 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen SAM Meets Sonar Images
Jun 25, 2023Segment Anything Model (SAM) has revolutionized the way of segmentation. However, SAM's performance may decline when applied to tasks involving domains that differ from natural images. Nonetheless, by employing fine-tuning techniques, SAM exhibits promising capabilities in specific domains, such as medicine and planetary science. Notably, there is a lack of research on the application of SAM to sonar imaging. In this paper, we aim to address this gap by conducting a comprehensive investigation of SAM's performance on sonar images. Specifically, we evaluate SAM using various settings on sonar images. Additionally, we fine-tune SAM using effective methods both with prompts and for semantic segmentation, thereby expanding its applicability to tasks requiring automated segmentation. Experimental results demonstrate a significant improvement in the performance of the fine-tuned SAM.
A Lightweight Reconstruction Network for Surface Defect Inspection
Dec 25, 2022Currently, most deep learning methods cannot solve the problem of scarcity of industrial product defect samples and significant differences in characteristics. This paper proposes an unsupervised defect detection algorithm based on a reconstruction network, which is realized using only a large number of easily obtained defect-free sample data. The network includes two parts: image reconstruction and surface defect area detection. The reconstruction network is designed through a fully convolutional autoencoder with a lightweight structure. Only a small number of normal samples are used for training so that the reconstruction network can be A defect-free reconstructed image is generated. A function combining structural loss and $\mathit{L}1$ loss is proposed as the loss function of the reconstruction network to solve the problem of poor detection of irregular texture surface defects. Further, the residual of the reconstructed image and the image to be tested is used as the possible region of the defect, and conventional image operations can realize the location of the fault. The unsupervised defect detection algorithm of the proposed reconstruction network is used on multiple defect image sample sets. Compared with other similar algorithms, the results show that the unsupervised defect detection algorithm of the reconstructed network has strong robustness and accuracy.
* Journal of Mathematical Imaging and Vision(JMIV)
IDMS: Instance Depth for Multi-scale Monocular 3D Object Detection
Dec 03, 2022Due to the lack of depth information of images and poor detection accuracy in monocular 3D object detection, we proposed the instance depth for multi-scale monocular 3D object detection method. Firstly, to enhance the model's processing ability for different scale targets, a multi-scale perception module based on dilated convolution is designed, and the depth features containing multi-scale information are re-refined from both spatial and channel directions considering the inconsistency between feature maps of different scales. Firstly, we designed a multi-scale perception module based on dilated convolution to enhance the model's processing ability for different scale targets. The depth features containing multi-scale information are re-refined from spatial and channel directions considering the inconsistency between feature maps of different scales. Secondly, so as to make the model obtain better 3D perception, this paper proposed to use the instance depth information as an auxiliary learning task to enhance the spatial depth feature of the 3D target and use the sparse instance depth to supervise the auxiliary task. Finally, by verifying the proposed algorithm on the KITTI test set and evaluation set, the experimental results show that compared with the baseline method, the proposed method improves by 5.27\% in AP40 in the car category, effectively improving the detection performance of the monocular 3D object detection algorithm.
* Journal of Machine Learning Research
Pedestrian Spatio-Temporal Information Fusion For Video Anomaly Detection
Nov 28, 2022



Aiming at the problem that the current video anomaly detection cannot fully use the temporal information and ignore the diversity of normal behavior, an anomaly detection method is proposed to integrate the spatiotemporal information of pedestrians. Based on the convolutional autoencoder, the input frame is compressed and restored through the encoder and decoder. Anomaly detection is realized according to the difference between the output frame and the true value. In order to strengthen the characteristic information connection between continuous video frames, the residual temporal shift module and the residual channel attention module are introduced to improve the modeling ability of the network on temporal information and channel information, respectively. Due to the excessive generalization of convolutional neural networks, in the memory enhancement modules, the hopping connections of each codec layer are added to limit autoencoders' ability to represent abnormal frames too vigorously and improve the anomaly detection accuracy of the network. In addition, the objective function is modified by a feature discretization loss, which effectively distinguishes different normal behavior patterns. The experimental results on the CUHK Avenue and ShanghaiTech datasets show that the proposed method is superior to the current mainstream video anomaly detection methods while meeting the real-time requirements.
