 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchy of discriminative power and complexity in learning quantum ensembles
Jan 29, 2026Distance metrics are central to machine learning, yet distances between ensembles of quantum states remain poorly understood due to fundamental quantum measurement constraints. We introduce a hierarchy of integral probability metrics, termed MMD-$k$, which generalizes the maximum mean discrepancy to quantum ensembles and exhibit a strict trade-off between discriminative power and statistical efficiency as the moment order $k$ increases. For pure-state ensembles of size $N$, estimating MMD-$k$ using experimentally feasible SWAP-test-based estimators requires $Θ(N^{2-2/k})$ samples for constant $k$, and $Θ(N^3)$ samples to achieve full discriminative power at $k = N$. In contrast, the quantum Wasserstein distance attains full discriminative power with $Θ(N^2 \log N)$ samples. These results provide principled guidance for the design of loss functions in quantum machine learning, which we illustrate in the training quantum denoising diffusion probabilistic models.
RoofSeg: An edge-aware transformer-based network for end-to-end roof plane segmentation
Aug 26, 2025Roof plane segmentation is one of the key procedures for reconstructing three-dimensional (3D) building models at levels of detail (LoD) 2 and 3 from airborne light detection and ranging (LiDAR) point clouds. The majority of current approaches for roof plane segmentation rely on the manually designed or learned features followed by some specifically designed geometric clustering strategies. Because the learned features are more powerful than the manually designed features, the deep learning-based approaches usually perform better than the traditional approaches. However, the current deep learning-based approaches have three unsolved problems. The first is that most of them are not truly end-to-end, the plane segmentation results may be not optimal. The second is that the point feature discriminability near the edges is relatively low, leading to inaccurate planar edges. The third is that the planar geometric characteristics are not sufficiently considered to constrain the network training. To solve these issues, a novel edge-aware transformer-based network, named RoofSeg, is developed for segmenting roof planes from LiDAR point clouds in a truly end-to-end manner. In the RoofSeg, we leverage a transformer encoder-decoder-based framework to hierarchically predict the plane instance masks with the use of a set of learnable plane queries. To further improve the segmentation accuracy of edge regions, we also design an Edge-Aware Mask Module (EAMM) that sufficiently incorporates planar geometric prior of edges to enhance its discriminability for plane instance mask refinement. In addition, we propose an adaptive weighting strategy in the mask loss to reduce the influence of misclassified points, and also propose a new plane geometric loss to constrain the network training.
dots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.
Diversity-Aware Policy Optimization for Large Language Model Reasoning
May 29, 2025The reasoning capabilities of large language models (LLMs) have advanced rapidly, particularly following the release of DeepSeek R1, which has inspired a surge of research into data quality and reinforcement learning (RL) algorithms. Despite the pivotal role diversity plays in RL, its influence on LLM reasoning remains largely underexplored. To bridge this gap, this work presents a systematic investigation into the impact of diversity in RL-based training for LLM reasoning, and proposes a novel diversity-aware policy optimization method. Across evaluations on 12 LLMs, we observe a strong positive correlation between the solution diversity and Potential at k (a novel metric quantifying an LLM's reasoning potential) in high-performing models. This finding motivates our method to explicitly promote diversity during RL training. Specifically, we design a token-level diversity and reformulate it into a practical objective, then we selectively apply it to positive samples. Integrated into the R1-zero training framework, our method achieves a 3.5 percent average improvement across four mathematical reasoning benchmarks, while generating more diverse and robust solutions.
