 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Coarse-to-fine Optimization for Speech Enhancement
Aug 21, 2019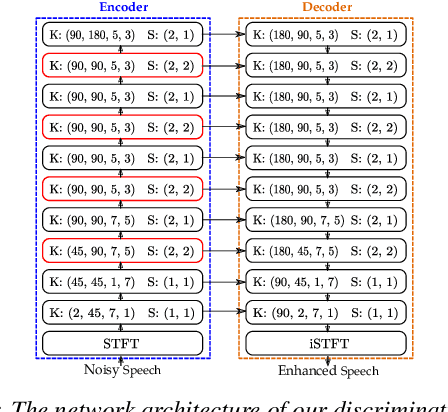



In this paper, we propose the coarse-to-fine optimization for the task of speech enhancement. Cosine similarity loss [1] has proven to be an effective metric to measure similarity of speech signals. However, due to the large variance of the enhanced speech with even the same cosine similarity loss in high dimensional space, a deep neural network learnt with this loss might not be able to predict enhanced speech with good quality. Our coarse-to-fine strategy optimizes the cosine similarity loss for different granularities so that more constraints are added to the prediction from high dimension to relatively low dimension. In this way, the enhanced speech will better resemble the clean speech. Experimental results show the effectiveness of our proposed coarse-to-fine optimization in both discriminative models and generative models. Moreover, we apply the coarse-to-fine strategy to the adversarial loss in generative adversarial network (GAN) and propose dynamic perceptual loss, which dynamically computes the adversarial loss from coarse resolution to fine resolution. Dynamic perceptual loss further improves the accuracy and achieves state-of-the-art results compared with other generative models.