* International Conference on Intelligent Media, Big Data and Knowledge Mining
Data Augmentation Vision Transformer for Fine-grained Image Classification
Nov 24, 2022Recently, the vision transformer (ViT) has made breakthroughs in image recognition. Its self-attention mechanism (MSA) can extract discriminative labeling information of different pixel blocks to improve image classification accuracy. However, the classification marks in their deep layers tend to ignore local features between layers. In addition, the embedding layer will be fixed-size pixel blocks. Input network Inevitably introduces additional image noise. To this end, we study a data augmentation vision transformer (DAVT) based on data augmentation and proposes a data augmentation method for attention cropping, which uses attention weights as the guide to crop images and improve the ability of the network to learn critical features. Secondly, we also propose a hierarchical attention selection (HAS) method, which improves the ability of discriminative markers between levels of learning by filtering and fusing labels between levels. Experimental results show that the accuracy of this method on the two general datasets, CUB-200-2011, and Stanford Dogs, is better than the existing mainstream methods, and its accuracy is 1.4\% and 1.6\% higher than the original ViT, respectively
* IEEE Signal Processing Letters
Efficient Unsupervised Video Object Segmentation Network Based on Motion Guidance
Nov 21, 2022Due to the problem of performance constraints of unsupervised video object detection, its large-scale application is limited. In response to this pain point, we propose another excellent method to solve this problematic point. By incorporating motion characterization in unsupervised video object detection, detection accuracy is improved while reducing the computational amount of the network. The whole network structure consists of dual-stream network, motion guidance module, and multi-scale progressive fusion module. The appearance and motion representations of the detection target are obtained through a dual-stream network. Then, the semantic features of the motion representation are obtained through the local attention mechanism in the motion guidance module to obtain the high-level semantic features of the appearance representation. The multi-scale progressive fusion module then fuses the features of different deep semantic features in the dual-stream network further to improve the detection effect of the overall network. We have conducted numerous experiments on the three datasets of DAVIS 16, FBMS, and ViSal. The verification results show that the proposed method achieves superior accuracy and performance and proves the superiority and robustness of the algorithm.
* The 10th International Conference on Information Systems and Computing Technology