Diverse Policies Recovering via Pointwise Mutual Information Weighted Imitation Learning
Oct 21, 2024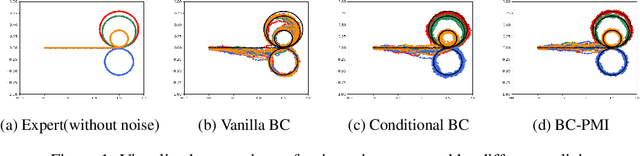
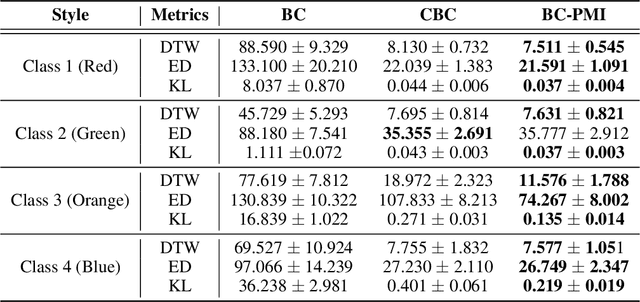
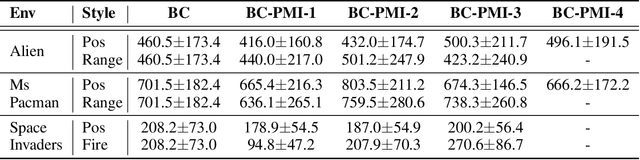
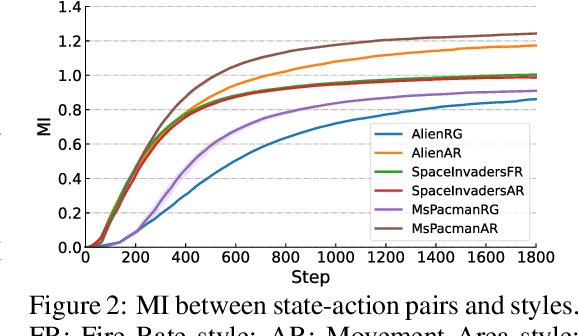
Recovering a spectrum of diverse policies from a set of expert trajectories is an important research topic in imitation learning. After determining a latent style for a trajectory, previous diverse policies recovering methods usually employ a vanilla behavioral cloning learning objective conditioned on the latent style, treating each state-action pair in the trajectory with equal importance. Based on an observation that in many scenarios, behavioral styles are often highly relevant with only a subset of state-action pairs, this paper presents a new principled method in diverse polices recovery. In particular, after inferring or assigning a latent style for a trajectory, we enhance the vanilla behavioral cloning by incorporating a weighting mechanism based on pointwise mutual information. This additional weighting reflects the significance of each state-action pair's contribution to learning the style, thus allowing our method to focus on state-action pairs most representative of that style. We provide theoretical justifications for our new objective, and extensive empirical evaluations confirm the effectiveness of our method in recovering diverse policies from expert data.
A boundary-aware point clustering approach in Euclidean and embedding spaces for roof plane segmentation
Sep 07, 2023Roof plane segmentation from airborne LiDAR point clouds is an important technology for 3D building model reconstruction. One of the key issues of plane segmentation is how to design powerful features that can exactly distinguish adjacent planar patches. The quality of point feature directly determines the accuracy of roof plane segmentation. Most of existing approaches use handcrafted features to extract roof planes. However, the abilities of these features are relatively low, especially in boundary area. To solve this problem, we propose a boundary-aware point clustering approach in Euclidean and embedding spaces constructed by a multi-task deep network for roof plane segmentation. We design a three-branch network to predict semantic labels, point offsets and extract deep embedding features. In the first branch, we classify the input data as non-roof, boundary and plane points. In the second branch, we predict point offsets for shifting each point toward its respective instance center. In the third branch, we constrain that points of the same plane instance should have the similar embeddings. We aim to ensure that points of the same plane instance are close as much as possible in both Euclidean and embedding spaces. However, although deep network has strong feature representative ability, it is still hard to accurately distinguish points near plane instance boundary. Therefore, we first group plane points into many clusters in the two spaces, and then we assign the rest boundary points to their closest clusters to generate final complete roof planes. In this way, we can effectively reduce the influence of unreliable boundary points. In addition, we construct a synthetic dataset and a real dataset to train and evaluate our approach. The experiments results show that the proposed approach significantly outperforms the existing state-of-the-art approaches.
Active Pose Refinement for Textureless Shiny Objects using the Structured Light Camera
Aug 28, 2023



6D pose estimation of textureless shiny objects has become an essential problem in many robotic applications. Many pose estimators require high-quality depth data, often measured by structured light cameras. However, when objects have shiny surfaces (e.g., metal parts), these cameras fail to sense complete depths from a single viewpoint due to the specular reflection, resulting in a significant drop in the final pose accuracy. To mitigate this issue, we present a complete active vision framework for 6D object pose refinement and next-best-view prediction. Specifically, we first develop an optimization-based pose refinement module for the structured light camera. Our system then selects the next best camera viewpoint to collect depth measurements by minimizing the predicted uncertainty of the object pose. Compared to previous approaches, we additionally predict measurement uncertainties of future viewpoints by online rendering, which significantly improves the next-best-view prediction performance. We test our approach on the challenging real-world ROBI dataset. The results demonstrate that our pose refinement method outperforms the traditional ICP-based approach when given the same input depth data, and our next-best-view strategy can achieve high object pose accuracy with significantly fewer viewpoints than the heuristic-based policies.
