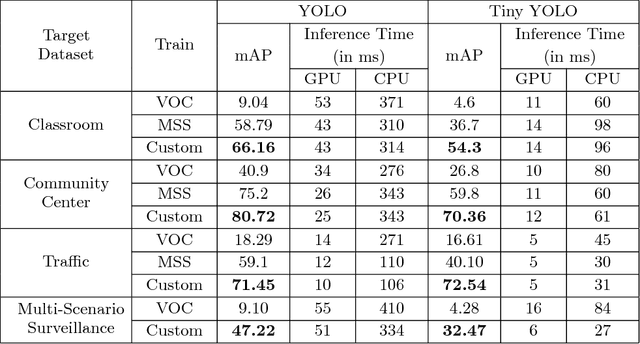

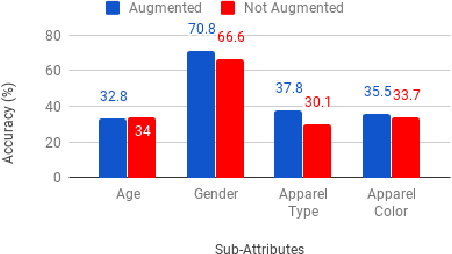
This paper demonstrates the effectiveness of our customized deep learning based video analytics system in various applications focused on security, safety, customer analytics and process compliance. We describe our video analytics system comprising of Search, Summarize, Statistics and real-time alerting, and outline its building blocks. These building blocks include object detection, tracking, face detection and recognition, human and face sub-attribute analytics. In each case, we demonstrate how custom models trained using data from the deployment scenarios provide considerably superior accuracies than off-the-shelf models. Towards this end, we describe our data processing and model training pipeline, which can train and fine-tune models from videos with a quick turnaround time. Finally, since most of these models are deployed on-site, it is important to have resource constrained models which do not require GPUs. We demonstrate how we custom train resource constrained models and deploy them on embedded devices without significant loss in accuracy. To our knowledge, this is the first work which provides a comprehensive evaluation of different deep learning models on various real-world customer deployment scenarios of surveillance video analytics. By sharing our implementation details and the experiences learned from deploying customized deep learning models for various customers, we hope that customized deep learning based video analytics is widely incorporated in commercial products around the world.