 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Reconstruction Network for Surface Defect Inspection
Dec 25, 2022Currently, most deep learning methods cannot solve the problem of scarcity of industrial product defect samples and significant differences in characteristics. This paper proposes an unsupervised defect detection algorithm based on a reconstruction network, which is realized using only a large number of easily obtained defect-free sample data. The network includes two parts: image reconstruction and surface defect area detection. The reconstruction network is designed through a fully convolutional autoencoder with a lightweight structure. Only a small number of normal samples are used for training so that the reconstruction network can be A defect-free reconstructed image is generated. A function combining structural loss and $\mathit{L}1$ loss is proposed as the loss function of the reconstruction network to solve the problem of poor detection of irregular texture surface defects. Further, the residual of the reconstructed image and the image to be tested is used as the possible region of the defect, and conventional image operations can realize the location of the fault. The unsupervised defect detection algorithm of the proposed reconstruction network is used on multiple defect image sample sets. Compared with other similar algorithms, the results show that the unsupervised defect detection algorithm of the reconstructed network has strong robustness and accuracy.
* Journal of Mathematical Imaging and Vision(JMIV)
Data Augmentation Vision Transformer for Fine-grained Image Classification
Nov 24, 2022Recently, the vision transformer (ViT) has made breakthroughs in image recognition. Its self-attention mechanism (MSA) can extract discriminative labeling information of different pixel blocks to improve image classification accuracy. However, the classification marks in their deep layers tend to ignore local features between layers. In addition, the embedding layer will be fixed-size pixel blocks. Input network Inevitably introduces additional image noise. To this end, we study a data augmentation vision transformer (DAVT) based on data augmentation and proposes a data augmentation method for attention cropping, which uses attention weights as the guide to crop images and improve the ability of the network to learn critical features. Secondly, we also propose a hierarchical attention selection (HAS) method, which improves the ability of discriminative markers between levels of learning by filtering and fusing labels between levels. Experimental results show that the accuracy of this method on the two general datasets, CUB-200-2011, and Stanford Dogs, is better than the existing mainstream methods, and its accuracy is 1.4\% and 1.6\% higher than the original ViT, respectively