Policy Space Diversity for Non-Transitive Games
Jun 29, 2023



Policy-Space Response Oracles (PSRO) is an influential algorithm framework for approximating a Nash Equilibrium (NE) in multi-agent non-transitive games. Many previous studies have been trying to promote policy diversity in PSRO. A major weakness in existing diversity metrics is that a more diverse (according to their diversity metrics) population does not necessarily mean (as we proved in the paper) a better approximation to a NE. To alleviate this problem, we propose a new diversity metric, the improvement of which guarantees a better approximation to a NE. Meanwhile, we develop a practical and well-justified method to optimize our diversity metric using only state-action samples. By incorporating our diversity regularization into the best response solving in PSRO, we obtain a new PSRO variant, Policy Space Diversity PSRO (PSD-PSRO). We present the convergence property of PSD-PSRO. Empirically, extensive experiments on various games demonstrate that PSD-PSRO is more effective in producing significantly less exploitable policies than state-of-the-art PSRO variants.
A Lightweight Reconstruction Network for Surface Defect Inspection
Dec 25, 2022Currently, most deep learning methods cannot solve the problem of scarcity of industrial product defect samples and significant differences in characteristics. This paper proposes an unsupervised defect detection algorithm based on a reconstruction network, which is realized using only a large number of easily obtained defect-free sample data. The network includes two parts: image reconstruction and surface defect area detection. The reconstruction network is designed through a fully convolutional autoencoder with a lightweight structure. Only a small number of normal samples are used for training so that the reconstruction network can be A defect-free reconstructed image is generated. A function combining structural loss and $\mathit{L}1$ loss is proposed as the loss function of the reconstruction network to solve the problem of poor detection of irregular texture surface defects. Further, the residual of the reconstructed image and the image to be tested is used as the possible region of the defect, and conventional image operations can realize the location of the fault. The unsupervised defect detection algorithm of the proposed reconstruction network is used on multiple defect image sample sets. Compared with other similar algorithms, the results show that the unsupervised defect detection algorithm of the reconstructed network has strong robustness and accuracy.
* Journal of Mathematical Imaging and Vision(JMIV)
Self-supervised Amodal Video Object Segmentation
Oct 23, 2022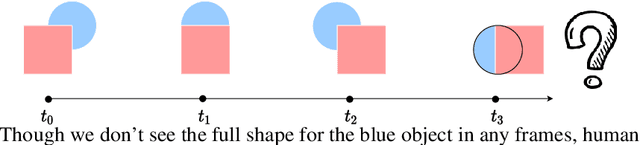
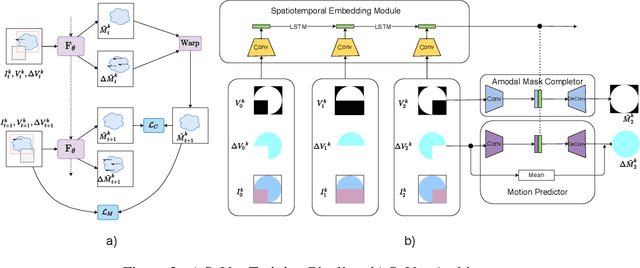
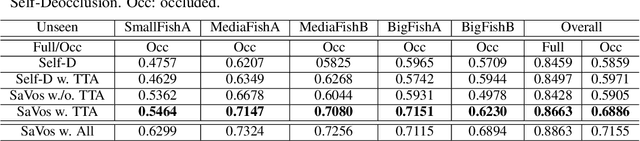

Amodal perception requires inferring the full shape of an object that is partially occluded. This task is particularly challenging on two levels: (1) it requires more information than what is contained in the instant retina or imaging sensor, (2) it is difficult to obtain enough well-annotated amodal labels for supervision. To this end, this paper develops a new framework of Self-supervised amodal Video object segmentation (SaVos). Our method efficiently leverages the visual information of video temporal sequences to infer the amodal mask of objects. The key intuition is that the occluded part of an object can be explained away if that part is visible in other frames, possibly deformed as long as the deformation can be reasonably learned. Accordingly, we derive a novel self-supervised learning paradigm that efficiently utilizes the visible object parts as the supervision to guide the training on videos. In addition to learning type prior to complete masks for known types, SaVos also learns the spatiotemporal prior, which is also useful for the amodal task and could generalize to unseen types. The proposed framework achieves the state-of-the-art performance on the synthetic amodal segmentation benchmark FISHBOWL and the real world benchmark KINS-Video-Car. Further, it lends itself well to being transferred to novel distributions using test-time adaptation, outperforming existing models even after the transfer to a new distribution.