Spatio-Temporal-based Context Fusion for Video Anomaly Detection
Oct 18, 2022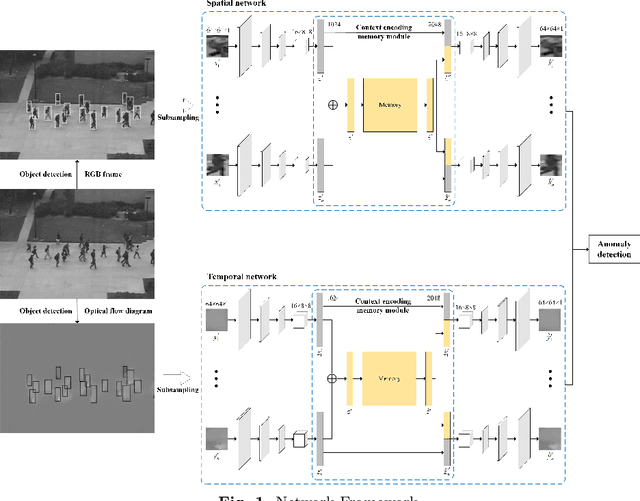
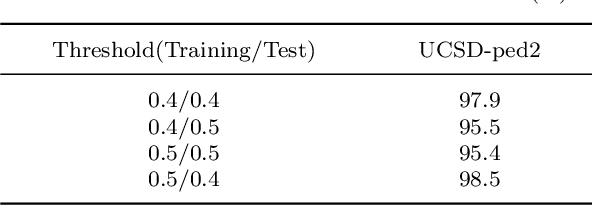
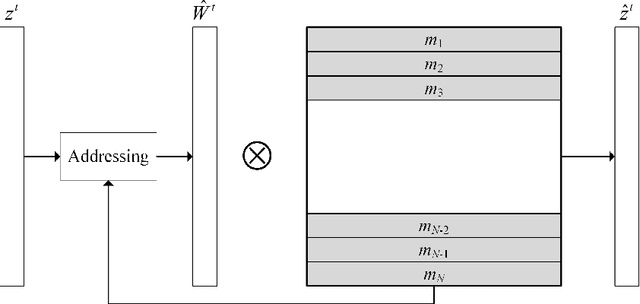
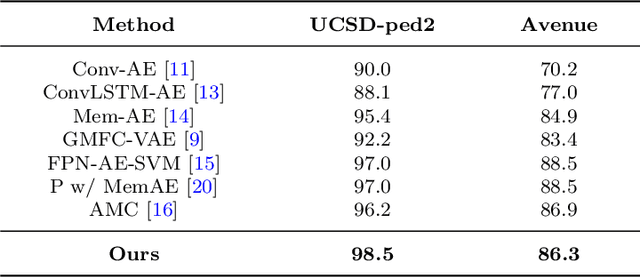
Video anomaly detection aims to discover abnormal events in videos, and the principal objects are target objects such as people and vehicles. Each target in the video data has rich spatio-temporal context information. Most existing methods only focus on the temporal context, ignoring the role of the spatial context in anomaly detection. The spatial context information represents the relationship between the detection target and surrounding targets. Anomaly detection makes a lot of sense. To this end, a video anomaly detection algorithm based on target spatio-temporal context fusion is proposed. Firstly, the target in the video frame is extracted through the target detection network to reduce background interference. Then the optical flow map of two adjacent frames is calculated. Motion features are used multiple targets in the video frame to construct spatial context simultaneously, re-encoding the target appearance and motion features, and finally reconstructing the above features through the spatio-temporal dual-stream network, and using the reconstruction error to represent the abnormal score. The algorithm achieves frame-level AUCs of 98.5% and 86.3% on the UCSDped2 and Avenue datasets, respectively. On the UCSDped2 dataset, the spatio-temporal dual-stream network improves frames by 5.1% and 0.3%, respectively, compared to the temporal and spatial stream networks. After using spatial context encoding, the frame-level AUC is enhanced by 1%, which verifies the method's effectiveness.
Reliable Identification of Redundant Kernels for Convolutional Neural Network Compression
Dec 10, 2018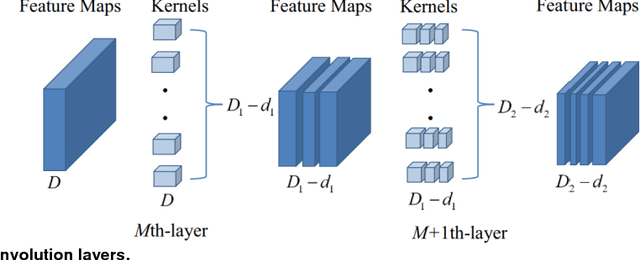
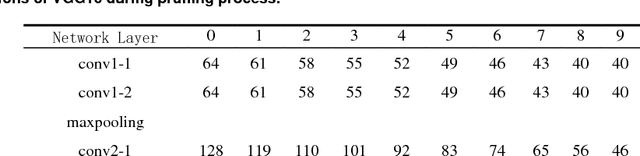


To compress deep convolutional neural networks (CNNs) with large memory footprint and long inference time, this paper proposes a novel pruning criterion using layer-wised Ln-norm of feature maps. Different from existing pruning criteria, which are mainly based on L1-norm of convolution kernels, the proposed method utilizes Ln-norm of output feature maps after non-linear activations, where n is a variable, increasing from 1 at the first convolution layer to inf at the last convolution layer. With the ability of accurately identifying unimportant convolution kernels, the proposed method achieves a good balance between model size and inference accuracy. The experiments on ImageNet and the successful application in railway surveillance system show that the proposed method outperforms existing kernel-norm-based methods and is generally applicable to any deep neural network with convolution operations.