* IEEE Signal Processing Letters
Spatio-Temporal-based Context Fusion for Video Anomaly Detection
Oct 18, 2022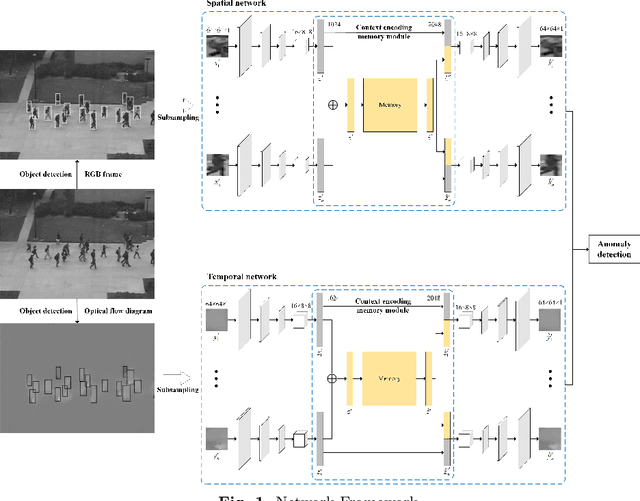
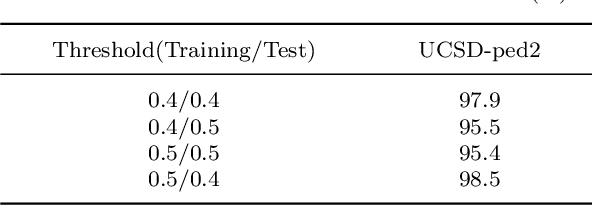
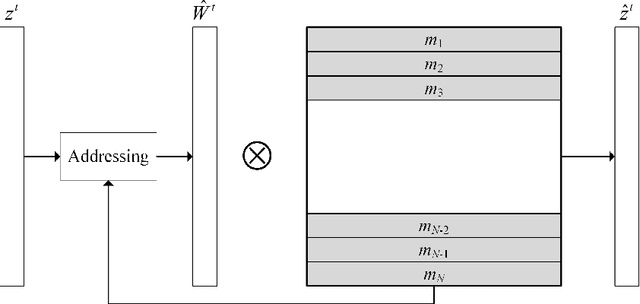
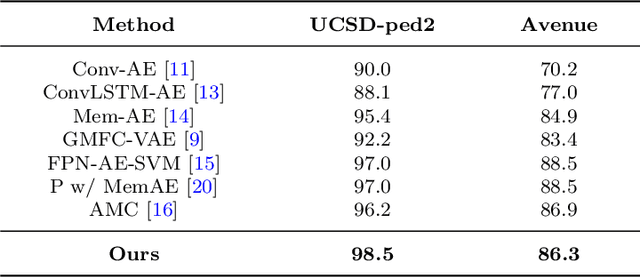
Video anomaly detection aims to discover abnormal events in videos, and the principal objects are target objects such as people and vehicles. Each target in the video data has rich spatio-temporal context information. Most existing methods only focus on the temporal context, ignoring the role of the spatial context in anomaly detection. The spatial context information represents the relationship between the detection target and surrounding targets. Anomaly detection makes a lot of sense. To this end, a video anomaly detection algorithm based on target spatio-temporal context fusion is proposed. Firstly, the target in the video frame is extracted through the target detection network to reduce background interference. Then the optical flow map of two adjacent frames is calculated. Motion features are used multiple targets in the video frame to construct spatial context simultaneously, re-encoding the target appearance and motion features, and finally reconstructing the above features through the spatio-temporal dual-stream network, and using the reconstruction error to represent the abnormal score. The algorithm achieves frame-level AUCs of 98.5% and 86.3% on the UCSDped2 and Avenue datasets, respectively. On the UCSDped2 dataset, the spatio-temporal dual-stream network improves frames by 5.1% and 0.3%, respectively, compared to the temporal and spatial stream networks. After using spatial context encoding, the frame-level AUC is enhanced by 1%, which verifies the method's effectiveness.
Normal Learning in Videos with Attention Prototype Network
Aug 25, 2021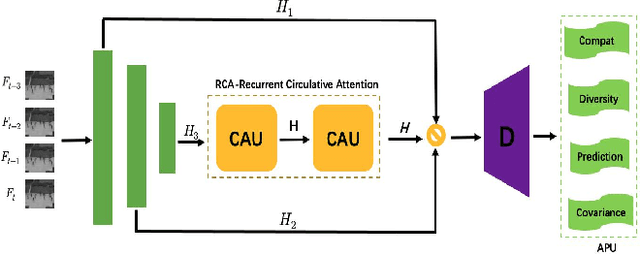
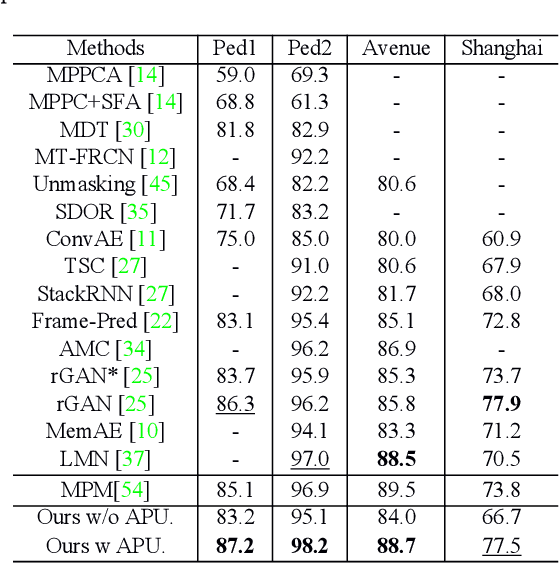
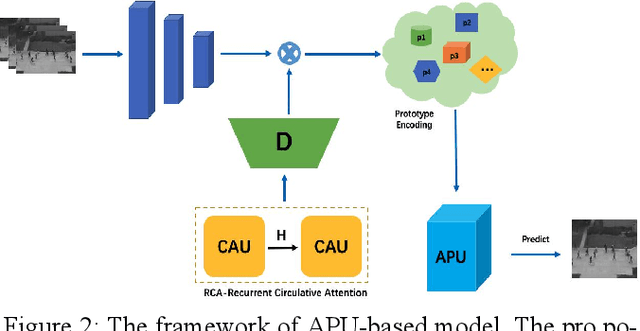
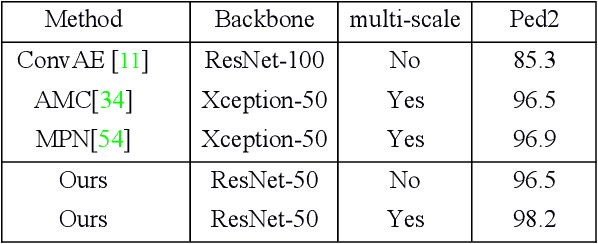
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a self-attention prototype unit (APU) to encode the normal latent space as prototypes in real time, free from extra memory cost. In addition, we introduce circulative attention mechanism to our backbone to form a novel feature extracting learner, namely Circulative Attention Unit (CAU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method. Our code is available at https://github.com/huchao-AI/APN/.